需求:
公司的程序需要在后台跑一些脚本,有shell有php,需要持续不断的运行,如果脚本中断运行,需要自动启动,如果启动失败就发邮件/短信报警。
我们的监控是使用zabbix来做的,zabbix监控脚本后台运行和报警实现起来非常爽;但是做故障恢复就非常不爽了,谁用谁知道。下面我分享下我故障恢复是如何做的。
公司以前的监控方案
先说下我们之前的zabbix监控后台脚本是如何做的。然后在拿出改进后的方案和这个做对比。
说明:文档zabbix配置监控步骤有很多省略,主要是我们分享的不是zabbix监控而是故障恢复。大家不要在意细节我觉得大家能看这个文档的zabbix都是搞的比较溜得。
(1)首先写一个死循环脚本(测试使用)
[root@node1 ~]# cat while-true.sh #!/bin/bash while true; do echo a > /tmp/a.txt done
(2)写个脚本监控后台脚本是否正常运行。(这个脚本不需要运行在后台,而是zabbix隔指定时间来执行。)
在shell目录下创建监控进程的脚本;设置返回值,1表示不正常,0表示正常。
[root@node1 ~]# vim /shell/zabbix_api.sh #!/bin/sh ps -fe | grep $1 | grep -v grep | grep -v $0 >> /dev/null if [ $? -ne 0 ] then echo "1" else echo "0" fi
在zabbix客户端添加进程监控的UserParameter
[root@node1 ~]# vim /etc/zabbix/zabbix_agentd.d/api.conf UserParameter=api[*],/bin/sh /shell/zabbix_api.sh $1
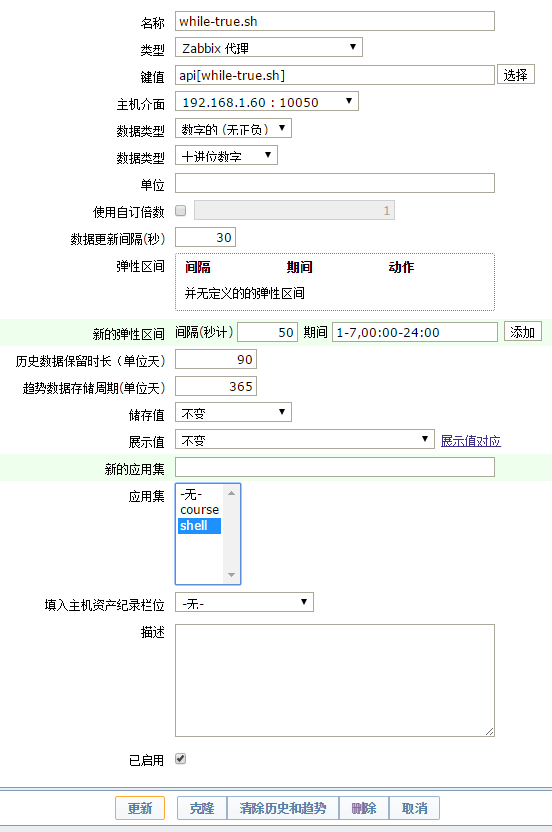
(3)Zabbix在对应的主机添加监控项。
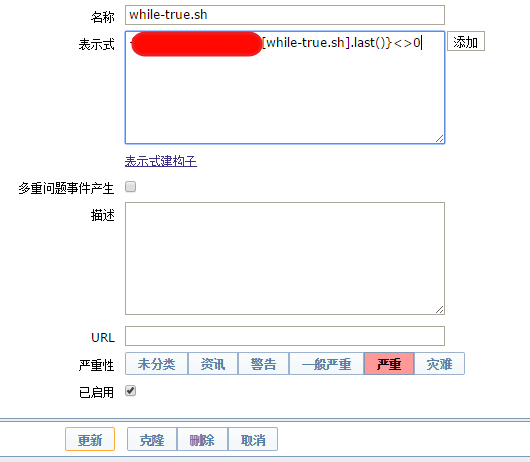
(4)触发器设置:脚本的返回值不为0表示,则触发报警策略
(5)报警验证(验证方法:手动修改触发器的返回值为不为1则脚本没有正常运行)
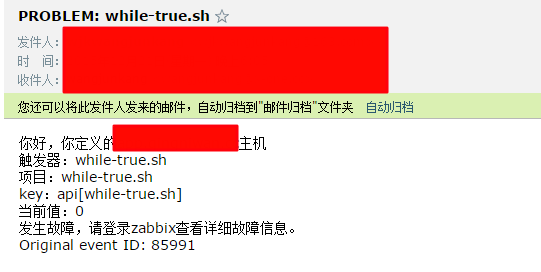
运维收到报警之后,就登录服务器排除故障。当然时间会是晚上,周末等等。然而就是上线启动一次服务而已,下面我们就实现后台脚本中断运行后,自动启动,启动失败给运维报警。这种报警一般都是那种手动启动也失败的故障了。
改进后的监控方案
改进后其实也没有改进太多东西,主要就是改进了我们判断进程是否在后台运行的脚本。
#!/bin/bash bin=/bin/sh script_file=while-true.sh script_path=/root/ ps -fe | grep $script_file | grep -v grep | grep -v $0 >> /dev/null if [ $? -ne 0 ];then nohup $bin $script_path$script_file >/dev/null 2>&1 & ps -fe | grep $script_file | grep -v grep | grep -v $0 >> /dev/null if [ $? -ne 0 ];then echo "1" else echo "0" fi else echo "0" fi
脚本内容:判断指定的进程是否在后台运行,如果在后台运行则返回0,如果后台没有则手动运行,如果手动运行之后还是没有,那么就返回1。
Zabbix执行脚本发现返回值为1,就会触发报警操作。
结束
以上仅为个人学习整理,水平有限,大神勿喷。分享的不是监控内容和脚本,主要是故障升级的思路,大家可以参考下我的思路,如果有更好的方法也可以提出。
转载请注明:西门飞冰的博客 » 自己写脚本实现zabbix报警升级