1.Memcached介绍
Memcache是一套开源,高性能的分布式的内存对象缓存系统,目前被许多网站使用以提高网站的访问速度,尤其是一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著。
1.1.Memcached对比redis
个人认为:Memcached和redis最大的区别就是两点,一个是redis数据类型比较丰富,二是redis支持持久化。感觉目前memcached在大部分中小公司的实际应用中主要就是用来存储session,其他的内存数据都是使用redis,使用memcached比较多的都是一些大型的互联网公司。
Memcached和redis对比引用某DBA的一句话:
大家一般都认为redis性能优于memcached,可以说是正确的,但是另一方面也可以说是不正确的。 原因是它们两各有特点,只是特点不同,应用场景就不同,表现优劣势有一定差异,按道理不同场景优劣势就没有可比性。 比如,redis支持丰富的数据类型,而memcached没有数据类型,那么到底谁是更具优势呢? 如果仅仅是数据比较小的简单堆表,那么memcached的内存使用效率可能更高一些,而redis内存效率综合可能要比memcached差一些。 另一方面,redis为什么要设计数据类型,这是出于充分利用内存考虑的,所以redis查询需要注意优化规则,如充分使用hash表,那么数据压缩和紧凑,内存效率可能就比memcached更高一些。 否则可能效率就会比memcached差一些。 这也是为什么memcached在大型网站中用于session会话的存储,而redis常用于其它相对比较大的数据缓存,比如图片的缓存等等,实际上关于session缓存也有不同看法的。 总之,特点不同,应用场景就不同,优劣势就没有可对性。
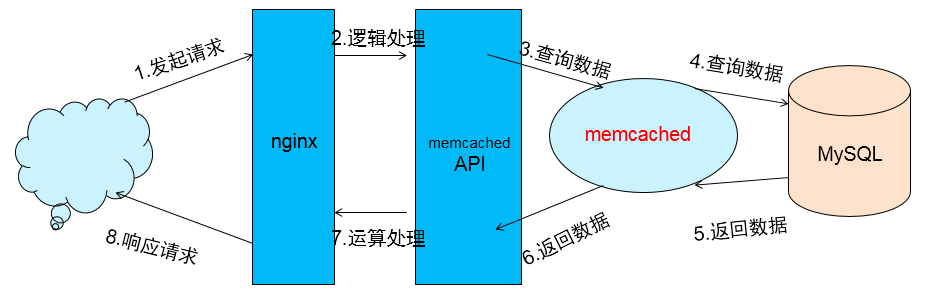
1.2.Memcached架构
下图是memcached用来做数据缓存层面的架构图:
1.3.Memcached的特点
memcached的特点: 1、基于C/S架构,协议简单 2、基于libevent架构(libevent是一套跨平台的事件处理接口的封装。能兼容多个操作系统的事件处理。) 基于libevent事件处理有什么好处? (1)跨平台 (2)大并发下,快速响应能力 3、基于客户端的分布式 (1)分布式实现不是在服务器端实现的,而是客户端实现的。 (2)多个memcached服务器是独立的 (3)分布式数据如何存储由路由算法决定 4、内存存储 (1)内存存储数据的优点:访问速度快、分布式读取数据解决高并发读写效率问题 (2)memcached有自己的存储方式和数据过期方式
1.4.memcached如何存储数据的
(1)memcached有自己的存储方式和数据过期方式
数据存储方式:Slab Allocation
数据过期方式:LRU,Laxzy Expiration
(2)什么是slab allocation
Slab allocation涵义:意思是按组分配内存。
(1)每次先分配一个slab,相当于一个page,大小1M
(2)然后在1M的空间里根据内容在划分相同大小的chunk

(3)slab allocation分配内存的优缺点
优点:很好的避免内存碎片问题
缺点:可能浪费内存
(4)数据过期方式
1、Lazy Expiration
memcached内部不监视数据是否过期,而是get时查看记录时间,检查是否已经过期,这叫惰性过期。
2、LRU:追加数据空间不足时,根据LRU情况来淘汰最近最少使用记录
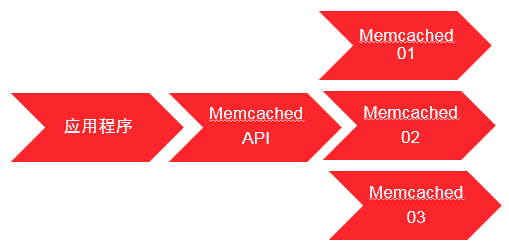
2.Memcached缓存路由策略
Memcached是分布式缓存数据库,当他有数据写入的时候,他应该把数据写入到后端的那个节点呢?这就由memcached路由策略决定。
Memcached缓存的原理:
(1)程序写入缓存数据请求
(2)API将key输入路由算法模块路由到集群中一台机器
(3)API与服务器通信,完成一次分布式缓存写入
2.1.求余数hash算法
Memcached它的数据只有一种类型,那就是键值对数据,除了键和值之外,没有其他形式的数据,我们应用程序传入键的时候,会做如下运算。
1.先用key做hash运算得到一个整数,比如hash(‘xmfb)=10,服务器数量是3
2.做hash运算,根据余数路由。
10%3=1,那么就路由到第2台服务器。
9%3=0,那么路由到第1台服务器
8%3=2,那么路由到第3台服务器
3.优点:数据分布均衡在多台服务器中,适合大多数据需求。
缺点之一:不考虑热点数据
求余数hash算法的不足1
原来 三台服务器:
10%3=1,那么就路由到第2台服务器。
9%3=0,那么路由到第1台服务器
8%3=2,那么路由到第3台服务器
问题:如果需要扩容怎么办?
如扩容一台服务器,变成4台服务器
10%4=2 路由到第3台
9%4=1 路由到第2台
8%4=0 路由到第1台
结果:全不命中
后果:呵呵了
求余数hahs算法的不足2
如果其中一台DOWN机怎么办?
原来 三台服务器:
10%3=1,那么就路由到第2台服务器。
9%3=0,那么路由到第1台服务器
8%3=2,那么路由到第3台服务器
问题:如果其中一台DOWN机怎么办?
如扩容一台服务器,变成2台服务器
10%2=0 路由到第1台
9%2=1 路由到第2台
8%2=0 路由到第1台
结果:全不命中
后果:呵呵了
2.2.一致性hash
一致性hash算法可以最小化减少memcached集群扩容或down机场景,对热点数据的影响。
以下是简化算法模型:
1.假设hash后的整数为1至1000。
2.环上1至1000首尾相接形成一个闭合的循环。假设
(1)key1=1,node1=330
(2)key2=331,node2=660
(3)key3=661,node3=1000
(4)>1000,按照循环从下一个节点查找也就是node1节点

一致性hash算法下扩容
扩容一台服务器:
1.扩容前: k3=661,node3=1000
2.扩容后:范围661-1000约被拆成对半
k4=661,node4=830,顺时针到最近node4查询
k3=831,node3=1000,顺时针到最近的node3查询
3.原来的key1,key2范围不受影响
只是影响key3范围的一部分
一致性hash算法,在扩容时只影响了一小部分缓存,集群扩容越大,不命中的影响就会越小
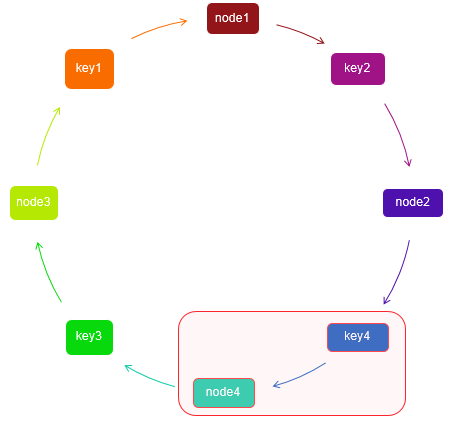
一致性hash算法下down机
第3台服务器发生故障前后:
1.前: k3=661,node3=1000
2.后:k3=661,node1=330 顺时针到最近node1查询
3.原来的key1,key2范围不受影响
只是影响原来key3的范围
一致性hash算法,在发生故障时只影响了一小部分缓存,集群扩容越大,不命中的影响就会越小

3.Memcached分布式架构介绍
1.分布式实现不是在服务器端实现的,而是客户端实现的。
2.多个memcached服务器是独立的
3.分布式数据如何存储由路由算法决定
4.其中一台memcached 发生故障了,怎么办?后果是什么?
应用程序无法在memcached中查找到数据,就会到后端数据库进行数据查询,如果后端服务器承载不了大负载,就会导致业务不可用,甚至发生故障。这时我们就需要评估一台memcached发生故障,我们不能接受这种影响,我们就必须想办法实现memcached高可用。

4.Memcached部署
(1)安装memcached依赖libevent
[root@node1 ~]# yum -y install libevent libevent-devel
(2)安装c语言编译环境
[root@node1 ~]# yum -y install c++ gcc
(3)编译安装memcached
wget http://www.memcached.org/files/memcached-1.4.33.tar.gz tar xf memcached-1.4.33.tar.gz cd memcached-1.4.33/ ./configure --prefix=/usr/local/memcached make && make install
memcached安装完成目录结构如下所示:
[root@node1 memcached-1.4.33]# tree /usr/local/memcached/
/usr/local/memcached/
├── bin
│ └── memcached
├── include
│ └── memcached
│ └── protocol_binary.h
└── share
└── man
└── man1
└── memcached.1
优化memcached命令路径
[root@node1 ~]# cat /etc/profile.d/memcached.sh #!/bin/bash export PATH=/usr/local/memcached/bin:$PATH [root@node1 ~]# source /etc/profile.d/memcached.sh
创建memcached启动用户:
[root@node1 ~]# useradd -r -s /sbin/nologin memcached
启动memcached,memcached启动之后监听11211端口
[root@node1 ~]# memcached -u memcached -m 512 -d [root@node1 ~]# ps uax | grep memcached memcach+ 5424 0.1 0.0 323124 860 ? Ssl 23:02 0:00 memcached -u memcached -m 512 –d [root@node1 ~]# netstat -lntp | grep mem tcp 0 0 0.0.0.0:11211 0.0.0.0:* LISTEN 5424/memcached
memcached启动参数说明: -m 最大内存大小,默认为64MB -p 使用的TCP端口,默认为11211 -d 作为守护进程在后台运行 -u 运行memcache的用户,默认不能有root用户启动,所以当前用户为root用户时,需要使用-u参数来指定 -P 设置保存memcache的pid文件 -c最大支持的并发连接数,默认为1024; -vv 以very vrebose模式启动,调试信息和错误输出到控制台 行的并发连接数,默认是1024,按照服务器的负载量设定 -l 监听的服务器IP地址,如果 -t :用于处理入站请求的最大线程数,仅在memcached编译时开启了支持线程才有效; -f :设定Slab Allocator定义预先分配内存空间大小固定的块时使用的增长因子; -M:当内存空间不够使用时返回错误信息,而不是按LRU算法利用空间; -n: 指定最小的slab chunk大小;单位是字节; -S: 启用sasl进行用户认证;
添加memcached启动脚本:
[root@node1 ~]# cat /usr/local/memcached/memcached_service.sh
#!/bin/bash
cmd="/usr/local/memcached/bin/memcached"
start(){
$cmd -d -m 512 -u memcached;
}
stop(){
killall memcached;
}
act=$1
case $act in
'start')
start;;
'stop')
stop;;
'restart')
stop
sleep 2
start;;
*)
echo '[start|stop|restart]';;
esac
[root@node1 ~]# chmod 755 /usr/local/memcached/memcached_service.sh
应用程序把memcached应用起来就需要调用memcached的API库,不同语言环境安装方式不同,这里不在提供。
5.Memcached数据库操作
使用telnet连接操作memcached:
[root@node1 ~]# telnet 127.0.0.1 11211
1.命令格式
参数解释:
command name:命令名称,比如执行插入插入就是add,查询操作就是get。
key:建的名称
flags:标记,存储额外的信息
exptime:过期时间,为0表示永不过期,为1表示1秒钟之后过期
bytes:字节数
data clock:建的值,也就是存储的数据
示例:
add username 0 0 4
xmfb
2.如何插入一条键值数据?
add username 0 0 4
xmfb
3.如何更新一条键值数据?
set username 0 0 12
ximenfeibing
replace username 0 0 4
xmfb
4.如何查询键值数据?
get username
gets username
5.如何清除一条缓存数据?
delete username
删除一条键值为usernmame的缓存数据
6.检查后更新 check and set
gets username
cas username 0 0 4 1
xmfb
如果cas的最后一个更新因子数与gets返回的更新因子数相等,则更新。否则返回exists
7.如何追加数据?
append username 0 0 4 #后追加
xmfb
prepend username 0 0 12 #前追加
ximenfeibing
8.如何清除所有缓存数据?
flush_all
9.如何查看服务器统计信息
stats
stats items 返回所有键值对统计信息
stats cachedump 1 0 返回指定存储空间的键值对
stats slabs 显示各个slab的信息,包括chunk的大小、数目、使用情况等
stats sizes 输出所有item的大小和个数
stats reset 清空统计数据
转载请注明:西门飞冰的博客 » memcached分布式路由算法介绍及部署