1.简介
传统的存算一体架构具有数据本地化的先天性能优势,而采用存算分离之后,由于所有的数据读写都要通过网络进行,因此就失去了数据本地化的性能优势。为了解决这个问题,会在计算和存储之间引入新的分布式缓存组件,例如Juice FS和Alluxio,以进一步提升数据的读写性能。
Juice FS和Alluxio是当前使用比较广泛的两款分布式缓存组件。
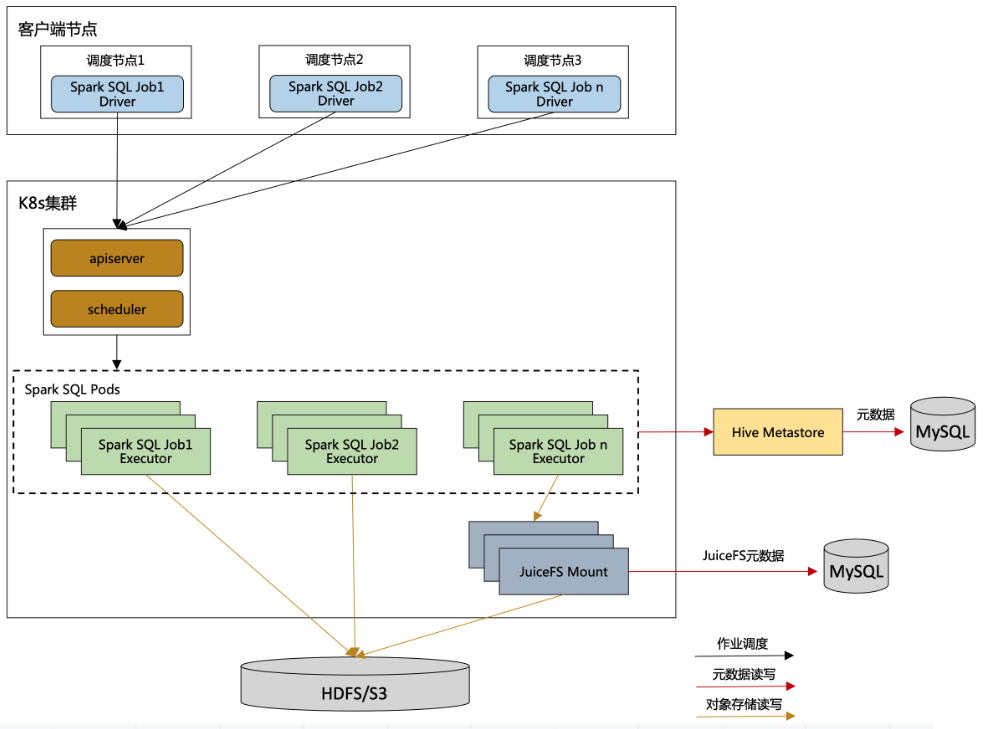
2.运行架构图
对数据访问性能要求相对不高的批处理任务,或者数据需要相对稳妥保存的批处理任务。例如数仓的ODS,DWD,DIM层的spark sql层的批处理任务他们是直接读写底层的存储的,对于ADS或者其他对读写响应要求比较高的作业,就可以通过分布式缓存来读写底层存储数据。
为什么要分开,而不是统一使用分布式缓存?
因为JuiceFS的架构特点,通过JuiceFS写入的数据,只能通过JuiceFS来进行读取,如果JuiceFS服务挂了,那么全部的计算任务都无法正常运行,这个风险实在是太高了。
3.Juice FS简介
官方对Juice FS文件系统的定位是,面向云原生设计的高性能分布式文件系统。
与HDFS和其他分布式文件系统不一样的是,他不存储实际的数据只是在HDFS和其他分布式文件系统之上构建了一个中间层,提供了自己的API和各种SDK,屏蔽掉了底层存储的差异,提供统一的访问入口,但是实际的数据仍然是保存在底层的HDFS或者其他的文件系统之上。不同的点是用Juice FS的数据格式进行存储的。
在实际的应用中,我们底层的数据存储设施往往是比较统一的,例如统一使用HDFS,或者阿里云的对象存储,很少会混合使用多种存储设施,所以使用Juice FS来对接多种存储设施来实现存储的统一入口,这块的功能比较少。
Juice FS另外一个数据缓存的功能,是大数据存算分离架构中使用比较广泛的,所以这也是将Juice FS称为分布式缓存的原因。
4.Juice FS安装
mkdir /root/juicefs cd /root/juicefs wget https://github.com/juicedata/juicefs/releases/download/v1.0.4/juicefs-1.0.4-linux-amd64.tar.gz
2、安装
tar -zxvf juicefs-1.0.4-linux-amd64.tar.gz mv juicefs /usr/local/bin/
3、验证
juicefs juicefs -V
5.Juice FS挂载HDFS
1、MySQL创建数据库juicefs_hdfs,用来存放JuiceFS HDFS的元数据
2、格式化,storage 需要指定为hdfs;bucket 指定namenode的访问地址,如果是HA,则用逗号添加多个;access-key是读写HDFS的用户,此处是root用户
juicefs format \
--storage hdfs \
--bucket hadoop-test01:8020 \
--access-key hadoop \
"mysql://juicefs:数据库密码@(172.16.252.116:3306)/juicefs_hdfs" \
myhdfs

3、挂载 JuiceFS 到本地文件系统
mkdir /mnt/myhdfs juicefs mount -d "mysql://juicefs:数据库密码@(172.16.252.116:3306)/juicefs_hdfs" /mnt/myhdfs
![]()
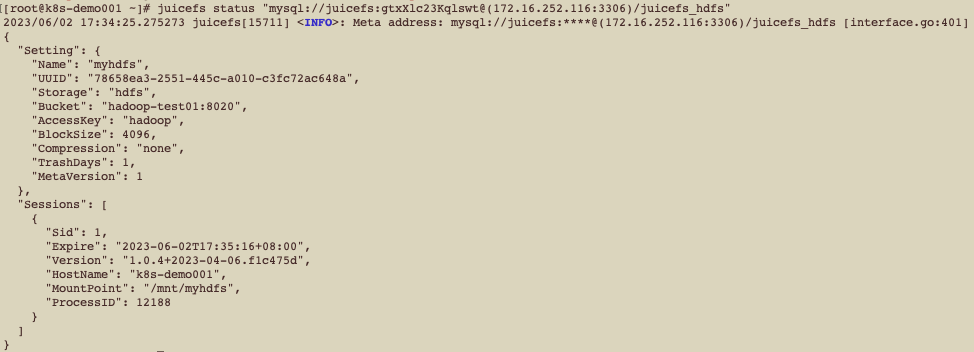
4、查看文件系统状态
juicefs status "mysql://juicefs:数据库密码@(172.16.252.116:3306)/juicefs_hdfs"
6.JuiceFS-Spark SQL本地测试
1、新部署hive metastore
为了避免和之前的环境冲突,这里拷贝一份新的hive
cp -r apache-hive-3.1.2-bin/ apache-hive-3.1.2-bin-juicefs
2、配置hive-site.xml
[root@hadoop-test01 apache-hive-3.1.2-bin-juicefs]# cat conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- ** Security -->
<property>
<name>hive.security.authorization.enabled</name>
<value>false</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.HadoopDefaultAuthenticator</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdConfOnlyAuthorizerFactory</value>
</property>
<property>
<name>hive.privilege.synchronizer</name>
<value>false</value>
</property>
<property>
<name>hive.security.metastore.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.HadoopDefaultMetastoreAuthenticator</value>
</property>
<property>
<name>hive.security.metastore.authorization.auth.reads</name>
<value>true</value>
</property>
<property>
<name>hive.security.metastore.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.DefaultHiveMetastoreAuthorizationProvider</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.16.252.116:3306/hive_hdfs_juicefs?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive_hdfs_juicefs</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>数据库的密码</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
<!-- Metastore -->
<property>
<name>hive.metastore.sasl.enabled</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-test01:9083</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>jfs://myhdfs/warehouse</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>metastore.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- HiveServer2 -->
<property>
<name>hive.users.in.admin.role</name>
<value>root,hive,hadoop</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-test01</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
3、core-site.xml
[root@hadoop-test01 apache-hive-3.1.2-bin-juicefs]# cat conf/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>jfs://myhdfs/warehouse</value>
</property>
<property>
<name>fs.jfs.impl</name>
<value>io.juicefs.JuiceFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.jfs.impl</name>
<value>io.juicefs.JuiceFS</value>
</property>
<property>
<name>juicefs.myhdfs.meta</name>
<value>mysql://juicefs:数据库密码@(172.16.252.116:3306)/juicefs_hdfs</value>
</property>
<property>
<name>juicefs.cache-dir</name>
<value>/var/jfsCache</value>
</property>
<property>
<name>juicefs.cache-size</name>
<value>10240</value>
</property>
<property>
<name>juicefs.access-log</name>
<value>/tmp/juicefs.access.log</value>
</property>
</configuration>
4、删除hdfs-site.xml
rm -f conf/hdfs-site.xml
5、将juicefs-hadoop-1.0.4.jar上传到hive lib目录下
wget https://d.juicefs.com/juicefs/releases/download/v1.0.4/juicefs-hadoop-1.0.4.jar
6、启动hive metastore
(1)首次启动需要先初始化metastore
/opt/module/apache-hive-3.1.2-bin-juicefs/bin/schematool -initSchema -dbType mysql - verbose
(2)启动metastore
/opt/module/apache-hive-3.1.2-bin-juicefs/bin/hive --service metastore nohup /opt/module/apache-hive-3.1.2-bin-juicefs/bin/hive --service metastore 2>&1 &
7、配置spark
cp -r spark-3.2.3-hadoop/ spark-3.2.3-hadoop-juicefs
(2)删除原conf目录下的hive-site.xml、core-site.xml和hdfs-site.xml,并将最新的文件复制过来
(3)将JuiceFS客户端Jar包拷贝到spark/jars下
8、添加HDFS用户
useradd hdfs
9、SparkSQL测试
./spark-3.2.3-hadoop-juicefs/bin/spark-sql \ --verbose \ --database default \ --name sql_test_1 \ --conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/driver-sql-hadoop-jfs-1.log" \ --conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/executor-sql-hadoop-jfs-1.log" \ -e \ " DROP TABLE IF EXISTS spark_dept; CREATE TABLE spark_dept(deptno int, dname string, loc string); INSERT INTO spark_dept VALUES (10, 'ACCOUNTING', 'NEW YORK'); select * from spark_dept; select count(*) from spark_dept where deptno=10 "
10、查看JuiceFS HDFS上的文件
hadoop fs -ls /myhdfs