场景介绍
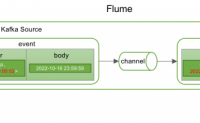
在大数据业务采集场景中,经常会通过Flume把Kafka中的数据落地到HDFS进行持久保存和数据计算。为了数据计算和运维方便,通常会把每天的数据在HDFS通过天分区独立存储。
在数据落入HDFS 天分区目录的过程中,会出现数据跨天存储的问题,本来是2022年6月16日的...
2年前 (2022-10-18) 1823℃
2喜欢
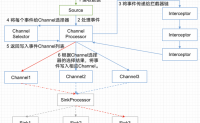
Flume 内部原理
本文主要使用其中的Interceptor和Channel Selector
Interceptor:
对source中的数据在进入channel之前进行拦截做一些处理,比如过滤掉一些数据,或者加上一些key/value等。flume内置了一些拦截器,也可以...
2年前 (2022-10-18) 1742℃
1喜欢