简介
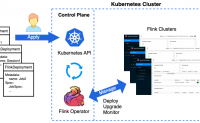
我们在实际使用flink的过程中,不仅使用java开发flink作业,同时也会直接使用flink SQL,通过编写SQL的方式,来实现flink作业。本文就基于Flink 官方提供的 Kubernetes Operator,来实现flink sql在k8s上的运行。
程序功...
2年前 (2023-05-29) 2133℃
2喜欢
Flink HistoryServer用途
HistoryServer可以在Flink 作业终止运行(Flink集群关闭)之后,还可以查询已完成作业的统计信息。此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,Jo...
2年前 (2023-05-29) 2010℃
4喜欢
简介
无论是我们自己开发的系统,还是各种中间件,高可用部署可以避免单点故障,是生产运行的必备要求。对于flink作业也一样,我们开发好的flink 作业,部署到生产环境,也需要高可用的方式来运行。
Flink的高可用,指的就是job manager的高可用,默认情况下,每个 Fl...
2年前 (2023-05-29) 6131℃
2喜欢
简介
大家都知道,Flink 是一个有状态的分布式流式计算引擎,flink 中的每个function或者是operator都可以是有状态的,为了使得状态可以容错,flink引入了checkpoint机制。checkpoint使得flink能够恢复作业的状态和位置,从而为作业提供与...
2年前 (2023-05-29) 2526℃
3喜欢
简介
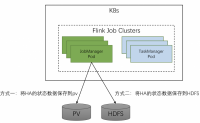
之前部署了flink operator,并将spark 作业提交到了k8s之上,但是也仅仅达到了能用的程度,距离生产落地还有一些内容需要调整。
Flink 作业日志持久化
当flink运行出错的时候,或者我们要分析flink运行状态的时候,运行日志是我们排查问题的重要依据。...
2年前 (2023-05-29) 102℃
6喜欢
简介
Flink Kubernetes Operator是一个用于在Kubernetes集群上部署、管理和自动化运行Apache Flink应用程序的开源项目。它提供了一种简单、可靠且可扩展的方式来部署和管理Flink作业,同时实现高可用性和容错性。
Flink Kubernet...
2年前 (2023-05-29) 2263℃
2喜欢
前言
在JDK 19中提供了一个非常重要的新特性就是虚拟线程,虚拟线程 换成go语言就是对应的协程
为什么需要虚拟线程
为什么要虚拟线程,它到底解决了什么问题?
这就要涉及到标准的普通线程了
要知道在我们操作系统层面上,要进行高并发的程序处理,都要创建一个一个普通的线程,而这个线...
2年前 (2023-05-17) 6697℃
0喜欢
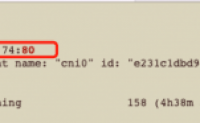
问题描述
K8S 集群,新安装了nginx服务器,但是访问80端口出来的服务不对,关闭nginx后,仍然可以访问服务器的80端口,但是本地80端口并没有任何服务监听。因为是K8S节点,所以怀疑是K8S上配置了转发规则导致。
解决办法
1、查看端口转发规则:K8S服务器上可能存在端...
2年前 (2023-05-17) 1609℃
1喜欢
简介
Iceberg 的优势有以下几点:
1、增量数据更新:Iceberg 可以支持增量数据更新,而不是全量数据覆盖,从而减少了数据更新的时间和成本。
2、事务管理:Iceberg 支持事务管理,可以确保数据的一致性和可靠性。
3、版本管理:Iceberg 支持版本管理,可以方便...
2年前 (2023-04-28) 4979℃
1喜欢
简介
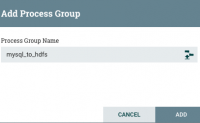
nifi 是一个数据同步的框架,像是flume和datax可以完成的操作,nifi都可以完成,本文展示了两个nifi的实际案例,来学习nifi的使用。
案例一:使用nifi离线同步mysql数据到hdfs,模拟datax的常用场景
案例二:使用nifi实时监控Kafka数据...
2年前 (2023-04-27) 1464℃
1喜欢