1.ELKstack简介
ELKstack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合而成,形成一款强大的实时日志收集展示系统。
各组件作用如下:
Logstash:日志收集工具,可以从本地磁盘,网络服务(自己监听端口,接受用户日志),消息队列中收集各种各样的日志,然后进行过滤分析,并将日志输入到Elasticsearch中。
Elasticsearch:日志分布式存储/搜索工具,原生支持集群功能,可以将指定时间的日志生成一个索引,加快日志查询和访问。
Kibana:可视化日志web展示工具,对Elasticsearch中存储的日志进行展示,还可以生成炫丽的仪表盘。
2.使用ELKstack对运维工作的好处:
1、应用程序的日志大部分都是输出在服务器的日志文件中,这些日志大多是开发人员来看,然后开发却没有登录服务器的权限,如果开发人员需要查看日志就需要运维到服务器来拿日志,然后交给开发;试想下,一个公司有10个开发,一个开发每天找运维那一次日志,对运维来说就是一个不小的工作量,这样大大影响了运维的工作效率,部署ELKstack之后,开发人员就可以直接登录kibana中进行日志的查看,就不需要通过运维查看日志,这样就减轻了运维的工作。
2、日志种类多,且分散在不同的位置难以查找:如LAMP/LNMP网站出现访故障,这个时候可能就需要通过查询日志来进行分析故障原因,如果需要查看apache的错误日志,就需要登录到Apache服务器查看,如果查看数据库错误日志就需要登录到数据库查询,实现下如果是一个集群环境几十台主机呢?这时如果部署了ELKstack就可以登录到kibana页面进行查看日志,查看不同类型的日志只需要点点鼠标切换一下索引即可。
3.ELK实验架构图
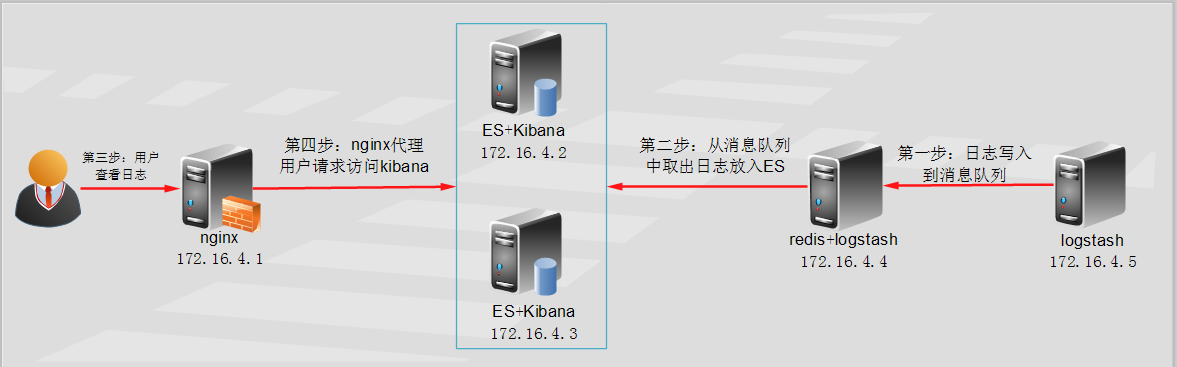
redis消息队列作用说明:
1、防止logstash和Es无法正常通信,从而丢失日志
2、防止日志量过大导致ES无法承受大量写操作从而丢失日志
3、应用程序(php,java)在输出日志时,可以直接输出到消息队列,从而完成日志收集
补充:如果redis使用的消息队列出现扩展瓶颈,可以使用更加强大的kafka,flume来代替。
实验环境说明:
[root@node1 ~]# cat /etc/redhat-release CentOS release 6.6 (Final) [root@node1 ~]# uname -rm 2.6.32-504.el6.x86_64 x86_64
使用软件说明:
logstash-1.5.4.tar.gz
elasticsearch-1.7.2.tar.gz
kibana-4.1.2-linux-x64.tar.gz
nginx和redis均为yum安装
部署顺序:
1、Elasticsearch集群配置
2、Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志)
3、Redis消息队列配置(logstash写入数据到消息队列)
4、Kibana部署
5、nginx负载均衡kibana请求
6、案例:同时收集nginx和MySQL慢查询日志
7、kibana报表功能说明
配置需要注意的事项:
1、时间必须同步
2、出了问题,检查日志
4.Elasticsearch集群安装配置
(1)配置java环境,且版本为8,如果使用7可能会出现警告信息
[root@ES1 ~]# yum -y install java-1.8.0 [root@ES1 ~]# java -version openjdk version "1.8.0_51" OpenJDK Runtime Environment (build 1.8.0_51-b16) OpenJDK 64-Bit Server VM (build 25.51-b03, mixed mode)
(2)下载elasticsearch,可以使用我直接给出的地址也可以直接去官方下载最新版,官方地址在文章结尾有给出。
wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.tar.gz
(3)安装elasticsearch,安装过程很简单,只需要把软件解压到指定目录,然后做一个软链接即可
tar xf elasticsearch-1.7.2.tar.gz mv elasticsearch-1.7.2 /usr/local/ cd /usr/local/ ln -s /usr/local/elasticsearch-1.7.2/ /usr/local/elasticsearch
(4)修改配置文件,这里的一些路径就看自己的习惯了,推荐将数据目录放到ssd硬盘加快检索速度
[root@ES1 ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml 32 cluster.name: elasticsearch #组播的名称地址 40 node.name: "linux-ES1" #节点名称,不能和其他节点重复 47 node.master: true #节点能否被选举为master 51 node.data: true #节点是否存储数据 107 index.number_of_shards: 5 #索引分片的个数 111 index.number_of_replicas: 1 #分片的副本个数 145 path.conf: /usr/local/elasticsearch/config/ #配置文件的路径 149 path.data: /data/es-data #数据目录路径 159 path.work: /data/es-worker #工作目录路径 163 path.logs: /usr/local/elasticsearch/logs/ #日志文件路径 167 path.plugins: /usr/local/elasticsearch/plugins #插件路径 184 bootstrap.mlockall: true #内存不向swap交换
(5)创建相关目录
mkdir /data/es-data -p mkdir /data/es-worker -p mkdir /usr/local/elasticsearch/logs mkdir /usr/local/elasticsearch/plugins
(6)安装启动脚本
由于是使用的tar包安装的ES,默认是没有启动脚本的,如果不愿意自己手动些启动脚本,可以根据如下步骤安装
git clone https://github.com/elastic/elasticsearch-servicewrapper.git cd elasticsearch-servicewrapper/ mv service/ /usr/local/elasticsearch/bin/ /usr/local/elasticsearch/bin/service/elasticsearch install
修改服务配置文件
[root@ES1 ~]# vim /usr/local/elasticsearch/bin/service/elasticsearch.conf set.default.ES_HOME=/usr/local/elasticsearch #设置ES的安装路径,必须和安装路径保持一直 set.default.ES_HEAP_SIZE=1024 #设置分配jvm内存大小
(7)启动ES,并检查是否监听9200和9300端口是否正常监听
[root@ES1 ~]# /etc/init.d/elasticsearch start [root@ES1 ~]# netstat -lntp | grep -E "9200|9300" tcp 0 0 :::9300 :::* LISTEN 37416/java tcp 0 0 :::9200 :::* LISTEN 37416/java
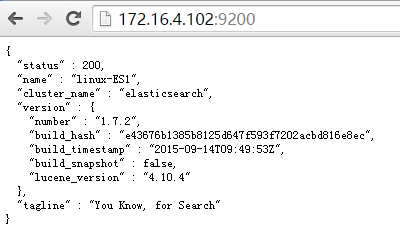
访问9200端口,检查节点是否正常
5.补充:ES2节点配置
配置时只需要保证elasticsearch.yml文件中,node.name和node1节点不同即可,其他步骤都是一样的
[root@ES2 ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml 40 node.name: "linux-ES2" #节点名称,不能和其他节点重复
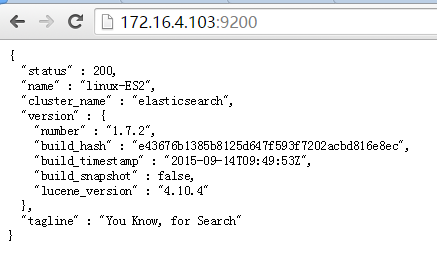
这里我已经配置好了ES2节点
6.配置集群管理插件(head)
官方提供了一个ES集群管理插件,可以非常直观的查看ES的集群状态和索引数据信息,安装方法如下所示:
[root@ES1 ~]# /usr/local/elasticsearch/bin/plugin -i mobz/elasticsearch-head
安装完成,访问安装head插件的ES服务器,后缀如下图所示,即可查看集群信息,由于还没有向ES中写入数据,所以ES可能还看不到有索引,写入数据后就可以在此页面 看到ES存储的日志信息了
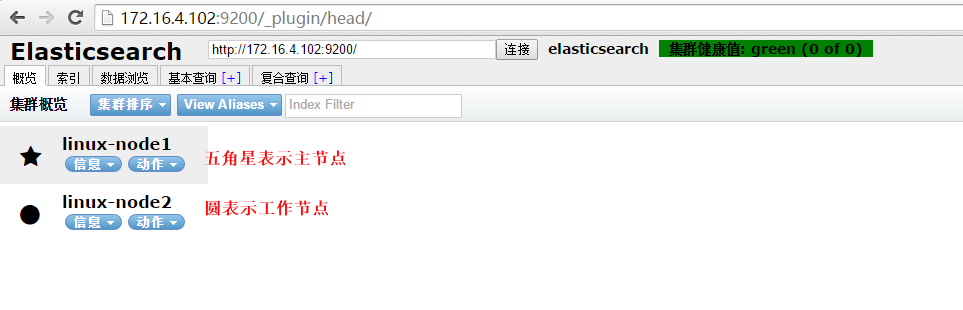
这个时候ES集群就配置完成了,下面就可以配置logstash向ES集群中写入数据了。
7.Logstash部署
(1)下载logstash
wget https://download.elastic.co/logstash/logstash/logstash-1.5.4.tar.gz
(2)部署logstash需要java环境
yum -y install java-1.8.0 tar zxf logstash-1.5.4.tar.gz mv logstash-1.5.4 /usr/local/ ln -s /usr/local/logstash-1.5.4/ /usr/local/logstash
(3)设置启动脚本,在/etc/init.d/logstash中添加如下内容即可, 脚本中给出的logstash配置文件为/etc/logstash如果有需要请手动修改。
#!/bin/sh
# Init script for logstash
# Maintained by Elasticsearch
# Generated by pleaserun.
# Implemented based on LSB Core 3.1:
# * Sections: 20.2, 20.3
#
### BEGIN INIT INFO
# Provides: logstash
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description:
# Description: Starts Logstash as a daemon.
### END INIT INFO
PATH=/sbin:/usr/sbin:/bin:/usr/bin
export PATH
if [ `id -u` -ne 0 ]; then
echo "You need root privileges to run this script"
exit 1
fi
name=logstash
pidfile="/var/run/$name.pid"
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
LS_USER=logstash
LS_GROUP=logstash
LS_HOME=/usr/local/logstash
LS_HEAP_SIZE="500m"
LS_JAVA_OPTS="-Djava.io.tmpdir=${LS_HOME}"
LS_LOG_DIR=/usr/local/logstash
LS_LOG_FILE="${LS_LOG_DIR}/$name.log"
LS_CONF_FILE=/etc/logstash.conf
LS_OPEN_FILES=16384
LS_NICE=19
LS_OPTS=""
[ -r /etc/default/$name ] && . /etc/default/$name
[ -r /etc/sysconfig/$name ] && . /etc/sysconfig/$name
program=/usr/local/logstash/bin/logstash
args="agent -f ${LS_CONF_FILE} -l ${LS_LOG_FILE} ${LS_OPTS}"
start() {
JAVA_OPTS=${LS_JAVA_OPTS}
HOME=${LS_HOME}
export PATH HOME JAVA_OPTS LS_HEAP_SIZE LS_JAVA_OPTS LS_USE_GC_LOGGING
# set ulimit as (root, presumably) first, before we drop privileges
ulimit -n ${LS_OPEN_FILES}
# Run the program!
nice -n ${LS_NICE} sh -c "
cd $LS_HOME
ulimit -n ${LS_OPEN_FILES}
exec \"$program\" $args
" > "${LS_LOG_DIR}/$name.stdout" 2> "${LS_LOG_DIR}/$name.err" &
# Generate the pidfile from here. If we instead made the forked process
# generate it there will be a race condition between the pidfile writing
# and a process possibly asking for status.
echo $! > $pidfile
echo "$name started."
return 0
}
stop() {
# Try a few times to kill TERM the program
if status ; then
pid=`cat "$pidfile"`
echo "Killing $name (pid $pid) with SIGTERM"
kill -TERM $pid
# Wait for it to exit.
for i in 1 2 3 4 5 ; do
echo "Waiting $name (pid $pid) to die..."
status || break
sleep 1
done
if status ; then
echo "$name stop failed; still running."
else
echo "$name stopped."
fi
fi
}
status() {
if [ -f "$pidfile" ] ; then
pid=`cat "$pidfile"`
if kill -0 $pid > /dev/null 2> /dev/null ; then
# process by this pid is running.
# It may not be our pid, but that's what you get with just pidfiles.
# TODO(sissel): Check if this process seems to be the same as the one we
# expect. It'd be nice to use flock here, but flock uses fork, not exec,
# so it makes it quite awkward to use in this case.
return 0
else
return 2 # program is dead but pid file exists
fi
else
return 3 # program is not running
fi
}
force_stop() {
if status ; then
stop
status && kill -KILL `cat "$pidfile"`
fi
}
case "$1" in
start)
status
code=$?
if [ $code -eq 0 ]; then
echo "$name is already running"
else
start
code=$?
fi
exit $code
;;
stop) stop ;;
force-stop) force_stop ;;
status)
status
code=$?
if [ $code -eq 0 ] ; then
echo "$name is running"
else
echo "$name is not running"
fi
exit $code
;;
restart)
stop && start
;;
reload)
stop && start
;;
*)
echo "Usage: $SCRIPTNAME {start|stop|force-stop|status|restart}" >&2
exit 3
;;
esac
exit $?
添加为系统服务
[root@client elk-config]# chkconfig --add logstash [root@client elk-config]# chkconfig logstash on [root@client elk-config]# chkconfig --list logstash logstash 0:off 1:off 2:on 3:on 4:on 5:on 6:off
(4)Logstash向Elasticsearch写入数据
1、设置一个logstash配置文件
[root@client elk]# cat /etc/logstash.conf
input { #表示从标准输入中收集日志
stdin {}
}
output {
elasticsearch { #表示将日志输出到ES中
host => ["172.16.4.102:9200","172.16.4.103:9200"] #可以指定多台主机,也可以指定集群中的单台主机
protocol => "http"
}
}
2、手动启动logstash并写入数据
[root@client elk]# /usr/local/logstash/bin/logstash -f /etc/logstash.conf Logstash startup completed hello world #这里是自己手动写入的内容
3、写入完成之后,查看ES中已经写入数据,并且自动建立了一个索引
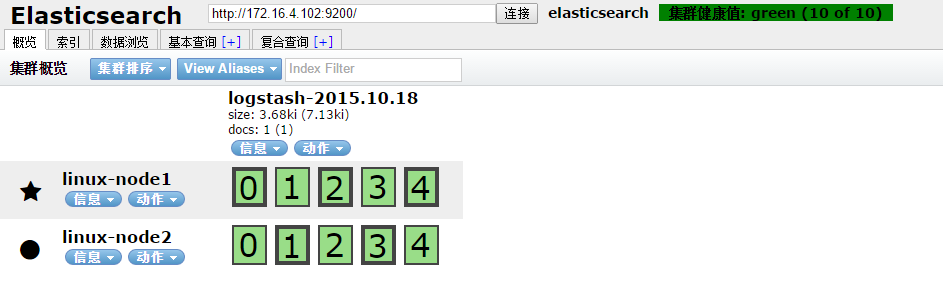
在基本查询选项中选择指定的索引就可以看到写入的日志内容
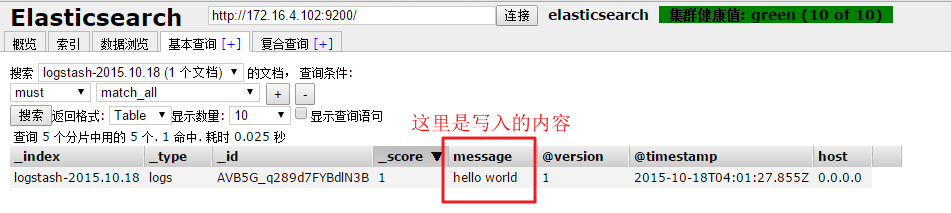
这个时候说明,logstash结合elasticsearch是可以正常工作的,下面就以一个实际例子还说明如何,收集系统日志。
8.Logstash收集系统日志
修改logstash配置文件为如下所示内容,并启动logstash服务就可以在head中看到messages的日志已经写入到了ES中,并且创建了索引
[root@node5 ~]# vim /etc/logstash.conf
input {
file { #表示从文件中读取日志
path => "/var/log/messages" #文件路径
start_position => "beginning" #表示从文件开始处(第一行)读取日志进行收集
}
}
output {
elasticsearch { #表示输出到ES中
host => ["172.16.4.102:9200","172.16.4.103:9200"]
protocol => "http"
index => "system-messages-%{+YYYY-MM}" #表示创建的索引名称,%{+YYYY-MM}表示安装日期创建索引,这是指定日期格式
}
}
收集成功如下图所示,自动生成了system-messages的索引
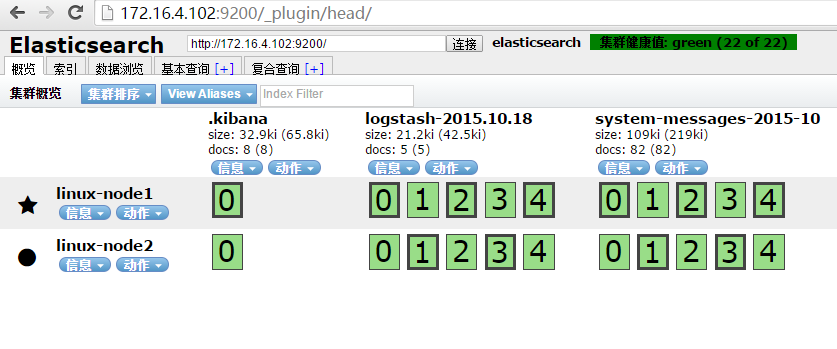
logstash结合elasticsearch 写入日志没有问题的话,下一步就是logstash向redis中写入日志,当然如果日志的写入量不是很高,也可以不需要使用消息队列,直接使用logstash向elasticsearch 写入日志。
9.Redis消息队列配置
(1)安装redis,没有特殊需求使用yum安装即可
[root@redis ~]# yum -y install redis
(2)配置redis:redis默认是监听127.0.0.1,是不允许其他主机访问的,如果允许其他主机访问就需要配置监听外部ip地址或者0.0.0.0。
[root@redis ~]# vim /etc/redis.conf bind 0.0.0.0
(3)启动redis
[root@redis ~]# /etc/init.d/redis start [root@node4 ~]# netstat -lntp | grep redis tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 36660/redis-server
(4)收集系统日志写入到redis中
[root@client ~]# cat /etc/logstash.conf
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
redis { #表示写入到redis中
host => "172.16.4.104" #指明redis服务器地址
data_type => "list" #指定数据类型为list
key => "system-messages" #指定存入的键
}
}
设置完成,重启logstash服务,登录redis查询是否写入
redis 127.0.0.1:6379> KEYS * #查看redis中的键,已经创建了一个system-messages的键
1) "system-messages"
redis 127.0.0.1:6379> TYPE system-messages #查询键的类型为list
list
redis 127.0.0.1:6379> LINDEX system-messages -1 #查询键的值
"{\"message\":\"Oct 18 13:55:56 config-03 yum[38732]: Installed: zsh-4.3.11-4.el6.centos.x86_64\",\"@version\":\"1\",\"@timestamp\":\"2015-10-18T06:57:54.581Z\",\"host\":\"0.0.0.0\",\"path\":\"/var/log/messages\",\"type\":\"system\"}"
注意:由于这里还没有使用logstash从redis中取出数据,所以这里是可以看到消息队列中的数据,如果是生产环境,可能使用KEYS *看不到消息队列中有数据,说明logstash已经从消息队列中取走了数据。
(5)从redis读取日志写入到ES
说明:此logstash我部署在redis服务器上,当然也可以部署在ES上,或者其他机器上看个人需求了
[root@node4 ~]# cat /etc/logstash.conf
input {
redis { #表示从redis中取出数据
host => "172.16.4.104"
data_type => "list"
key => "system-messages" #指定去system-messages这个键中取出数据
}
}
output {
elasticsearch {
host => ["172.16.4.102:9200","172.16.4.103:9200"]
protocol => "http"
index => "system-messages-%{+YYYY-MM}"
}
}
此处配置完成之后,就已经完成了日志的收集以及存储的配置,那么就剩下WEB展示的配置了,只需要部署完成kibana就可以实现最后的日志展示功能。
10.Kibana部署
说明:我这里是在两个ES节点部署kibana并且使用nginx实现负载均衡,如果没有特殊的需求可以只部署单台节点
(1)安装kibana,每个ES节点部署一个
tar zxf kibana-4.1.2-linux-x64.tar.gz mv kibana-4.1.2-linux-x64 /usr/local/ cd /usr/local/ ln -s kibana-4.1.2-linux-x64/ kibana
(2)配置kibana,只需要指定ES地址其他配置保持默认即可。
[root@node2 ~]# vim /usr/local/kibana/config/kibana.yml elasticsearch_url: http://172.16.4.102:9200 #指定elasticsearch地址,各自ES节点的kibana指向各自节点ES
(3)添加kibana启动脚本
#!/bin/bash
#chkconfig:35 13 91
#description:this is kibana servers
. /etc/rc.d/init.d/functions
start(){
/usr/local/kibana/bin/kibana >/dev/null 2>&1 &
if [ `ps -ef | grep -v grep | grep "kibana" | wc -l` -gt 0 ];then
action "starting kibana:" /bin/true
sleep 1
else
action "starting kibana:" /bin/false
sleep 1
fi
}
stop(){
kibanapid=`ps aux | grep "kibana" | grep -v grep | awk '{print $2}'`
kill -9 $kibanapid
if [ `ps -ef | grep -v grep | grep "kibana" | wc -l` -lt 1 ];then
action "stopping kibana:" /bin/true
sleep 1
else
action "stopping kibana:" /bin/false
sleep 1
fi
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
$0 stop;
$0 start;
;;
*)
echo $"Usage: $0 {start|stop|restart}"
;;
esac
添加到系统服务:
[root@ES1 local]# chmod +x /etc/init.d/kibana [root@ES1 local]# chkconfig --add kibana [root@ES1 local]# chkconfig kibana on [root@ES1 local]# chkconfig --list kibana kibana 0:off 1:off 2:on 3:on 4:on 5:on 6:off
(4)启动kibana并登录web页面创建系统日志索引,并查询日志
1、启动kibana,并检查是否监听5601端口
[root@ES1 local]# /etc/init.d/kibana start starting kibana: [ OK ] [root@ES1 local]# netstat -lntp | grep 5601 tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 40660/node
2、登录web页面,直接访问kibana的5601端口即可
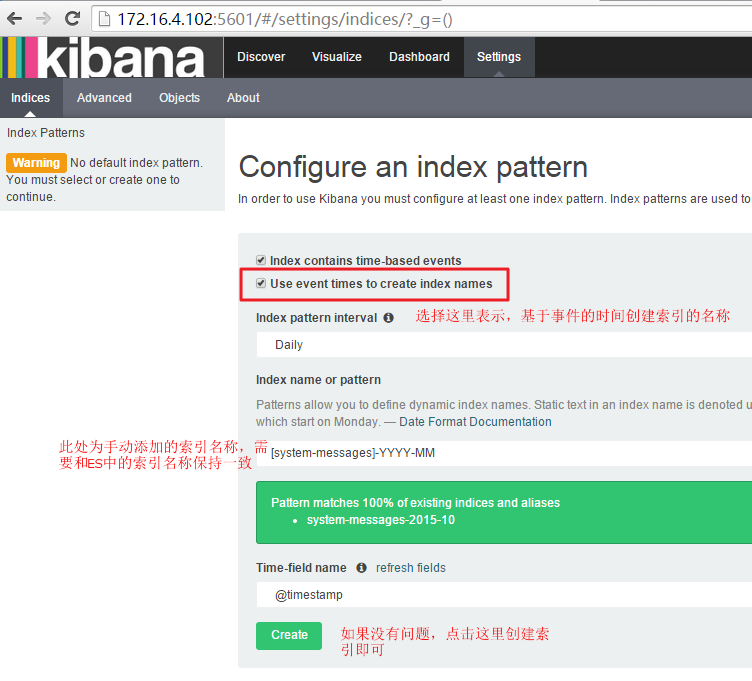
配置完成之后就可以在Discover中看到写入的日志
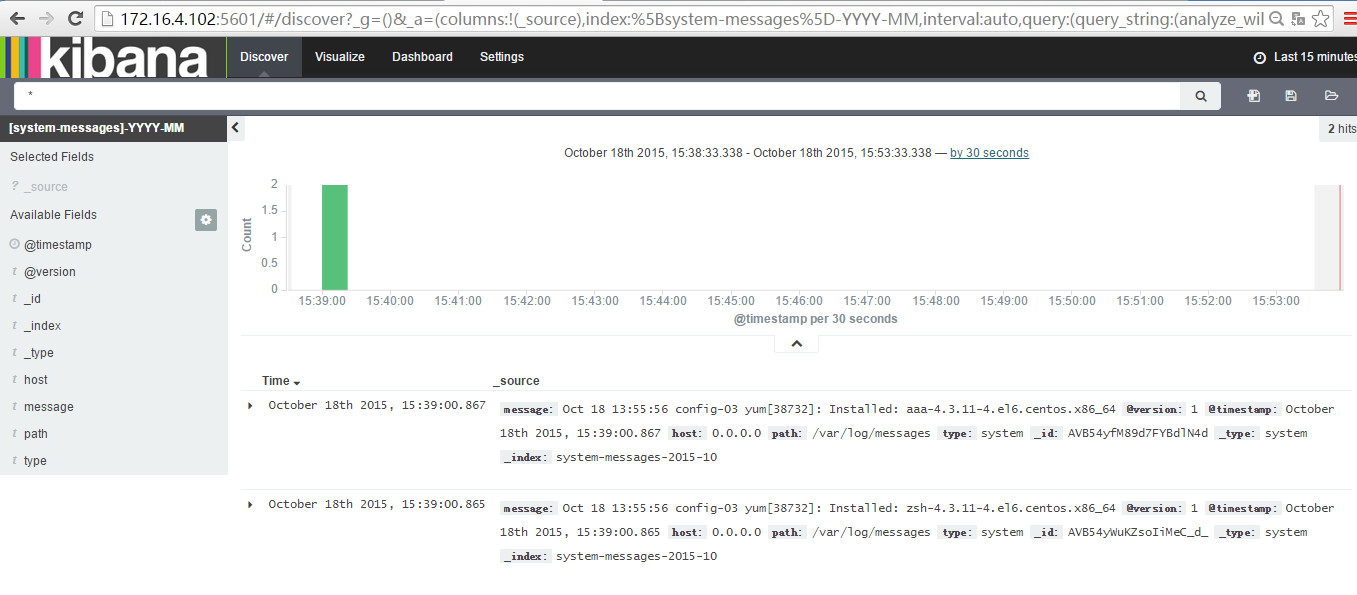
查询指定字段的日志,如选择侧边栏的messages点击add就可以只查询messages字段的日志了
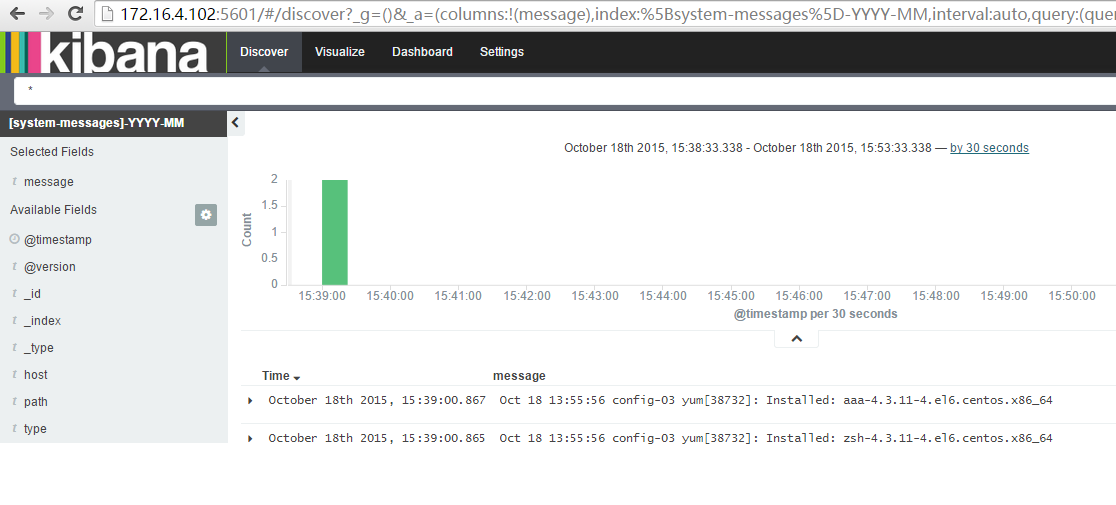
还可以根据时间查询日志,如下中文显示是我使用网页翻译显示的
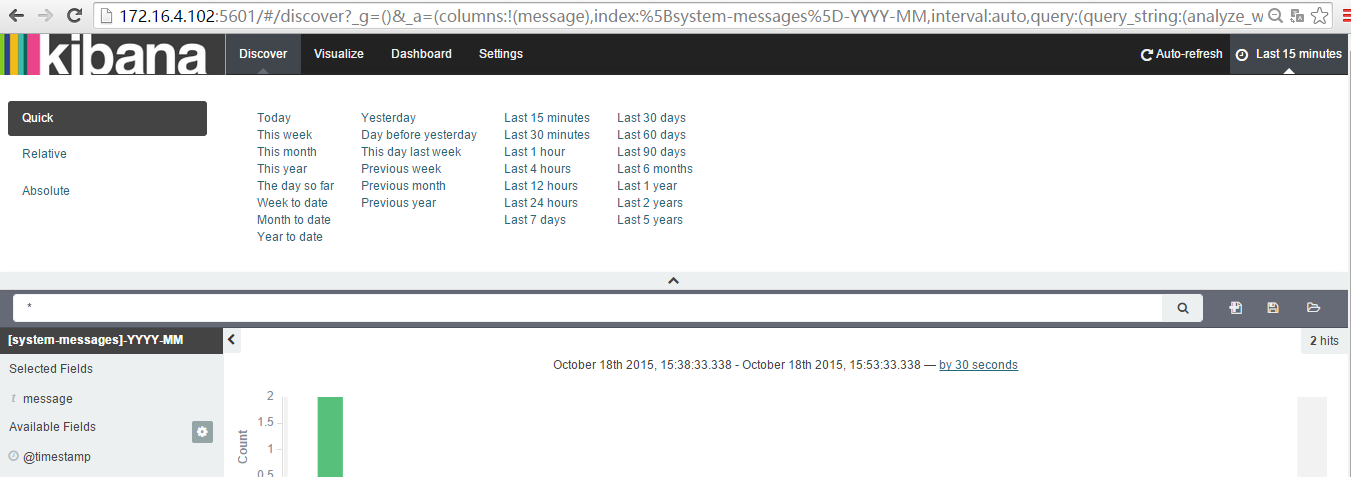
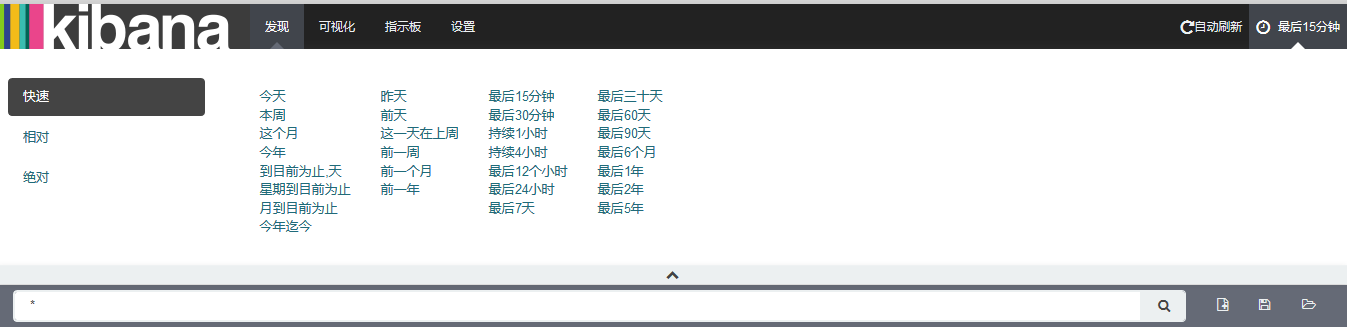
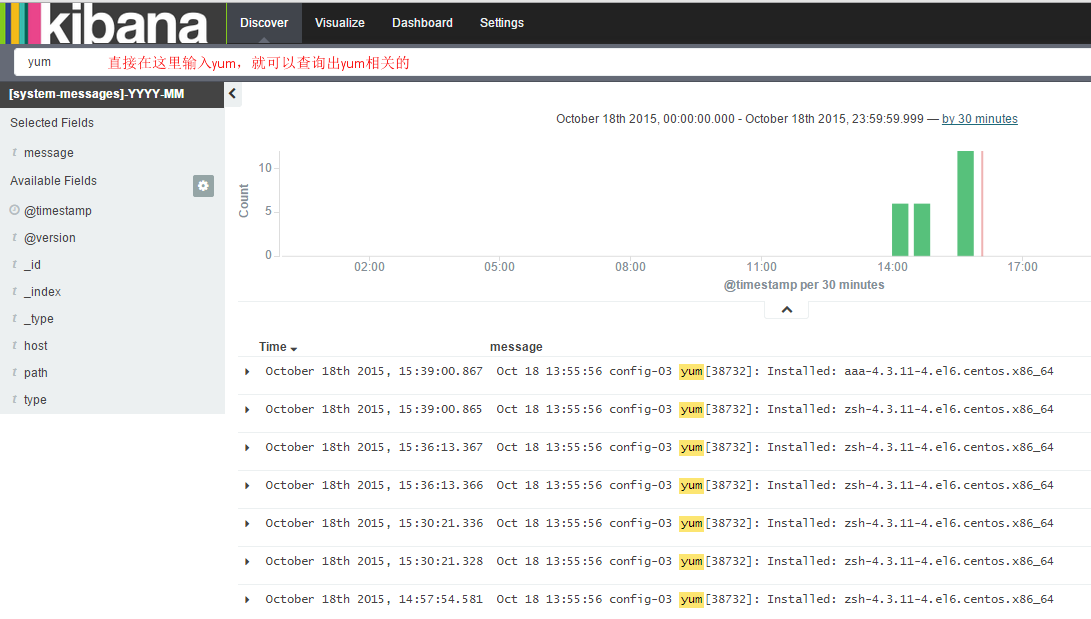
也可以根据搜索框直接查询想要的内容,下图所示为查看日志中包含yum的内容。
11.Nginx反向代理kibana使请求负载均衡
(1)安装nginx
[root@nginx ~]# yum -y install nginx
(2)配置nginx负载均衡,配置文件如下所示:
http {
upstream kibana { #定义后端主机组
server 172.16.4.102:5601 weight=1 max_fails=2 fail_timeout=2;
server 172.16.4.103:5601 weight=1 max_fails=2 fail_timeout=2;
} }
server {
listen 80;
server_name localhost;
location / { #定义反向代理,将访问自己的请求,都转发到kibana服务器
proxy_pass http://kibana/;
index index.html index.htm;
}
}
}
设置完成,访问nginx监听的ip地址即可负载均衡kibana。
由于kiaba不支持用户认证,如果需要用户认证,也可以在nginx处添加认证。
此处ELKstack + redis日志收集系统就部署完成了,需要收集日志只需要设置根据需求编写logstash配置文件即可,下面是一个配置示例
12.案例:Logstash同时收集nginx日志和mysql慢查询日志
说明:这里的日志是我复制生产日志,不是本机生成的日志。
(1)为了方便nginx日志的统计搜索,这里设置nginx访问日志格式为json
说明:如果想实现日志的报表展示,最好将业务日志直接以json格式输出,这样可以极大减轻cpu负载,也省得运维需要写负载的filter过滤正则。
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /var/log/access_json.log json;
(2)收集nginx和mysql慢查询日志,保存到redis消息队列中
input {
file {
path => "/var/log/access_json.log"
type => "nginx-access" #指定日志类型,以便在一个配置文件中收集多个日志,用来区别输出
start_position => "beginning"
codec => "json"
}
file {
path => "/root/slow-mysql.log"
type => "slow-mysql" #指定日志类型,以便在一个配置文件中收集多个日志,用来区别输出
start_position => "beginning"
codec => multiline {
pattern => "^# User@Host"
negate => true
what => "previous"
}
}
}
output {
if [type] == "nginx-access" { #对input中的输入进行判断,如果日志类型为nginx-access则执行以下输出,否则不执行
redis {
host => "172.16.4.104"
data_type => "list"
key => "nginx-access"
}
}
if [type] == "slow-mysql" {
redis {
host => "172.16.4.104"
data_type => "list"
key => "slow-mysql"
}
}
}
Logstash 从redis消息队列读取日志存储到ES中,此处的logstash部署在redis消息队列上,当然也可以部署在ES上
input {
redis {
type => "nginx-access"
host => "172.16.4.104"
data_type => "list"
key => "nginx-access"
}
redis {
type => "slow-mysql"
host => "172.16.4.104"
data_type => "list"
key => "slow-mysql"
}
}
output {
if [type] == "nginx-access" {
elasticsearch {
host => ["172.16.4.102:9200","172.16.4.103:9200"]
protocol => "http"
index => "nginx-access-%{+YYYY.MM}"
}
}
if [type] == "slow-mysql" {
elasticsearch {
host => ["172.16.4.102:9200","172.16.4.103:9200"]
protocol => "http"
index => "slow-mysql-%{+YYYY.MM}"
}
}
}
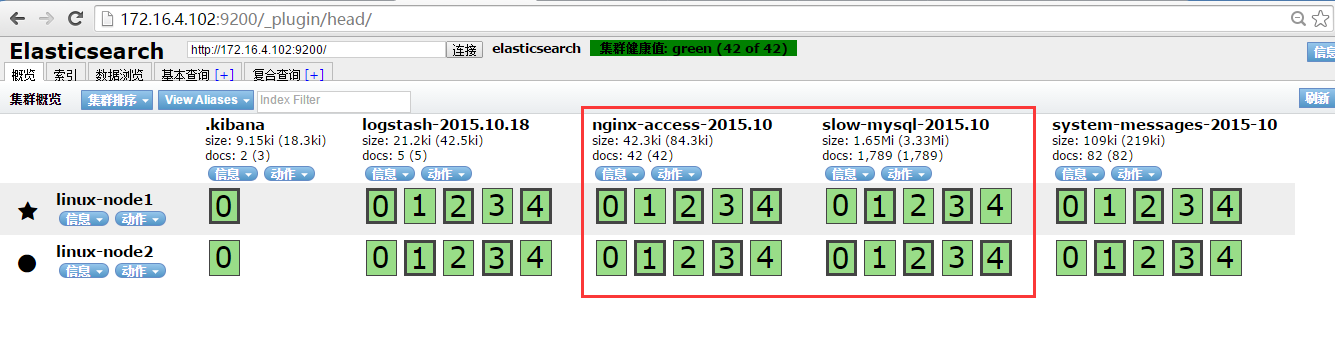
(4)Kibana创建对应日志的索引,用来查询日志
1、创建nginx索引
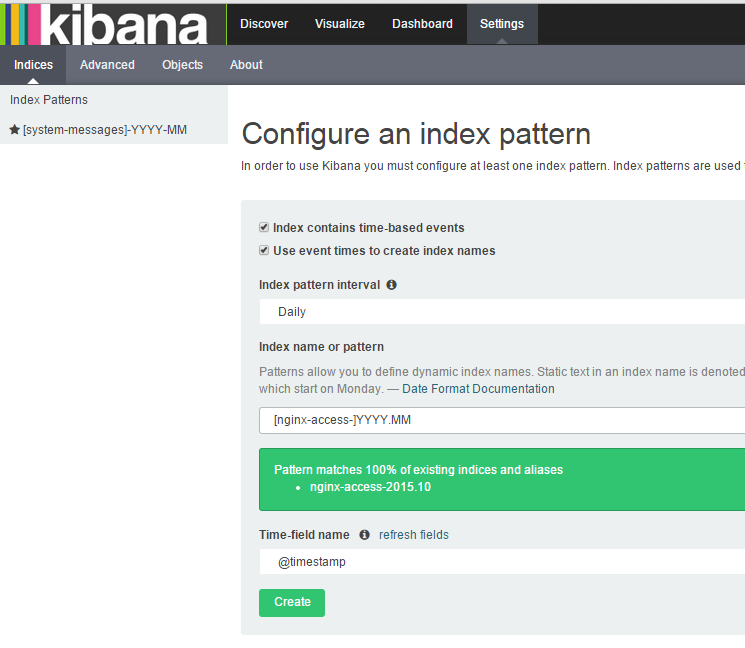
2、这个时候就可以看到nginx日志了

(2)创建mysql慢查询索引
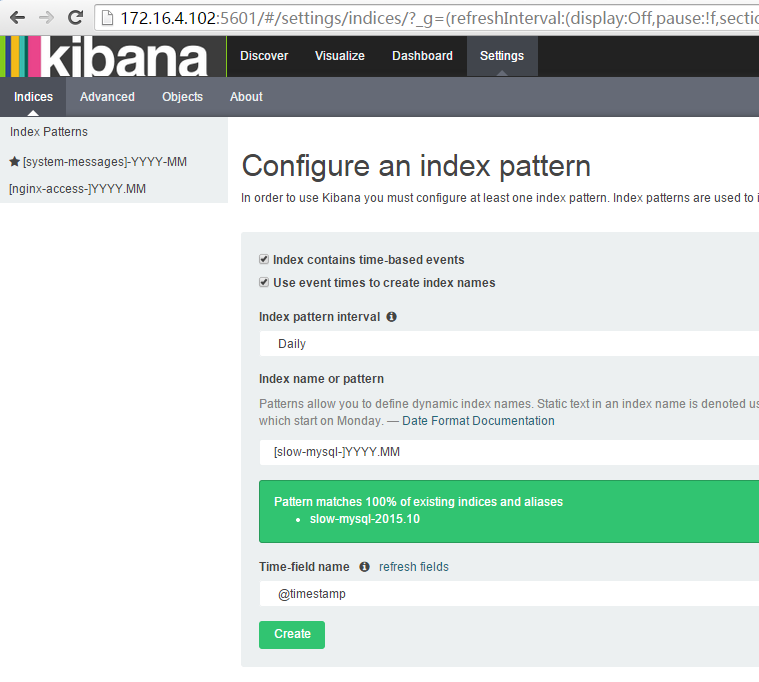
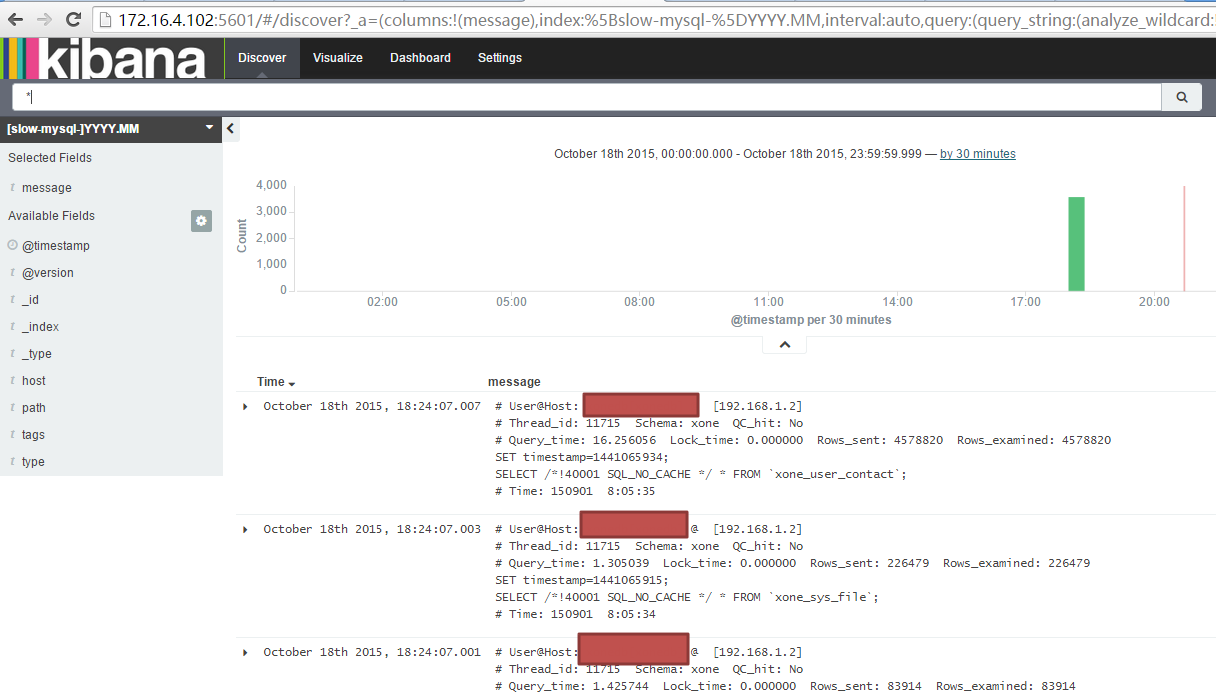
13.图表展示
限于文章篇幅,这里不想做过多的描述图标生产的过程,如果各位有需要可以参考给出的文档,如下是效果图:
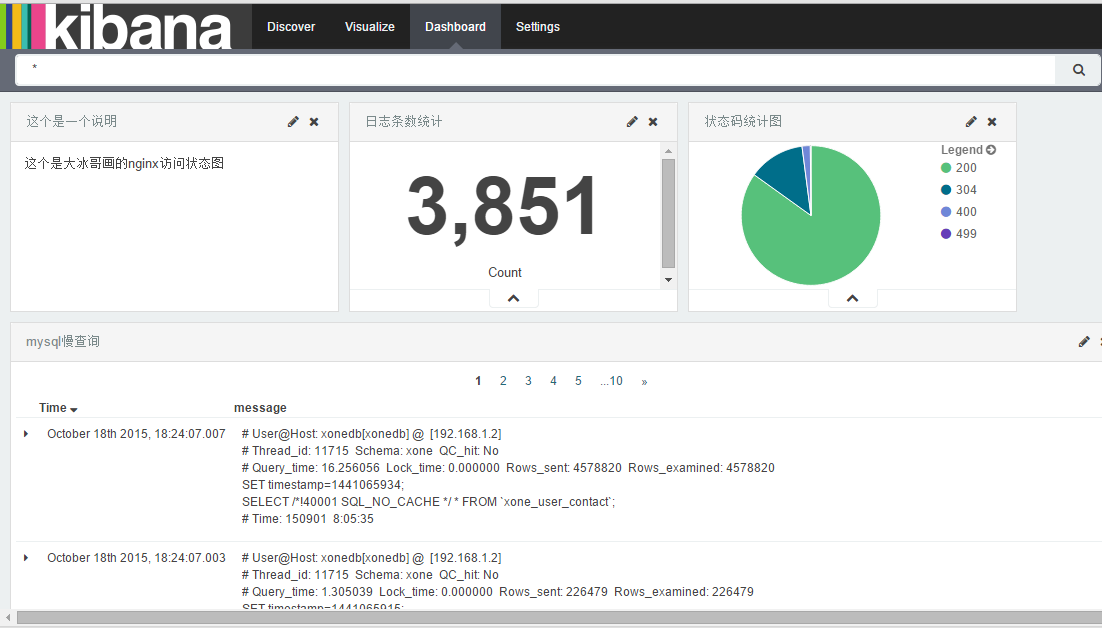
对于kibana图表展示,只想说如下两点:
1、日志最好是json格式,否则还需要使用filter 的grok使用复杂的正则表达式进行日志内容处理,即加大的运维难度,由加大的服务器运行负担。
2、ELKStask最好用来收集业务日志,对于WEB访问日志的分析,可以使用第三方的分析工具,如百度统计,CNZZ,以及开源工具如piwik,awstats。
14.参考文档
中文指南:http://kibana.logstash.es/
篇幅问题,很多内容可能描述不是特别清楚,如果有问题,可以直接联系本人qq或者留言。
转载请注明:西门飞冰的博客 » 企业级日志收集系统——ELKstack