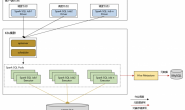
1.简介
nifi 是一个数据同步的框架,像是flume和datax可以完成的操作,nifi都可以完成,本文展示了两个nifi的实际案例,来学习nifi的使用。
案例一:使用nifi离线同步mysql数据到hdfs,模拟datax的常用场景
案例二:使用nifi实时监控Kafka数据到hdfs,模拟flume的常用场景
2.离线同步mysql数据到hdfs
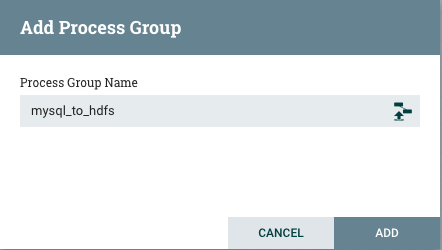
1、添加处理组
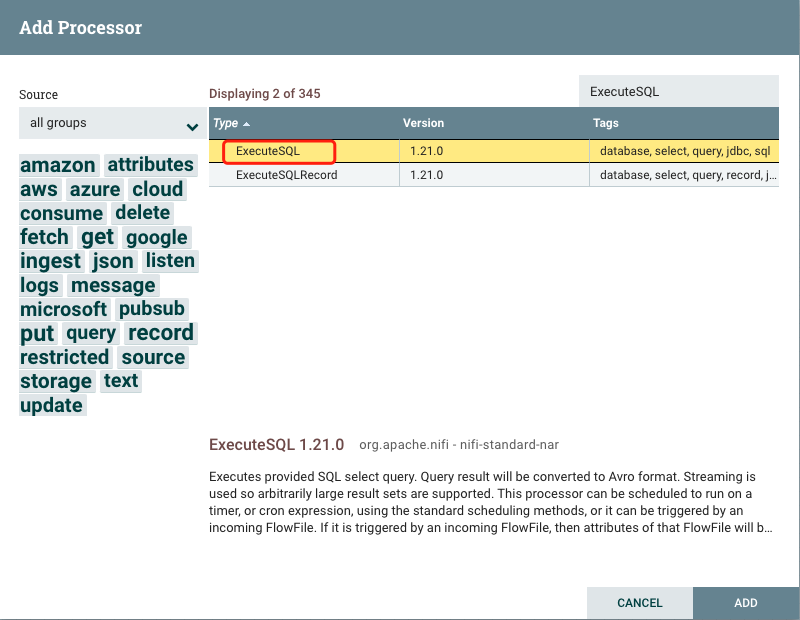
2.1.配置ExecuteSQL处理器
(1)添加mysql的连接池
配置之前需要先创建一个连接池
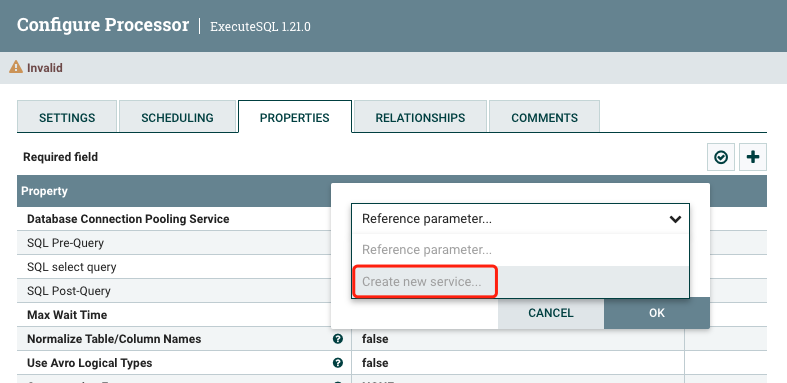
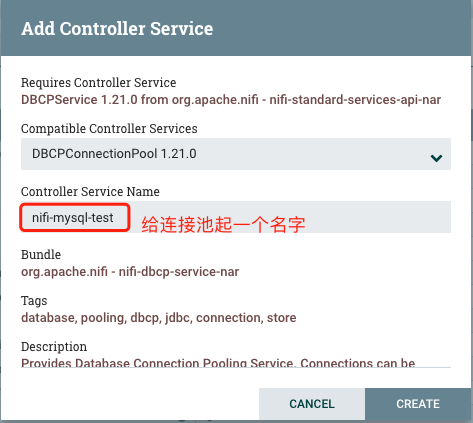
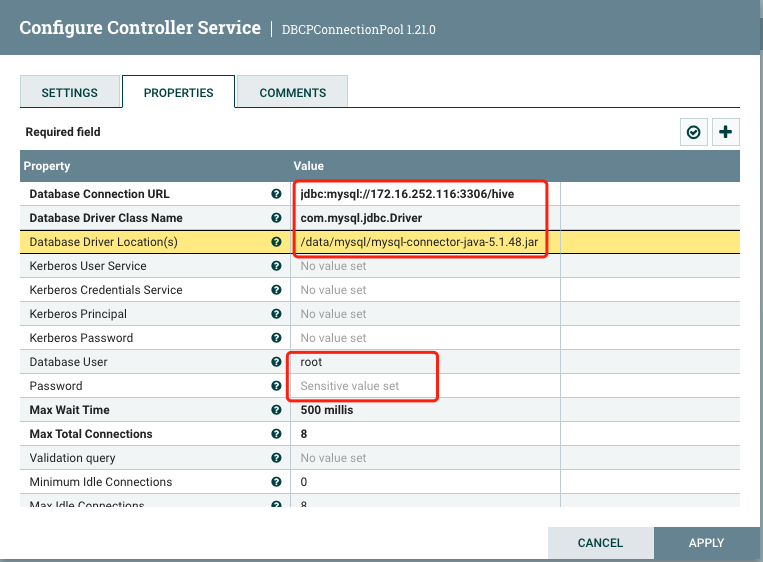

到这里mysql的连接池就添加完了
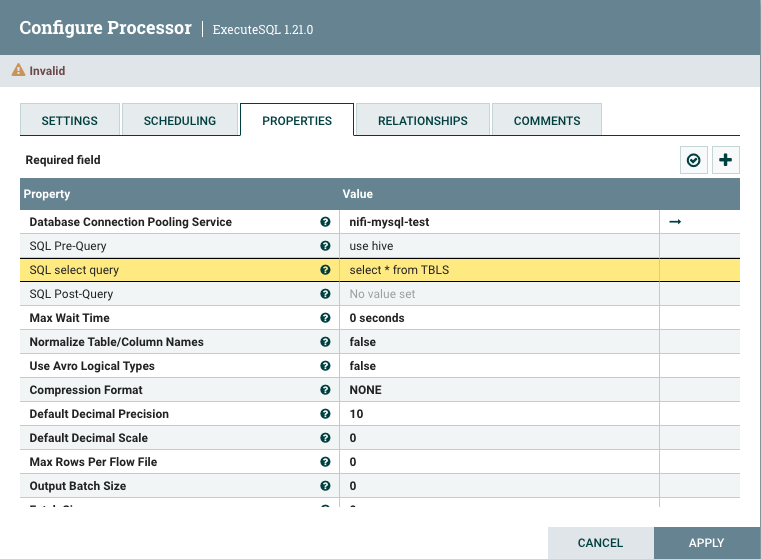
(2)编辑executeSQL信息,主要的就是SQL select query,同步的数据就是这条sql读取的内容
2.2.配置HDFS 处理器
添加putHdfs将数据写出到hdfs。

参数解析:
(1)Hadoop Configuration Resources:hadoop配置文件的地址,写core-site.xml和hdfs-site.xml的地址
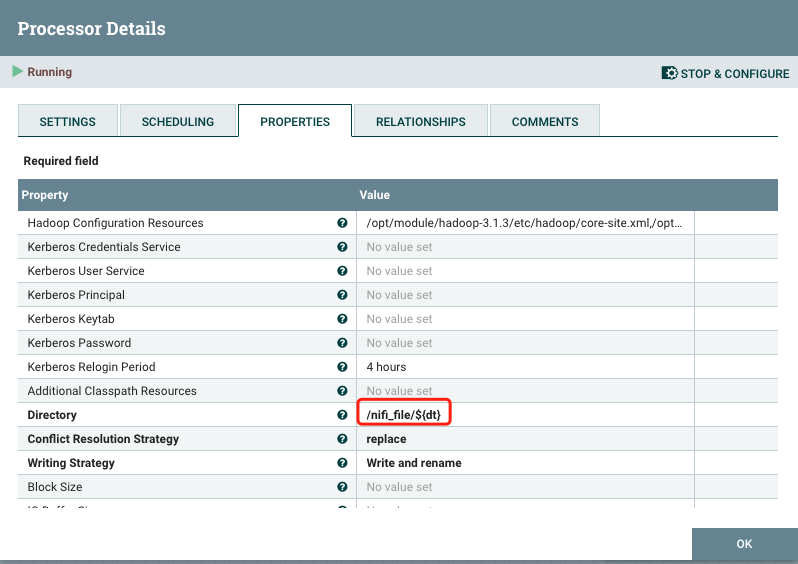
(2)Directory:写入到hdfs的路径
(3)Conflict Resolution Strategy:文件名冲突解决策略,默认fail报错,同步文件选择append追加写入,同步数据库选择replace
(4)Writing Strategy: 写入策略,默认写入加改名。打到块大小文件滚动
(5)Block Size: 块大小
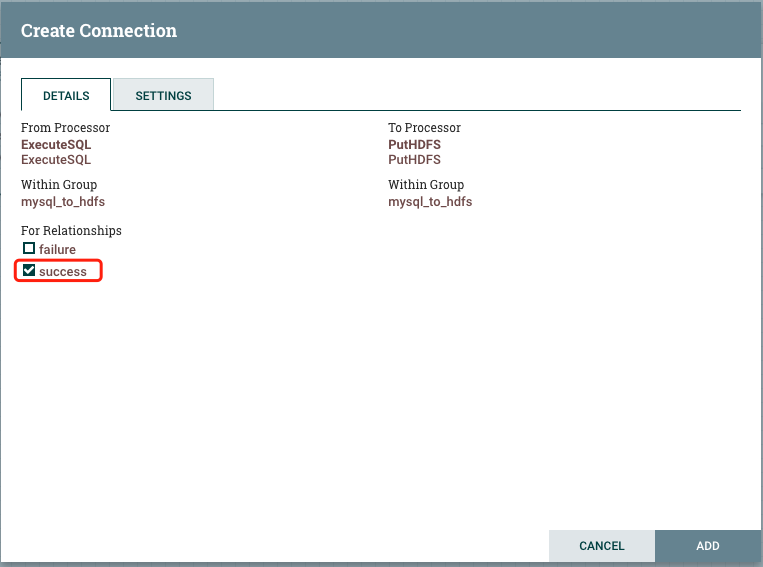
2.3.连接处理器
点击上游处理器的箭头拖动到下游即可连接,连接时需要点击将上游哪种情况的数据输出到下游,这里选择success。
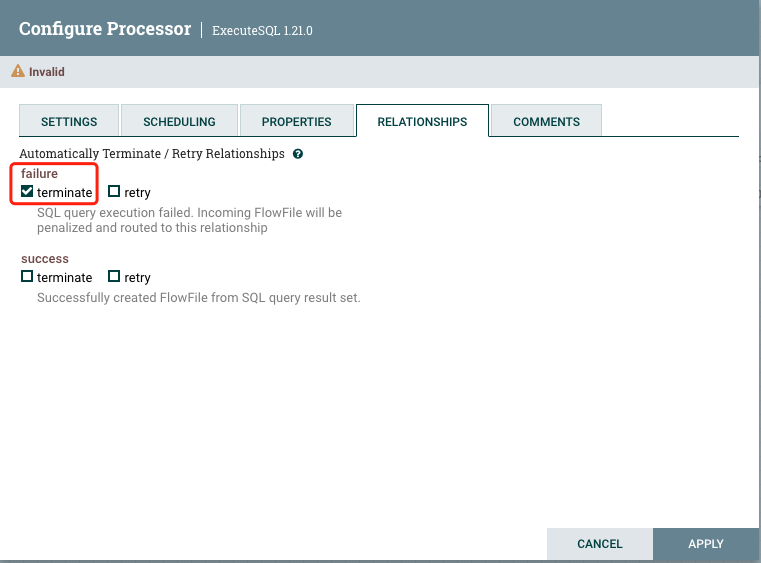
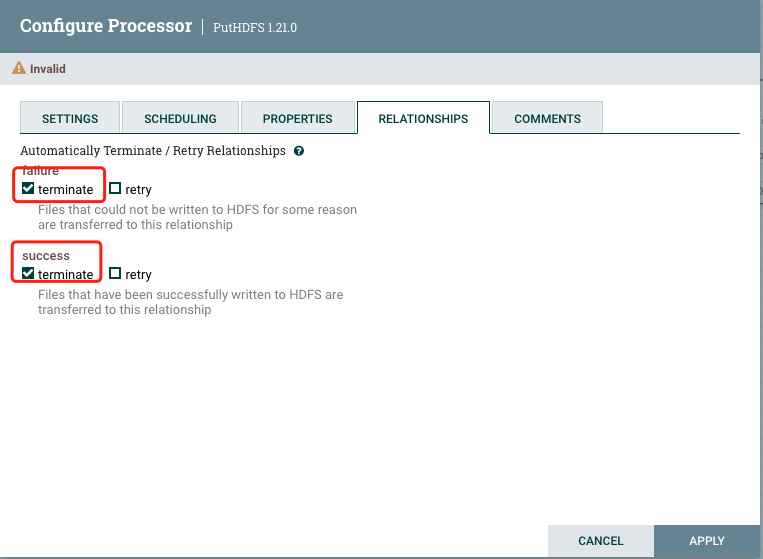
添加成功之后,上游处理完毕。Nifi运行要求每一个处理器的数据情况都要有处理。所以PutHDFS需要自己解决自身数据的情况。
配置数据发送失败或者成功都直接终止当前数据flowFile即可。


查看hdfs目录也有了数据

2.4.修改数据格式为json
在读取和写出数据中间添加一个转换json的处理器,这个处理器是不需要配置什么东西的,只需要把读取过来的数据转换为json格式


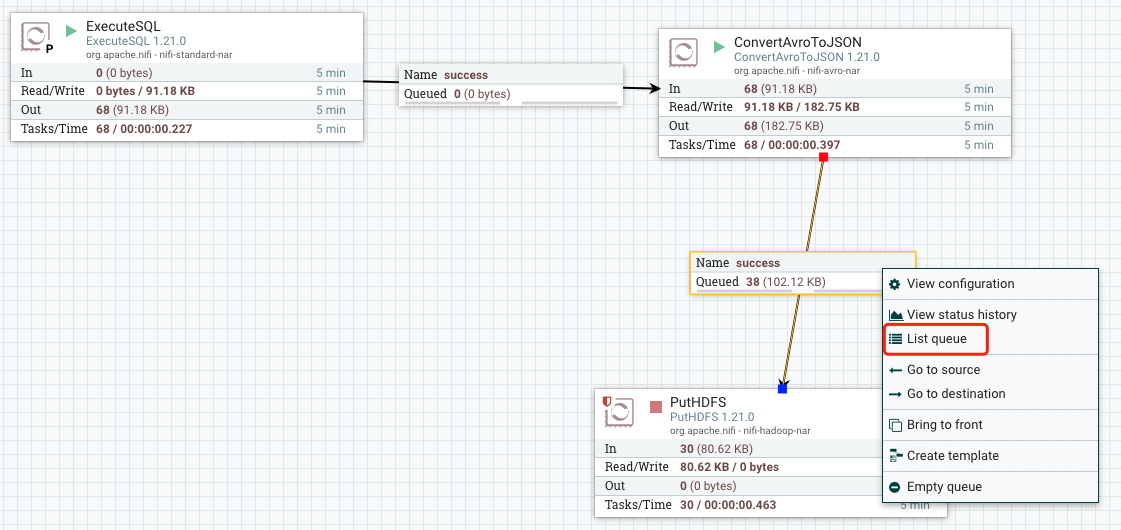
2.5.写入动态目录
需求:添加动态参数控制数据写入到hdfs的路径。
默认情况下所有的上传文件都会发送到同一个文件夹,导致文件混乱。UpdateAttribute 可以定义变量信息
这里定义了一个dt变量值是获取当前时间:${now():format(‘yyyy-MM-dd’)}
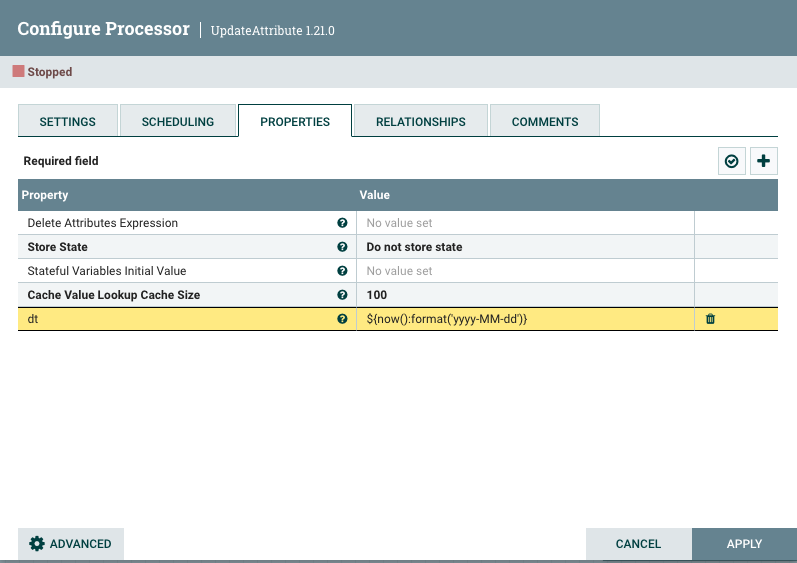
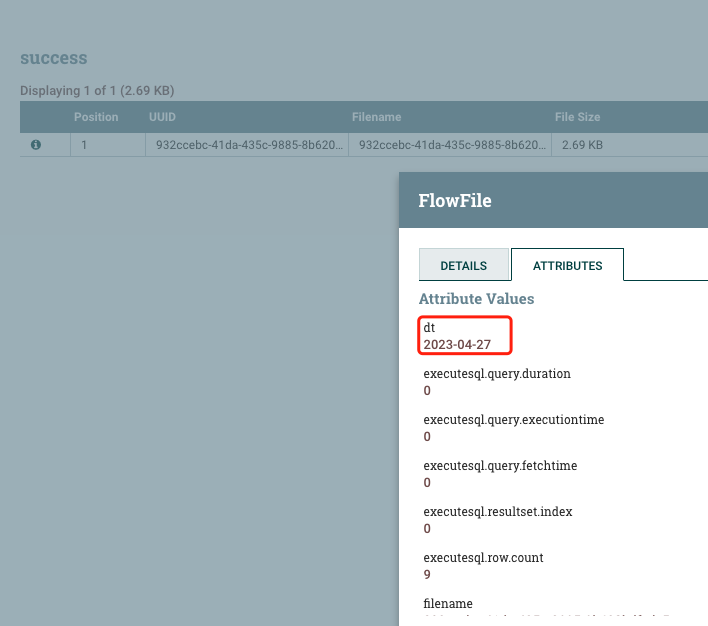


2.6.修改文件名控制文件滚动
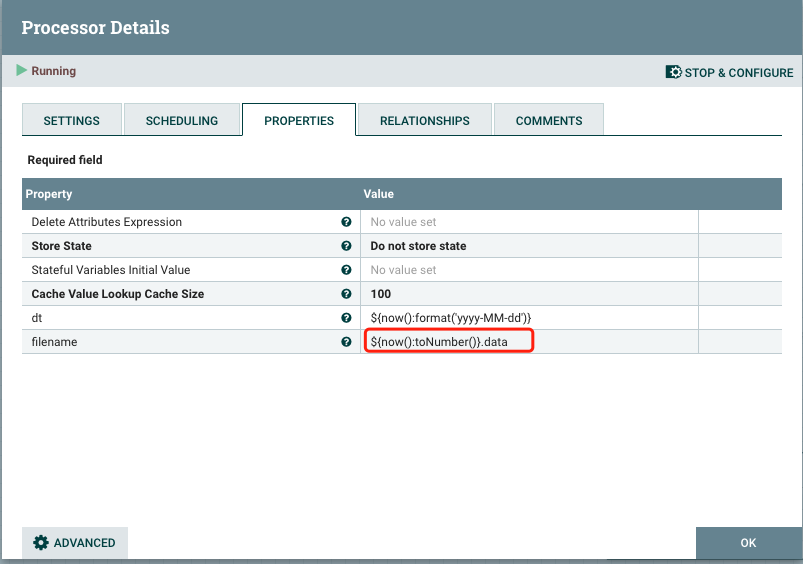
NIFI读取数据的文件名称为自动生成的字符串,没有任何含义,可以通过修改Attribute参数来修改fileName。
这个重新修改了filename的值为 ${now():toNumber()}.data


最终结果验证:

3.实时监控kafka数据到hdfs
需求:实时监控kafka主题,将数据同步发送到hdfs。
新建组

3.1.

参数说明:
Kafka Brokers:Kafka 服务器地址,多个地址用逗号分隔。
Topic(s):要消费的 Kafka 主题名,多个主题名用逗号分隔。
Group ID:消费者组 ID,用于标识一组消费者。
Auto Commit Enabled:是否启用自动提交偏移量。
Auto Offset Reset:当没有初始偏移量或当前偏移量无效时,如何处理。
Maximum Poll Records:每次拉取的最大记录数。
Poll Interval:拉取间隔,以毫秒为单位。
3.2.

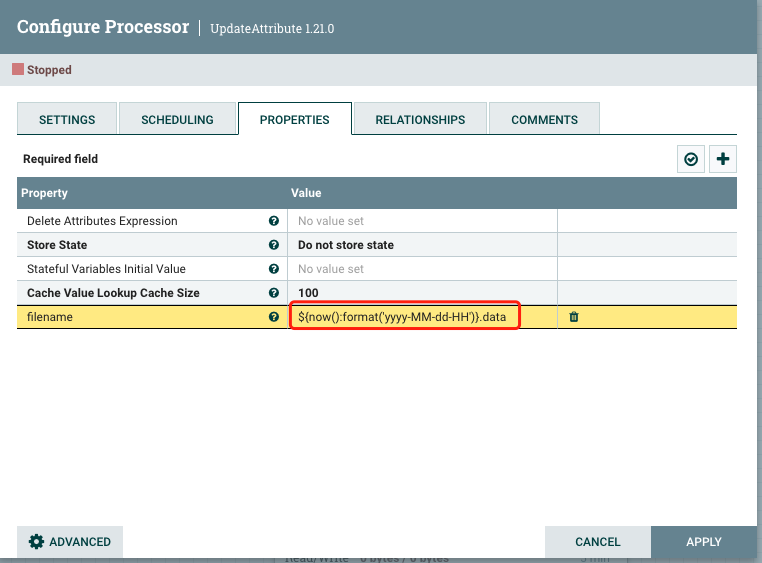
3.3.配置UpdateAttribute处理器
UpdateAttribute处理器配置一小时生成一个文件解决小文件问题
3.4.

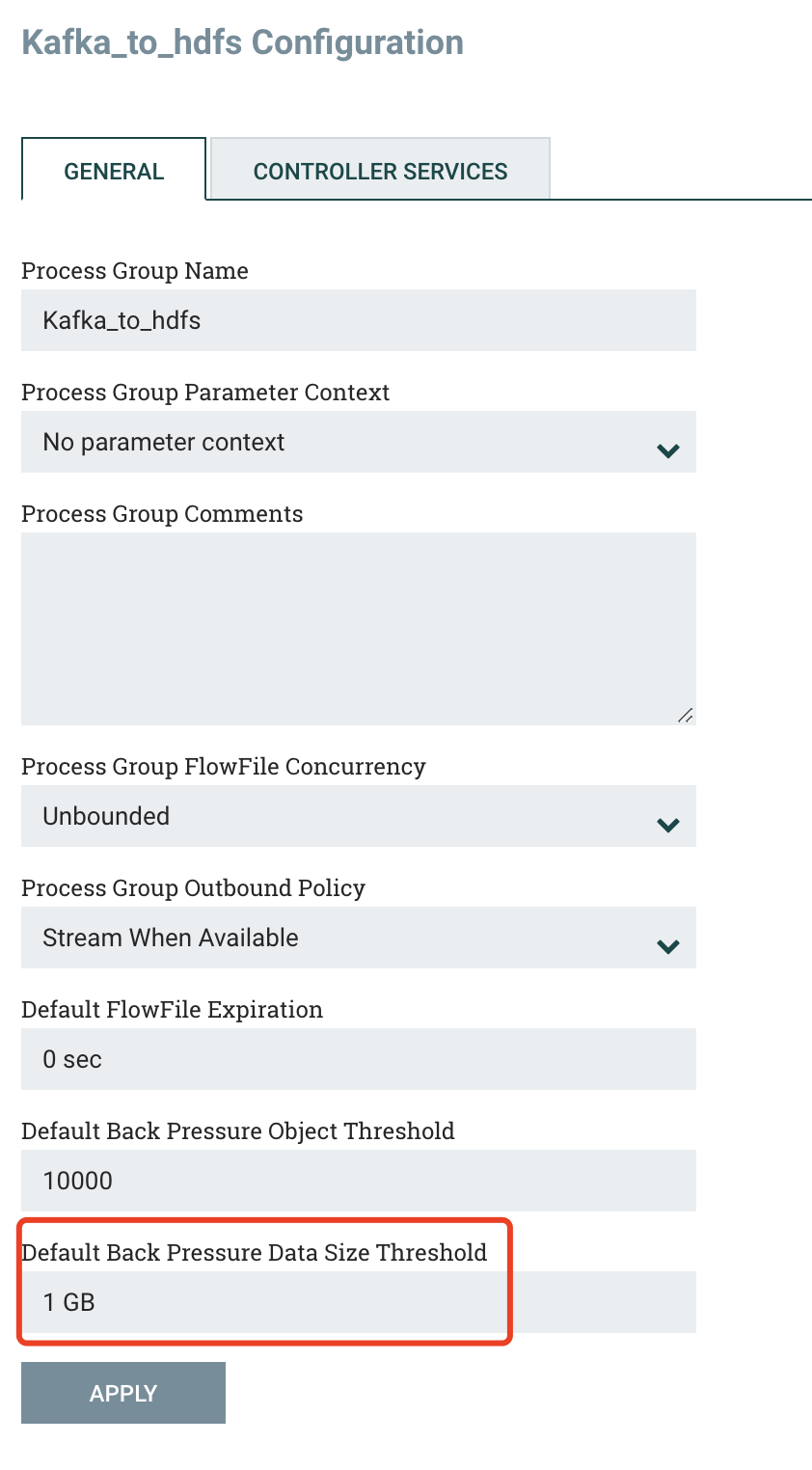
4.nifi 背压机制
NiFi的背压机制是一种自动调节流量的机制,用于避免数据流过快而导致系统崩溃或数据丢失的问题。当数据流过快时,NiFi会自动减缓数据的流动速度,以避免数据积压和丢失。具体来说,NiFi会在数据流进入某个处理器之前,检查该处理器的输入队列是否已满,如果已满,则会暂停数据流的输入,直到该队列中的数据被处理完成。这样可以保证系统在高负载时仍能正常运行,并且不会丢失数据。
nifi的背压机制配置是在组里面,默认配置是1G:
5.总结
nifi 非常重要的一个特点就是简单好用,对比其他数据同步的框架最大的优势就是有一个web ui,使用和调试都非常方便,可视化的页面也可以直观的看到数据在什么位置。
如果是一些特定的场景,比如监控mysql 里面实时变化的数据,就要使用专业的CDC工具来实现。
转载请注明:西门飞冰的博客 » nifi 的两个案例实操