1.场景介绍
在大数据业务采集场景中,经常会通过Flume把Kafka中的数据落地到HDFS进行持久保存和数据计算。为了数据计算和运维方便,通常会把每天的数据在HDFS通过天分区独立存储。
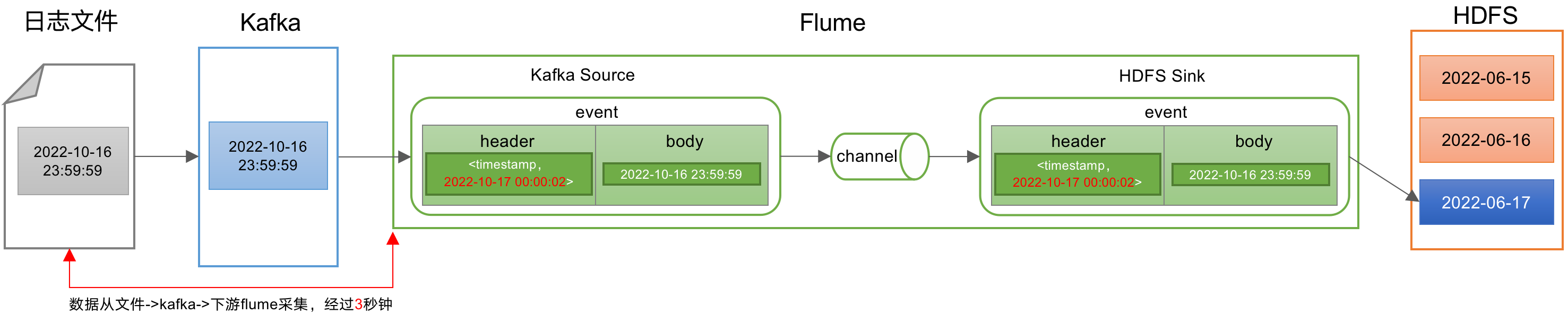
在数据落入HDFS 天分区目录的过程中,会出现数据跨天存储的问题,本来是2022年6月16日的数据,结果存储到了2022年6月17日的目录。这就是数据漂移。
下面就来分析一下数据漂移产生的原因和解决办法。
2.数据漂移问题产生原因
(1)数据落地到磁盘文件会产生数据的时间,这个时间是业务实际的时间
(2)数据通过采集工具收集到Kafka 会有一定的时间间隔
(3)flume 从Kafka 消费数据,也会有一定的时间间隔,并且flume消费Kafka数据会把当前消费数据的具体时间记录到自己event的header中,这个时间和业务实际时间一定是存在一定长短的不同的。
(4)Flume HDFS Sink默认基于Flume event当中的timestamp时间戳落盘,这个时候要是Flume event时间和业务时间跨天就产生了数据漂移。
3.如何解决数据漂移问题
既然知道了数据漂移问题产生的原因是:业务数据实际时间和Flume event时间不同。
那我们就可以用 Flume 提供的自定义拦截器,来对event中的数据进行ETL处理。通过自己编写拦截器代码将Flume event body中的时间戳赋值给Flume header中的时间戳。
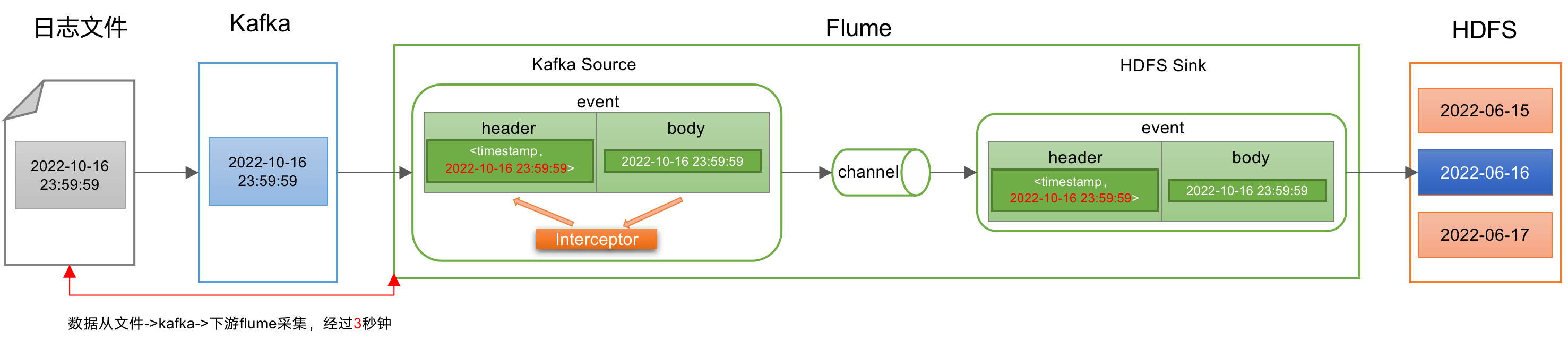
注意:Flume 拦截器是针对source添加的,要是没有source就不能添加拦截器。
所以从Flume 从 Kafka读取数据落地HDFS,处理流程必须是Flume Kafka Source,不能是Flume kafka channel。
4.拦截器代码
日志格式说明:我这边业务输出的日志格式为json格式,时间字段存在ts字段中。不同的日志格式需要解析的代码不同。
1、Maven 依赖配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<!--因为部署的flume 有flume-ng-core这个包,所以使用provided过滤掉-->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<!--引入打包插件,将外部包(fastjson)打进jar包里面-->
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、自定义拦截器代码
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1 获取header和body
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
Map<String, String> headers = event.getHeaders();
//2 解析body获取ts字段,放到header的timestamp字段当中
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()) {
Event event = iterator.next();
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
3、将程序进行打包,并上传到flume服务器lib目录下吗
5.
# vim conf/kafka_to_hdfs_log.conf #定义组件 a1.sources=r1 a1.channels=c1 a1.sinks=k1 #配置source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = kafka01:9092,kafka02:9092,kafka03:9092 a1.sources.r1.kafka.topics=kafka_log # 添加自定义的flume拦截器类 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.fblinux.flume.log.TimestampInterceptor$Builder #配置channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1 a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6 #配置sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /data/log/kafka_log/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = log a1.sinks.k1.hdfs.round = false a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 #控制输出文件类型 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = gzip #组装 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
转载请注明:西门飞冰的博客 » Flume自定义拦截器解决数据漂移问题