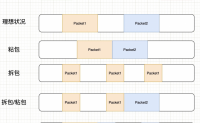
为什么会有粘包拆包?
TCP 是个”流”协议,所谓流,就是没有界限的一串数据。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被拆分成多个包进行发送,也有可能把多个小的包封装成一个大...
2年前 (2022-11-07) 2686℃
1喜欢
介绍
Netty作为一个基础的NIO通信框架,被广泛应用于大数据处理、互联网消息中间件等场景。这些应用场景都是分布式场景,总结就是把一个服务的不同角色在分散在不同的服务器上。各个角色在运行过程中都需要通过Netty进行数据或者参数的传递,这个过程一定离不开网络。可以把网络理解成联...
2年前 (2022-11-07) 1208℃
0喜欢
Netty介绍
官网:https://netty.io/
Netty是一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。
Netty 本质是一个 NIO 框架,适用于服务器通讯相关的多种应用场景。
Netty解决的问题是:以非常轻松的方式解决各种各...
2年前 (2022-11-07) 1294℃
0喜欢
前言
数据倾斜是大数据计算中一个最棘手的问题,出现数据倾斜后,Spark 作业的性能会比期望值差很多,两大直接后果:Spark 任务 OOM 异常退出和数据倾斜拖慢整个任务的执行。数据倾斜的调优,就是利用各种技术方案解决不同类型的数据倾斜问题,保证 Spark 作业的性能。
导致...
2年前 (2022-10-31) 1116℃
4喜欢
前言
输出这篇文章,至少参考了五个不同的spark优化文档,删除了不少调整不调整感觉对性能变化没啥用的内容,查漏补缺总结了如下十二条spark性能调优内容,感觉总结的也是相当全了。
调优一:资源配置
Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分...
2年前 (2022-10-29) 1130℃
0喜欢
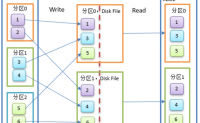
Spark Shuffle的演进过程
Spark最初版本HashShuffle。
Spark 0.8.1版本以后优化后的HashShuffle。
Spark1.1版本加入SortShuffle,默认是HashShuffle。
Spark1.2版本默认是SortShuffle,但是...
2年前 (2022-10-29) 6789℃
0喜欢
介绍
Spark是基于内存的分布式计算引擎,其内置强大的内存管理机制,保证数据优先内存处理,并支持数据磁盘存储。
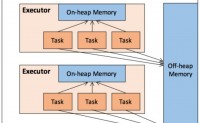
在执行Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 S...
2年前 (2022-10-29) 5947℃
0喜欢
介绍
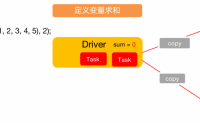
一般情况下,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量被复制到每台机器上,并且这些变量在远程机器上 的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是...
2年前 (2022-10-29) 1382℃
0喜欢
依赖关系
血缘关系介绍
多个连续的RDD的依赖关系,称之为血缘关系,通过RDD的血缘关系,就可以构建出DAG 有向无环图。
RDD为了提高容错性,需要将RDD间的关系保存下来,一旦出现错误,可以根据血缘关系将数据源重新读取进行计算。
查看血缘关系
任意转换算子使用 toDebug...
2年前 (2022-10-27) 2922℃
2喜欢
介绍
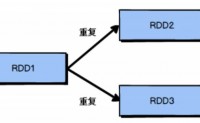
持久化的作用,供RDD的重复使用,针对计算耗时比较长,可以提高计算的效率,针对数据比较重要的数据保存到持久化中,数据的安全性也可以得到保障。
持久化操作是在行动算子执行时完成的。
注意:RDD中不存储数据,如果一个RDD需要重复使用,那么需要从头再次执行来获取数据,RD...
2年前 (2022-10-27) 5924℃
0喜欢