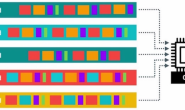
1.什么是缓存穿透
首先要做一个小科普,在日常开发中,无论使用进程内缓存(如:ehcache),还是进程外的缓存中间件(如:redis),他的本质就是利用内存的高吞吐的特性高效的完成数据的提取工作。因为底层mysql 在进行数据提取操作的时候是随机读写,性能比较慢。我们通常把热点数据放在内存缓存中来进行存储和提取。
应用程序一个基本的处理过程,首先是判断缓存中数据存不存在,如果存在直接从缓存中把数据提取出来就可以了;要是数据在缓存中不存在,就需要先去数据库查询,把数据提取出来,然后一边返回数据,一边把数据放入缓存中。这样第二次查询进来的时候,因为缓存中已经有数据了,所以就不用再向数据库查询数据了,通过缓存直接返回结果,就可以完成数据高效率的提取工作。这个就是缓存的一般性的处理过程。

缓存穿透攻击:是指恶意用户在短时内大量查询不存在的数据,导致大量请求被送达数据库进行查询,当请求数量超过数据库负载上限时,使系统响应出现高延迟甚至瘫痪的攻击行为。
比如:请求id携带-1信息,请求超大id信息等
2.怎么预防缓存穿透
1、IP过滤; 2、参数校验; 3、布隆过滤器;
下面我们看一下布隆过滤器解决方案实现。
3.什么是布隆过滤器
布隆过滤器:是巴顿.布隆于一九七零年提出的,其主旨是采用一个很长的二进制数组,通过一系列的Hash函数来确定该数据是否存在。
布隆过滤器本质上是一个N位的二进制数组,都知道二进制只有0和1来进行表示,针对当前的场景模拟了一个二进制数据,每一位的初始值都是0。
3.1.

假设当前我们有1000个数据,编号分别是1~1000,作为布隆过滤器在初始化的时候,实际上就是对每一个数据编号进行若干次的hash,来确定它们的位置。
比如针对当前1这个编号,我们对其执行了三次hash,所谓hash函数,就是将数据代入以后,确定一个具体的位置。
这里编号1计算完成后,确定了存储的位置是数组索引的1,5,99,并将索引的值从0修改为1

编号1计算完成后,就要编号2来计算了,编号2经过3次hash以后,分别定位到数组索引的1,3,98,数组索引1,因为刚才已经修改成了1,所以他的值不变,数组索引3和98从0变成1。
hash规则:如果在hash后原始位数据是0的话,将其从0变为1,如果本身这一位就是1的话,则保持不变。


3.2.布隆过滤器判断流程
布隆过滤器初始化完成之后,该怎么去使用呢?
看一个已存在的数据判断流程
某一个用户要查询858编号的数据,按照原始的三次hash,分别定位到了1,5,98号数组索引位,当每一位的hash数值都是1的时候,则代表对应的编号是存在的。

看一个不存在的数据判断流程
当用户查询8888编号的数据,经过三次hash,分别定位到了3,6,100号数组索引位,此时索引为100的数值是0。在多次hash是有任意一位数组索引位是0,则代表数据不存在。

总结:如果布隆过滤器所有hash位的值都是1则这个数据可能存在,但是某一位数值是0的话,数据是一定不存在的。
3.3.布隆过滤器的误判情况
布隆过滤器在设计之初就不是一个精确的判断,布隆过滤器存在一定的误判率。
比如用户查询8889的情况,经过hash三次查询,正好每一位上都是1。尽管这个编号数据在数据库中是不存在的,但是在布隆过滤器中,他会被判定为存在。这就是布隆过滤器中会出现的小概率误判情况。

如何减少误判的发生:
1、增加二进制数组位数:如100位数组索引,扩大到10000位
2、增加Hash次数:如3次hash扩大到5次hash
减少误判的代价就是CPU需要更多的运算,会让布隆过滤器的性能降低。
4.Java 使用布隆过滤器
布隆过滤器这种50多岁的经典算法,已经被java进行了封装和集成。在java中提供了一个redisson的组件,这个组件内置了布隆过滤器并存储在redis服务器中,可以让程序员非常简单和直接的设置布隆过滤器。
1、引入Maven依赖
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-all</artifactId> <version>3.16.0</version> </dependency>
2、Java运用布隆过滤器
Config config = new Config();
//设置redis地址
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("bloom");
//初始化布隆过滤器:初始化长度为1000000L,误判率为1%
bloomFilter.tryInit(1000000L,0.01);
bloomFilter.add("1"); //增加数据
//判断指定编号是否在布隆过滤器中
System.out.println(bloomFilter.contains("1")); //输出true
System.out.println(bloomFilter.contains("8888"));//输出false
这里设置1%的误判率不算不会对系统产生很大的影响,要是碰到缓存穿透攻击,1万个请求到达数据库层面的也就只有100个,这些漏网请求也不会对系统产生实质性影响
5.

6.数据被删除了怎么办
布隆过滤器因为某一位二进制可能被多个编号Hash引用,因此布隆过滤器无法直接处理删除数据的情况。
解决方案1:定时异步重建布隆过滤器
比如每过一个小时,异步的执行一个任务调度,来重新生成布隆过滤器,替换掉已有的布隆过滤器。
解决方案2:计数Bloom Fliter
在标准的布隆过滤器下是无法得知当前某一位索引,是被那些具体数据引用的。但是计数布隆过滤器,他是在这一位上额外附加了计数信息,表达了该位被几个数据引用。删除数据的同时相应的计数信息减1,就完成了布隆过滤器数据的删除。
转载请注明:西门飞冰的博客 » 布隆过滤器解决缓存穿透问题