1.简介
之前部署了flink operator,并将spark 作业提交到了k8s之上,但是也仅仅达到了能用的程度,距离生产落地还有一些内容需要调整。
2.Flink 作业日志持久化
当flink运行出错的时候,或者我们要分析flink运行状态的时候,运行日志是我们排查问题的重要依据。flink operator运行的flink 作业,默认情况下,日志文件只保存在pod容器中,随着容器的销毁,对应的日志就会丢失,分析问题就无从下手
为此我们需要把jobmanager和taskmanager的日志文件持久化的保存起来,而且是保存在外部的存储设备中,这样无论是jobmanager和taskmanager终止或者重启多少遍,日志都不会丢失。
1、创建存储flink log的pvc
[root@k8s-demo001 yaml_files]# cat flink-log-pvc.yaml
#Flink 日志 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-log-pvc # 日志 pvc名称
namespace: flink
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
[root@k8s-demo001 yaml_files]# kubectl apply -f flink-log-pvc.yaml

2、创建作业,将日志持久化到pv上
[root@k8s-demo001 ~]# cat application-deployment-with-log.yaml
# Flink Application集群
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment-with-log
spec:
image: flink:1.13.6
flinkVersion: v1_13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
taskManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
- name: flink-log # 挂载log
mountPath: /opt/flink/log
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
- name: flink-log
persistentVolumeClaim:
claimName: flink-log-pvc
job:
jarURI: local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT.jar
entryClass: org.fblinux.StreamWordCount
args:
parallelism: 1
upgradeMode: stateless
[root@k8s-demo001 ~]# kubectl apply -f application-deployment-with-log.yaml

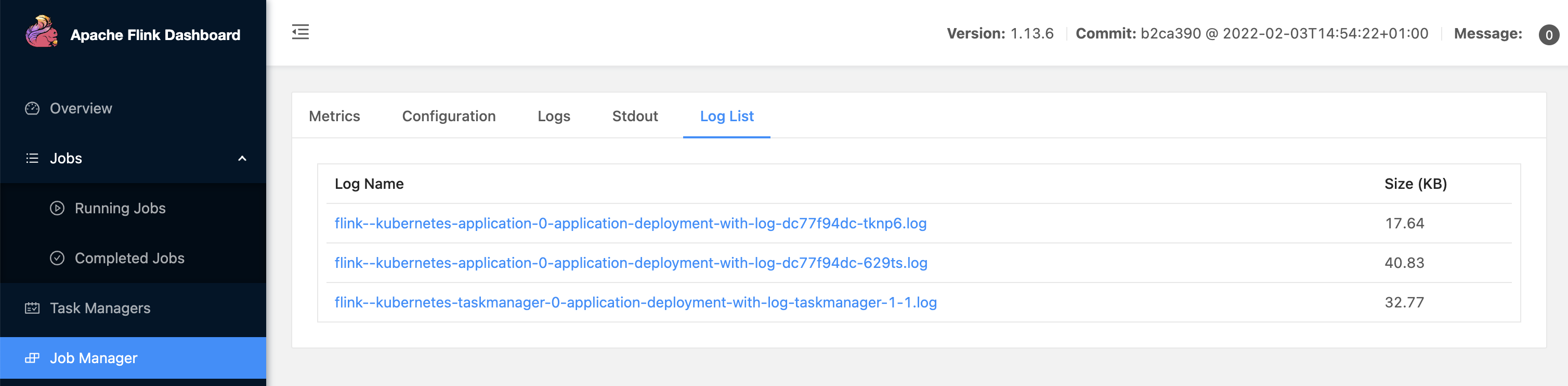
网页查看:
http://flink.k8s.io/flink/application-deployment-with-log/#/job-manager/log
3.时区配置
flink容器和flink kubernetes operator容器的默认时区是UTC,与我们的北京时区相差8小时,需要修改为北京时间
(1)设置flink容器时区
修改yaml文件,在containers:下添加时区环境变量
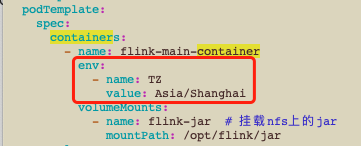
修改完成,重启提交,查询日志容器的时间就恢复正常了
(2)设置flink operator容器时区
修改flink-kubernetes-operator-helm目录下 flink-kubernetes-operator\templates\flink-operator.yaml文件,在containers:下添加时区环境变量
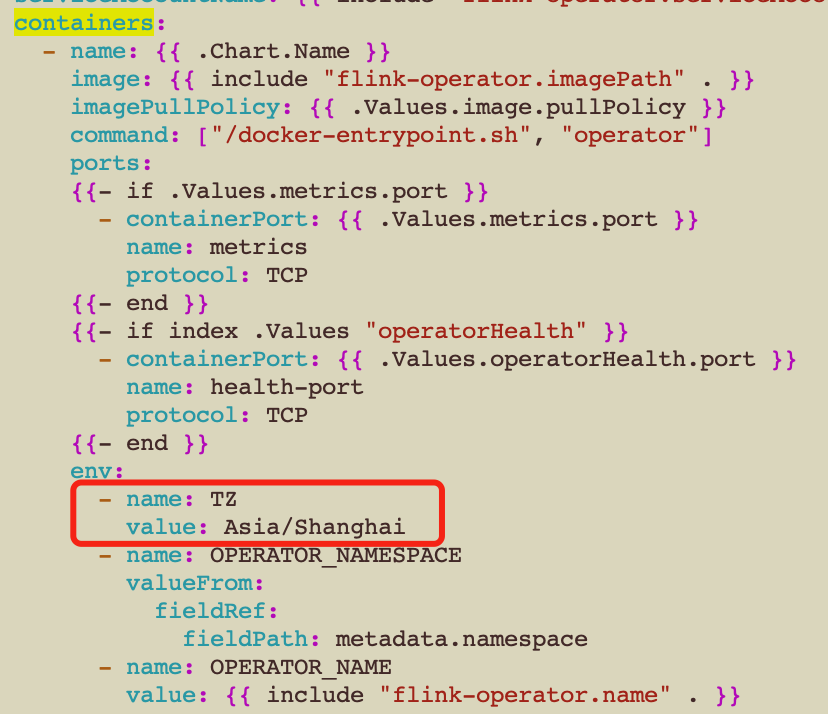
修改operator配置需要卸载重新安装:
卸载:
helm uninstall flink-kubernetes-operator -n flink kubectl -n flink delete configmap kube-root-ca.crt; kubectl -n flink delete svc --all; kubectl -n flink delete secret --all; kubectl -n flink delete serviceaccount --all; kubectl -n flink delete role --all; kubectl -n flink delete rolebinding --all
重新安装flink operator:
helm install -f values.yaml flink-kubernetes-operator . --namespace flink --create-namespace
4.operator日志持久化保存
日志对于排查问题的重要性是不言而喻的,所有提交到K8S的flink 作业,都是由flink operator来进行管理的,有时候难免会出现一些问题,需要通过flink operator日志来定位,下面我们就来配置flink operator的日志持久化保存
1、创建日志pvc
编写日志pvc的yaml
[root@k8s-demo001 ~]# cat operator-log-pvc.yaml
#flink-kubernetes-operator log 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-operator-log-pvc # operator log pvc名称
namespace: flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
创建pvc
kubectl apply -f operator-log-pvc.yaml

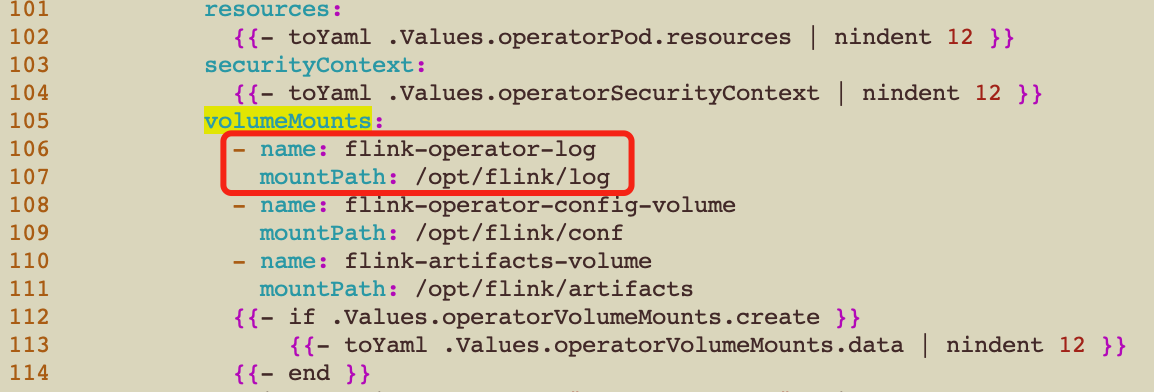
2、修改helm/values.yaml文件,添加log4j配置信息
defaultConfiguration:
log4j-operator.properties: |+
# Flink Operator Logging Overrides
# rootLogger.level = DEBUG
# logger.operator.name= org.apache.flink.kubernetes.operator
# logger.operator.level = DEBUG
rootLogger.appenderRef.file.ref = LogFile
appender.file.name = LogFile
appender.file.type = File
appender.file.append = false
appender.file.fileName = ${sys:log.file}
appender.file.layout.type = PatternLayout
appender.file.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log4j-console.properties: |+
# Flink Deployment Logging Overrides
# rootLogger.level = DEBUG
# ** Set the jvm start up options for webhook and operator
jvmArgs:
webhook: "-Dlog.file=/opt/flink/log/webhook.log"
operator: "-Dlog.file=/opt/flink/log/operator.log"
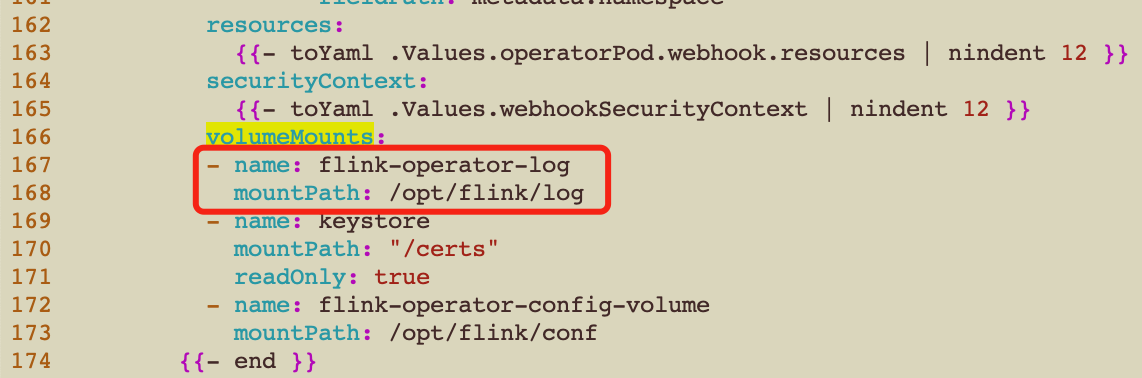

4、卸载现有Flink Kubernetes Operator
helm uninstall flink-kubernetes-operator -n flink kubectl -n flink delete configmap kube-root-ca.crt; kubectl -n flink delete svc --all; kubectl -n flink delete secret --all; kubectl -n flink delete serviceaccount --all; kubectl -n flink delete role --all; kubectl -n flink delete rolebinding --all
5、重新安装Flink Kubernetes Operator
helm install -f values.yaml flink-kubernetes-operator . --namespace flink --create-namespace
6、测试,提交作业
kubectl apply -f application-deployment-with-pv.yaml
验证日志持久化存储到了nfs持久卷上,以后无论operator重启多少遍,他的历史日志文件都会保留下来
[root@k8s-demo001 ~]# ll /nfs/data/flink-flink-operator-log-pvc-pvc-f5b9bb7a-9f54-4252-9c99-50a73b8505af/ 总用量 44 -rw-r--r-- 1 9999 9999 34354 5月 26 11:33 operator.log -rw-r--r-- 1 9999 9999 4240 5月 26 11:32 webhook.log
5.
flink operator是支撑和保障flink 作业在K8S 上正常运行的核心组件,在实际生产环境中,我们通常会有上百个,甚至上千个flink作业被提交到K8S 上运行,这些Flink 作业的创建和管理,都由Flink operator来负责,然而在通常情况下,flink operator的默认配置不能完全满足生产的需求,例如控制循环线程数量,jvm启动参数等。接下来我们就来看一看如何对flink operator的参数进行修改。
Flink Kubernetes Operator可配置的参数:https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-release-1.3/docs/operations/configuration/
1、配置Flink Operator参数,修改helm/values.yaml文件,在flink-conf.yaml部分添加或修改配置信息:
defaultConfiguration:
# If set to true, creates ConfigMaps/VolumeMounts. If set to false, no configuration will be created.
# All below fields will be ignored if create is set to false.
create: true
# If set to true,
# (1) loads the built-in default configuration
# (2) appends the below flink-conf and logging configuration overrides
# If set to false, loads just the overrides as in (2).
# This option has not effect, if create is equal to false.
append: true
flink-conf.yaml: |+
# Flink Config Overrides
kubernetes.operator.metrics.reporter.slf4j.factory.class: org.apache.flink.metrics.slf4j.Slf4jReporterFactory
kubernetes.operator.metrics.reporter.slf4j.interval: 5 MINUTE
kubernetes.operator.flink.client.timeout: 30 s
kubernetes.operator.reconcile.interval: 60 s
kubernetes.operator.reconcile.parallelism: 30
kubernetes.operator.observer.progress-check.interval: 5 s
修改Flink Kubernetes Operator JVM启动参数
jvmArgs: webhook: "-Dlog.file=/opt/flink/log/webhook.log -Xms1g -Xmx1g" operator: "-Dlog.file=/opt/flink/log/operator.log -Xms1g -Xmx1g"
6.operator 高可用部署
flink operator是实现flink作业在K8S运行的核心组件,如果flink operator挂掉了,新的作业将无法提交,运行中的作业它们的状态也难以得到保障,所以在生产环境上,我们需要将flink operator作业做高可用部署,避免单点故障,尽最大可能保障flink 作业在K8S上的稳定运行。
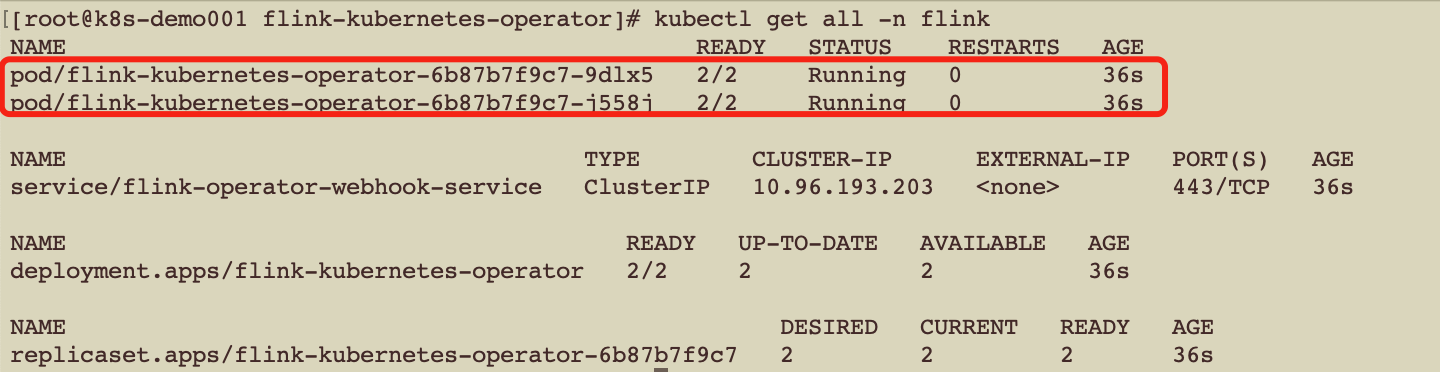
1、配置Flink Kubernetes Operator高可用
replicas: 2
defaultConfiguration:
# If set to true, creates ConfigMaps/VolumeMounts. If set to false, no configuration will be created.
# All below fields will be ignored if create is set to false.
create: true
# If set to true,
# (1) loads the built-in default configuration
# (2) appends the below flink-conf and logging configuration overrides
# If set to false, loads just the overrides as in (2).
# This option has not effect, if create is equal to false.
append: true
flink-conf.yaml: |+
# Flink Config Overrides
kubernetes.operator.metrics.reporter.slf4j.factory.class: org.apache.flink.metrics.slf4j.Slf4jReporterFactory
kubernetes.operator.metrics.reporter.slf4j.interval: 5 MINUTE
kubernetes.operator.flink.client.timeout: 30 s
kubernetes.operator.reconcile.interval: 60 s
kubernetes.operator.reconcile.parallelism: 30
kubernetes.operator.observer.progress-check.interval: 5 s
# flink operator 选主的配置
kubernetes.operator.leader-election.enabled: true
kubernetes.operator.leader-election.lease-name: flink-operator-lease
2、为了使配置生效,需要重新安装flink operator
3、查看Flink Kubernetes Operator的实例数量
转载请注明:西门飞冰的博客 » (2)Flink on k8s 的一些生产配置



