前言
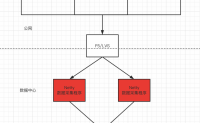
本文主要通过Netty实现一个Http协议的数据采集服务,并将Netty接收的请求转换成消息发送给Kafka:
关于采集程序的几个规则:
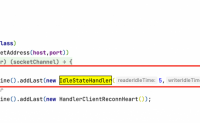
1、Netty判断请求的合规性通过request header中携带的key和value进行判断,没有携带指定key和value的req...
2年前 (2022-11-12) 1518℃
1喜欢
介绍
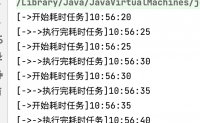
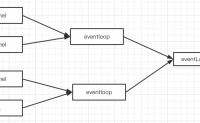
Netty不光可以处理IO流任务,还可以处理普通任务和定时任务
Netty通过两种方式提供异步的普通任务和定时任务:
(1)通过Channel的EventLoop实现普通任务和定时任务;
(2)通过EventExecutorGroup实现普通任务和定时任务。
两者区别:...
2年前 (2022-11-11) 6978℃
0喜欢
介绍
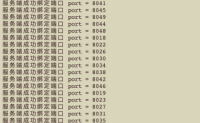
做个小案例,使用Netty实现单机百万连接。
说明:此案例仅供娱乐。生产不建议单机连接太多,生产环境单机有个一两万连接就了不得了,因为一旦服务器故障,这么多的连接分摊到其他服务器处理不当可能会雪崩,就算其他服务器可以接收这么多连接,那么用户的断线重连,也挺闹心的。
明确瓶颈...
2年前 (2022-11-08) 3643℃
0喜欢
编解码技术介绍
基于Netty的NIO网络开发,我们关注的重点之一是网络传输。当进行远程跨进程服务调用时,需要把被传输的Java对象编码为字节数组或者ByteBuffer对象。而当远程服务读取到ByteBuffer对象或者字节数组时,需要将其编码为发送时的Java对象。这被称为J...
2年前 (2022-11-07) 1546℃
0喜欢
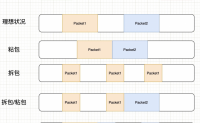
为什么会有粘包拆包?
TCP 是个”流”协议,所谓流,就是没有界限的一串数据。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被拆分成多个包进行发送,也有可能把多个小的包封装成一个大...
2年前 (2022-11-07) 2628℃
1喜欢
介绍
Netty作为一个基础的NIO通信框架,被广泛应用于大数据处理、互联网消息中间件等场景。这些应用场景都是分布式场景,总结就是把一个服务的不同角色在分散在不同的服务器上。各个角色在运行过程中都需要通过Netty进行数据或者参数的传递,这个过程一定离不开网络。可以把网络理解成联...
2年前 (2022-11-07) 1156℃
0喜欢
Netty介绍
官网:https://netty.io/
Netty是一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。
Netty 本质是一个 NIO 框架,适用于服务器通讯相关的多种应用场景。
Netty解决的问题是:以非常轻松的方式解决各种各...
2年前 (2022-11-07) 1224℃
0喜欢
对象的实例化
对象创建的方式
1、new:最常见的方式、单例类中调用getInstance的静态类方法,XXXFactory的静态方法
2、Class的newInstance方法:在JDK9里面被标记为过时的方法,因为只能调用空参构造器,并且权限必须为 public
3、Cons...
2年前 (2022-10-20) 902℃
1喜欢
概述
我们希望能描述这样一类对象:当内存空间还足够时,则能保留在内存中;如果内存空间在进行垃圾收集后还是很紧张,则可以抛弃这些对象。
针对这个需求在JDK1.2版之后,Java对引用的概念进行了扩充,将引用分为:
强引用(Strong Reference)
软引用(Soft R...
2年前 (2022-10-20) 1017℃
1喜欢
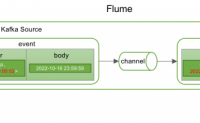
场景介绍
在大数据业务采集场景中,经常会通过Flume把Kafka中的数据落地到HDFS进行持久保存和数据计算。为了数据计算和运维方便,通常会把每天的数据在HDFS通过天分区独立存储。
在数据落入HDFS 天分区目录的过程中,会出现数据跨天存储的问题,本来是2022年6月16日的...
2年前 (2022-10-18) 1821℃
2喜欢