1.介绍
持久化的作用,供RDD的重复使用,针对计算耗时比较长,可以提高计算的效率,针对数据比较重要的数据保存到持久化中,数据的安全性也可以得到保障。

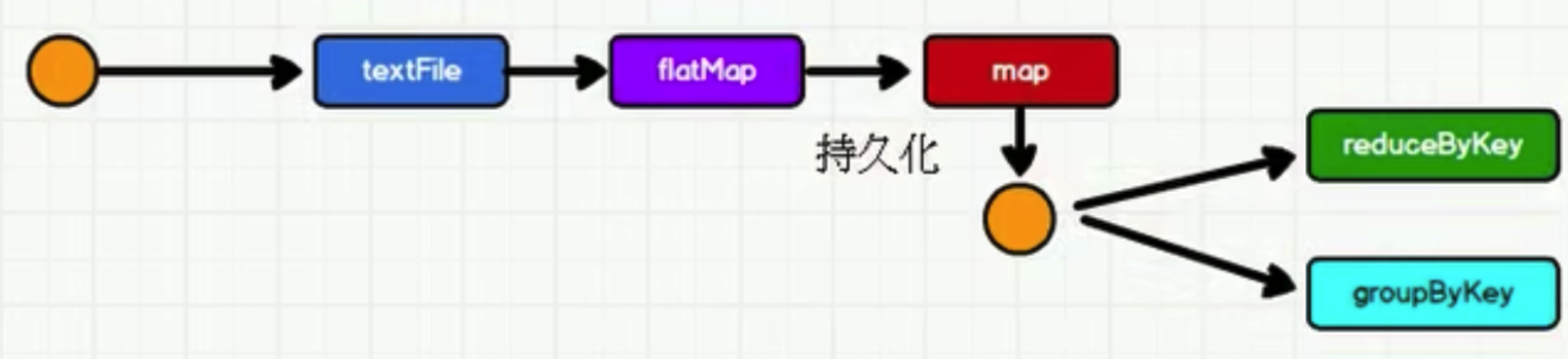
持久化操作是在行动算子执行时完成的。
注意:RDD中不存储数据,如果一个RDD需要重复使用,那么需要从头再次执行来获取数据,RDD对象可以重用的,但是数据无法重用
2.Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。
如果使用完了缓存,可以通过unpersist()方法释放缓存。
但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
代码实现:
public class Cache {
public static void main(String[] args) throws InterruptedException {
// 1 创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[2]");
// 2 创建SparkContext
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 3 编写代码
JavaRDD<String> lineRDD = sc.textFile("input/1.txt");
JavaRDD<String> flatMap = lineRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
String[] words = line.split(" ");
return Arrays.stream(words).iterator();
}
});
JavaRDD<String> filter = flatMap.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String word) throws Exception {
return !"".equals(word) && word != null;
}
});
JavaPairRDD<String, Integer> mapToPair = filter.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
// 数据缓存。
filter.cache();
// 数据缓存。
mapToPair.cache();
// persist方法可以更改存储级别
// cache底层调用的就是persist方法,缓存级别默认用的是MEMORY_ONLY
mapToPair.persist(StorageLevel.MEMORY_ONLY());
JavaPairRDD<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer sum, Integer elem) throws Exception {
return sum + elem;
}
});
// 触发执行逻辑
reduceByKey.collect();
JavaPairRDD<String, Iterable<Integer>> groupByKey = mapToPair.groupByKey();
// 再次触发执行逻辑
groupByKey.collect();
System.out.println(groupByKey.toDebugString());
Thread.sleep(999999);
// 4 关闭资源
sc.stop();
}
}
缓存结果验证:


查看血缘关系:
(2) MapPartitionsRDD[7] at groupByKey at Test01_cache.java:63 []
| ShuffledRDD[6] at groupByKey at Test01_cache.java:63 []
+-(2) MapPartitionsRDD[4] at mapToPair at Test01_cache.java:44 []
| CachedPartitions: 2; MemorySize: 145.9 MiB; DiskSize: 0.0 B // 表示缓存在内存中
| MapPartitionsRDD[3] at filter at Test01_cache.java:37 []
| CachedPartitions: 2; MemorySize: 103.6 MiB; DiskSize: 0.0 B
| MapPartitionsRDD[2] at flatMap at Test01_cache.java:29 []
| input/1.txt MapPartitionsRDD[1] at textFile at Test01_cache.java:27 []
| input/1.txt HadoopRDD[0] at textFile at Test01_cache.java:27 []
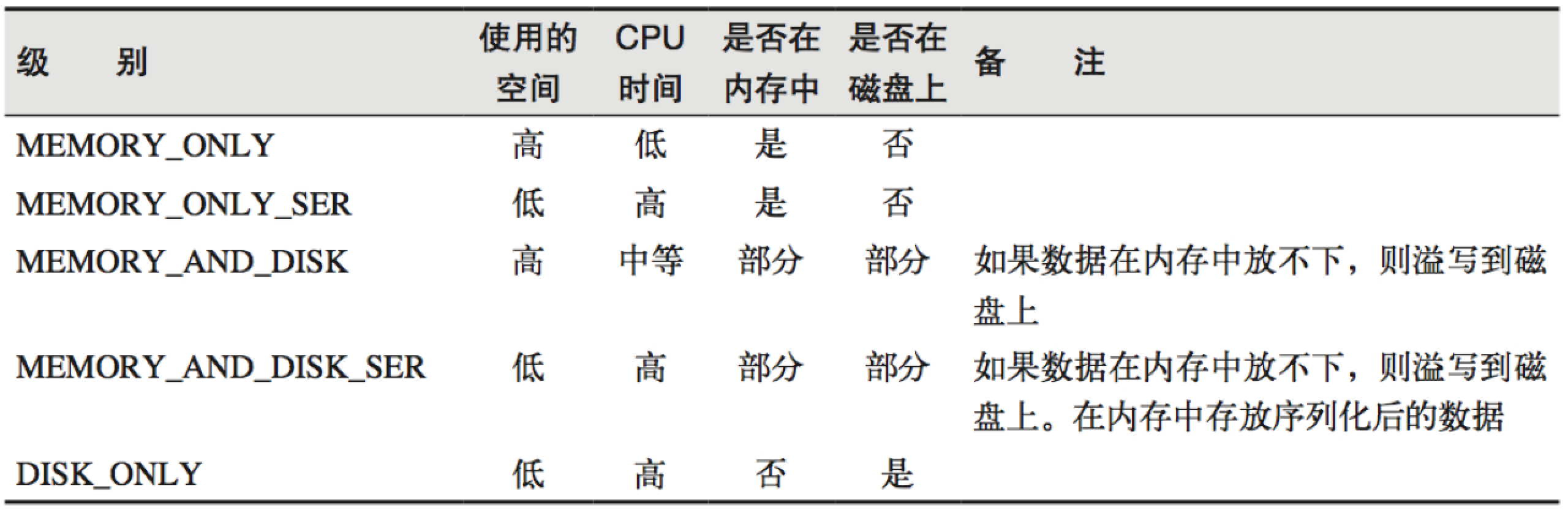
2.1.缓存的级别
注意:只有persist方法可以更改存储级别
默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上“_2”表示持久化的数据存为两份。SER:表示序列化。
存储级别源码:
object StorageLevel extends scala.AnyRef with scala.Serializable {
val NONE : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val DISK_ONLY : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val DISK_ONLY_2 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val DISK_ONLY_3 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_ONLY : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_ONLY_2 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_ONLY_SER : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_ONLY_SER_2 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_AND_DISK : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_AND_DISK_2 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_AND_DISK_SER : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val MEMORY_AND_DISK_SER_2 : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
val OFF_HEAP : org.apache.spark.storage.StorageLevel = { /* compiled code */ }
2.2.自带缓存算子
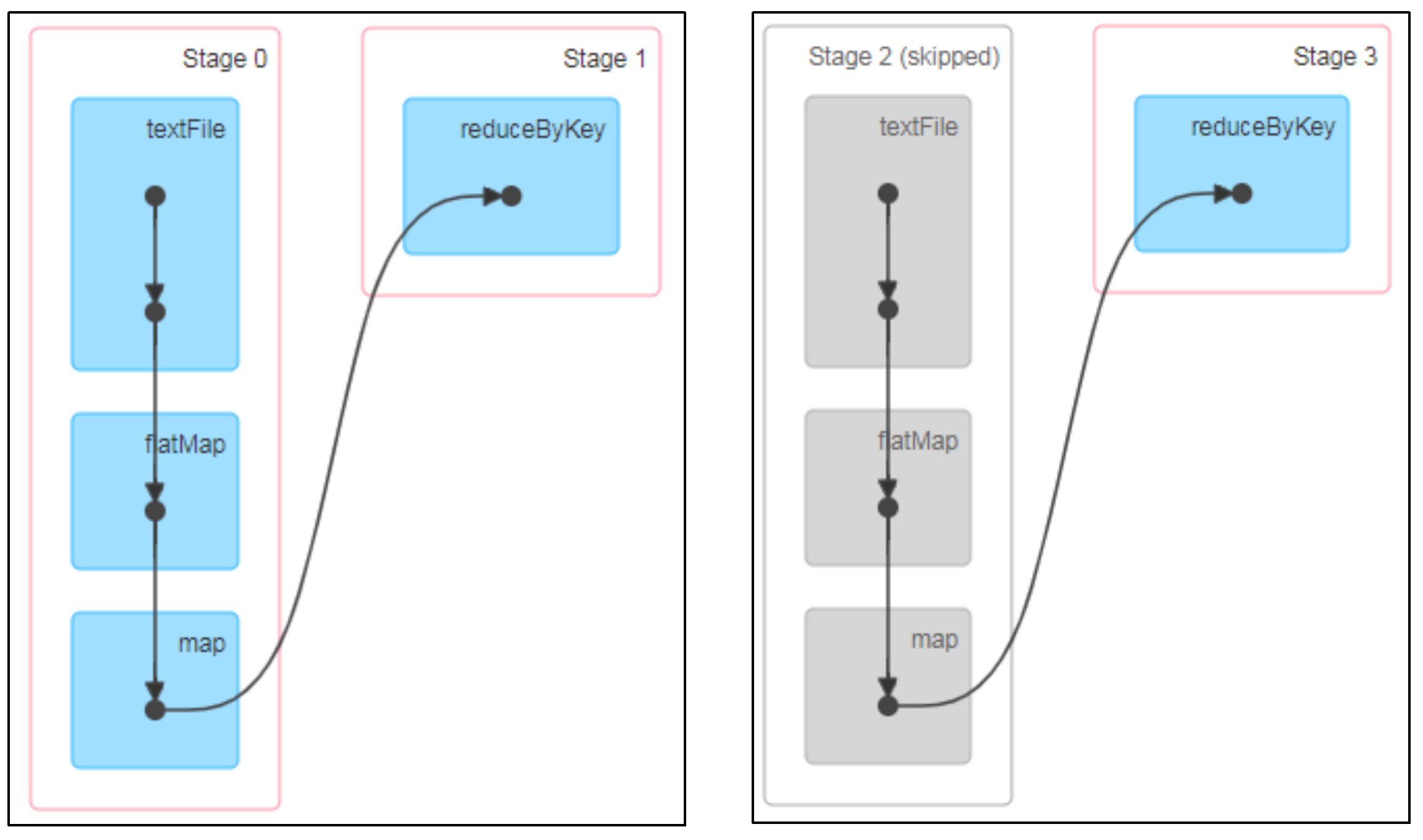
一些带shuffle的算子,会自带缓存
Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
如何确定算子自带缓存?
举例:查看下面第一个和第二个job的DAG图。说明:增加缓存后血缘依赖关系仍然有,但是,第二个job取的数据是从缓存中取的,所以Stage2 执行显示灰色
3.CheckPoint检查点
为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
检查点存储路径:Checkpoint的数据通常是存储在HDFS等容错、高可用的文件系统
检查点数据存储格式为:二进制的文件
检查点切断血缘:在Checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。
检查点触发时间:对RDD进行Checkpoint操作并不会马上被执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍。
建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
设置检查点步骤
(1)设置检查点数据存储路径:sc.setCheckpointDir(“./checkpoint1”)
(2)调用检查点方法:wordToOneRdd.checkpoint()
代码实现:
public class CheckPoint {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 设置检查点存储路径
sc.setCheckpointDir("ck");
// 3. 编写代码
JavaRDD<String> lineRDD = sc.textFile("input/2.txt");
JavaPairRDD<String, Long> tupleRDD = lineRDD.mapToPair(new PairFunction<String, String, Long>() {
@Override
public Tuple2<String, Long> call(String s) throws Exception {
return new Tuple2<String, Long>(s, System.currentTimeMillis());
}
});
// 查看血缘关系
System.out.println(tupleRDD.toDebugString());
// 增加检查点避免计算两次
tupleRDD.cache();
// 进行检查点
tupleRDD.checkpoint();
tupleRDD. collect().forEach(System.out::println);
System.out.println(tupleRDD.toDebugString());
// 第二次计算
tupleRDD. collect().forEach(System.out::println);
// 第三次计算
tupleRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
4.缓存和检查点区别
cache:
- 将数据临时存储在内存中进行数据重用
- 会在血缘关系中添加新的依赖。一旦出现问题,可以从头读取数据
persist:
- 将数据临时存储在磁盘文件中进行数据重用
- 涉及到磁盘IO,性能较低,但是数据安全
- 如果作业执行完成,临时保存的数据文件就会丢失
checkpoint:
- 将数据长久地保存在磁盘文件中进行数据重用
- 涉及到磁盘IO,性能较低,但是数据是安全的
- 为了保证数据安全,所以一般情况下,会独立执行作业
- 执行过程中,会切断血缘关系。重新建立新的血缘关系。因为读取数据的数据源发生了改变。
- checkpoint等同于新的数据源。