1.简介
无论是我们自己开发的系统,还是各种中间件,高可用部署可以避免单点故障,是生产运行的必备要求。对于flink作业也一样,我们开发好的flink 作业,部署到生产环境,也需要高可用的方式来运行。
Flink的高可用,指的就是job manager的高可用,默认情况下,每个 Flink 集群只有一个 JobManager 实例。这会导致 单点故障:如果 JobManager 崩溃,则不能提交任何新程序,运行中的程序也会失败。
JobManager 高可用一般概念是指,在任何时候都有 一个领导者 JobManager,如果领导者出现故障,则有多个备用 JobManager 来接管leader。这保证了 不存在单点故障,只要有备用 JobManager 担任leader,程序就可以继续运行。
Flink 提供了两种高可用服务实现:
1、Zookeeper:每个flink集群部署都可以使用zookeeper HA服务。它们需要一个运行的zookeeper复制组(quorum)。flink operator 1.4版本之前是不支持zookeeper这种高可用模式的。
2、Kubernetes:kubernetes HA服务只能运行在Kubernetes上,大致来讲就是flink job manager的主备选举。
一个问题说明:
问题:K8S 本身具有pod的容错机制,如果一个服务只部署了一个pod,健康检查出现问题之后,K8S 会通过自己的容错机制重启这个pod,如果物理节点有问题,也会调度到其他节点,flink ha启动两个jobmanager 来选举,不是和k8s的容错机制冲突了吗?
说明:只有一个Jobmanager,出现故障pod是重启了,但相当于是重启了操作系统,状态数据丢失了,即使jm pod起来,taskmanager也是会失败的,对于保障性高的作业,ha仍是必须使用的。同时 jm切换,tm会跟着切换到新的jm,这个过程中,旧的tm会被kill,会新起tm,ha文件里面存储的状态元数据信息会自动从checkpoint恢复。
2.Flink HA K8s 场景
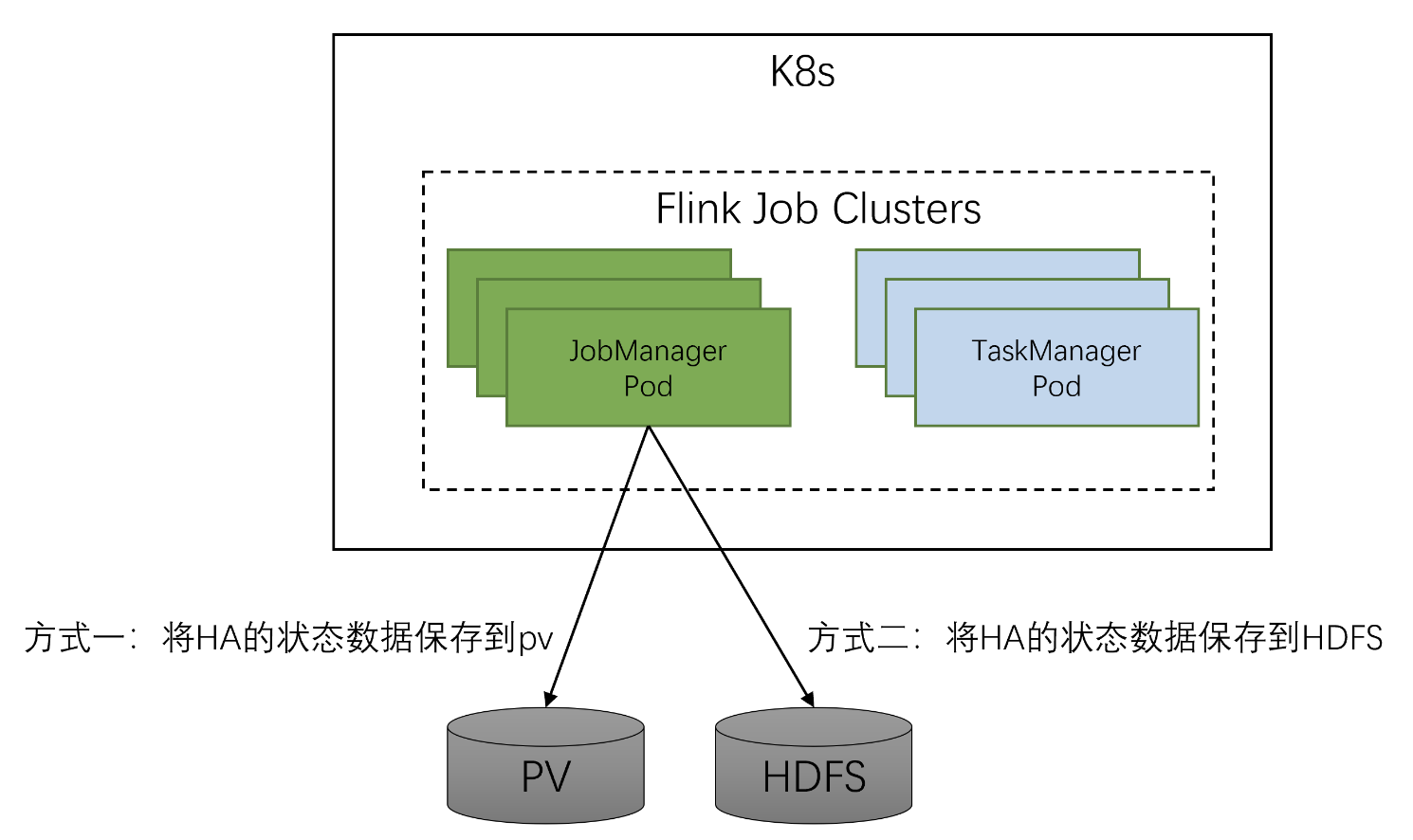
1、创建Flink HA PVC
[root@k8s-demo001 ~]# cat flink-ha-pvc.yaml
#Flink HA 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-ha-pvc # ha pvc名称
namespace: flink
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
[root@k8s-demo001 ~]# kubectl apply -f flink-ha-pvc.yaml
创建后查看pvc
[root@k8s-demo001 ~]# kubectl get pvc -n flink | grep ha-pvc flink-ha-pvc Bound pvc-b71f444a-600d-4cb3-80a0-ad1e9268dd2c 1Gi RWX nfs-storage 36s
2、使用application 模式编写flink 作业yaml并提交作业
[root@k8s-demo001 ~]# cat application-deployment-checkpoint-ha.yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment-checkpoint-ha # flink 集群名称
spec:
image: flink:1.13.6 # flink基础镜像
flinkVersion: v1_13 # flink版本,选择1.13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
state.checkpoints.dir: file:///opt/flink/checkpoints
high-availability.type: kubernetes
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/flink_recovery # JobManager HA数据保存路径
serviceAccount: flink
jobManager:
replicas: 2 # HA下, jobManger的副本数要大于1
resource:
memory: "1024m"
cpu: 1
taskManager:
resource:
memory: "1024m"
cpu: 1
podTemplate:
spec:
hostAliases:
- ip: "172.16.252.129"
hostnames:
- "Kafka-01"
- ip: "172.16.252.130"
hostnames:
- "Kafka-02"
- ip: "172.16.252.131"
hostnames:
- "Kafka-03"
containers:
- name: flink-main-container
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
- name: flink-checkpoints # 挂载checkpoint pvc
mountPath: /opt/flink/checkpoints
- name: flink-ha # HA pvc配置
mountPath: /opt/flink/flink_recovery
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
- name: flink-checkpoints
persistentVolumeClaim:
claimName: flink-checkpoint-application-pvc
- name: flink-ha
persistentVolumeClaim:
claimName: flink-ha-pvc
job:
jarURI: local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT-jar-with-dependencies.jar # 使用pv方式挂载jar包
entryClass: org.fblinux.StreamWordCountWithCP
args: # 传递到作业main方法的参数
- "172.16.252.129:9092,172.16.252.130:9092,172.16.252.131:9092"
- "flink_test"
- "172.16.252.113"
- "3306"
- "flink_test"
- "wc"
- "file:///opt/flink/checkpoints"
- "10000"
- "1"
parallelism: 1
upgradeMode: stateless


3.Flink HA ZK场景
flink kubernetes operator1.4版本才开始支持zookeeper的HA,因此我们需要使用1.4及以上的版本
1、编写yaml文件,提交任务
[root@k8s-demo001 ~]# cat application-deployment-checkpoint-ha-zk.yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment-checkpoint-ha-zk # flink 集群名称
spec:
image: flink:1.13.6 # flink基础镜像
flinkVersion: v1_13 # flink版本,选择1.13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
state.checkpoints.dir: file:///opt/flink/checkpoints # checkpoint的路径
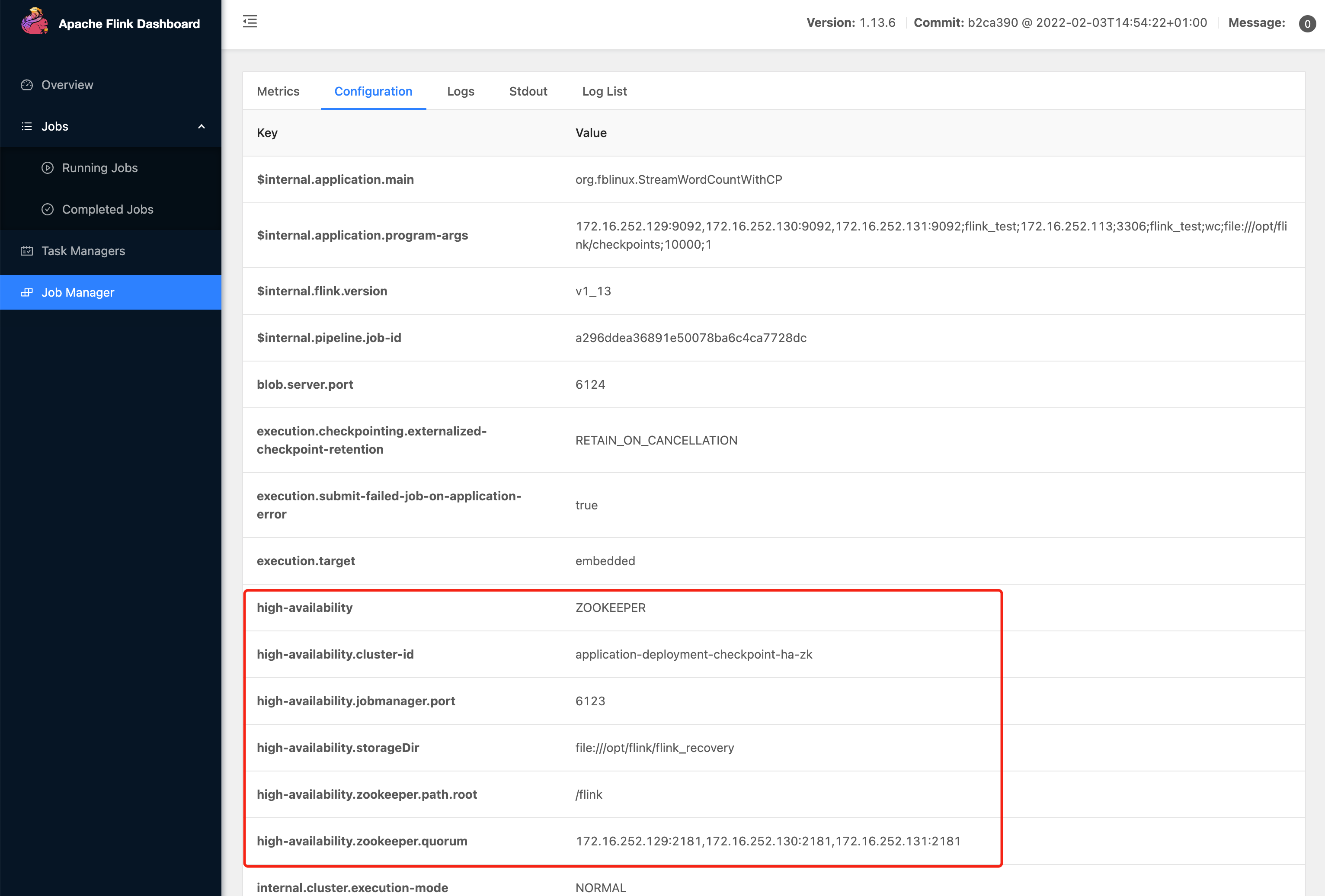
high-availability: ZOOKEEPER
high-availability.zookeeper.quorum: 172.16.252.129:2181,172.16.252.130:2181,172.16.252.131:2181
high-availability.zookeeper.path.root: /flink
high-availability.storageDir: file:///opt/flink/flink_recovery # JobManager HA数据保存路径
serviceAccount: flink
jobManager:
replicas: 2 # HA下, jobManger的副本数要大于1
resource:
memory: "1024m"
cpu: 1
taskManager:
resource:
memory: "1024m"
cpu: 1
podTemplate:
spec:
hostAliases:
- ip: "172.16.252.129"
hostnames:
- "Kafka-01"
- ip: "172.16.252.130"
hostnames:
- "Kafka-02"
- ip: "172.16.252.131"
hostnames:
- "Kafka-03"
containers:
- name: flink-main-container
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
- name: flink-checkpoints # 挂载checkpoint pvc
mountPath: /opt/flink/checkpoints
- name: flink-ha # HA pvc配置
mountPath: /opt/flink/flink_recovery
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
- name: flink-checkpoints
persistentVolumeClaim:
claimName: flink-checkpoint-application-pvc
- name: flink-ha
persistentVolumeClaim:
claimName: flink-ha-pvc
job:
jarURI: local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT-jar-with-dependencies.jar # 使用pv方式挂载jar包
entryClass: org.fblinux.StreamWordCountWithCP
args: # 传递到作业main方法的参数
- "172.16.252.129:9092,172.16.252.130:9092,172.16.252.131:9092"
- "flink_test"
- "172.16.252.113"
- "3306"
- "flink_test"
- "wc"
- "file:///opt/flink/checkpoints"
- "10000"
- "1"
parallelism: 1
upgradeMode: stateless
[root@k8s-demo001 ~]# kubectl apply -f application-deployment-checkpoint-ha-zk.yaml

访问web页面验证:
4.两种高可用方式的选择
关于 k8s下 flink的ha,在生产环境中,建议使用zk
对于Kubernetes的服务实现方式, jobmanager的高可用状态信息保存在ConfigMap里, jobmanager的主备选举和状态监控需要借助监控k8s的configmap来实现, 这个过程会不断地与K8s的apiserver进行调用交互, 当Flink作业较多的时候, 会对K8s造成一定的压力. 反过来, 在实际应用中, K8s是一个基础的容器运行平台, 它上面除了运行Flink作业外, 还会运行其他应用的Pod, 当K8s集群压力过大时, Flink HA与K8s ApiServer的交互会受到影响, 从而影响Flink HA, 尤其在k8s资源非常紧张, 负载压力很大的情况下, 会导致jobmanager 主从切换失败, 最终导致Flink作业异常终止。
Zookeeper是很多大数据组件使用的高可用服务方式, Hadoop和Kafka等组件就是使用它实现HA. Flink HA的Zookeeper服务实现方式很成熟, 在Flink On K8s的实际应用中, 采用Zookeeper作为高可用的实现方式也是可以的, 这样可以降低Flink 对K8s ApiServer的压力, 也避免了K8s因资源紧张或负载过高对Flink HA的影响, 所以Zookeeper的高可用方式也是值得推荐的.
转载请注明:西门飞冰的博客 » (4)Flink on k8s HA 实现



