Atlas介绍
Apache atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。
核心组件
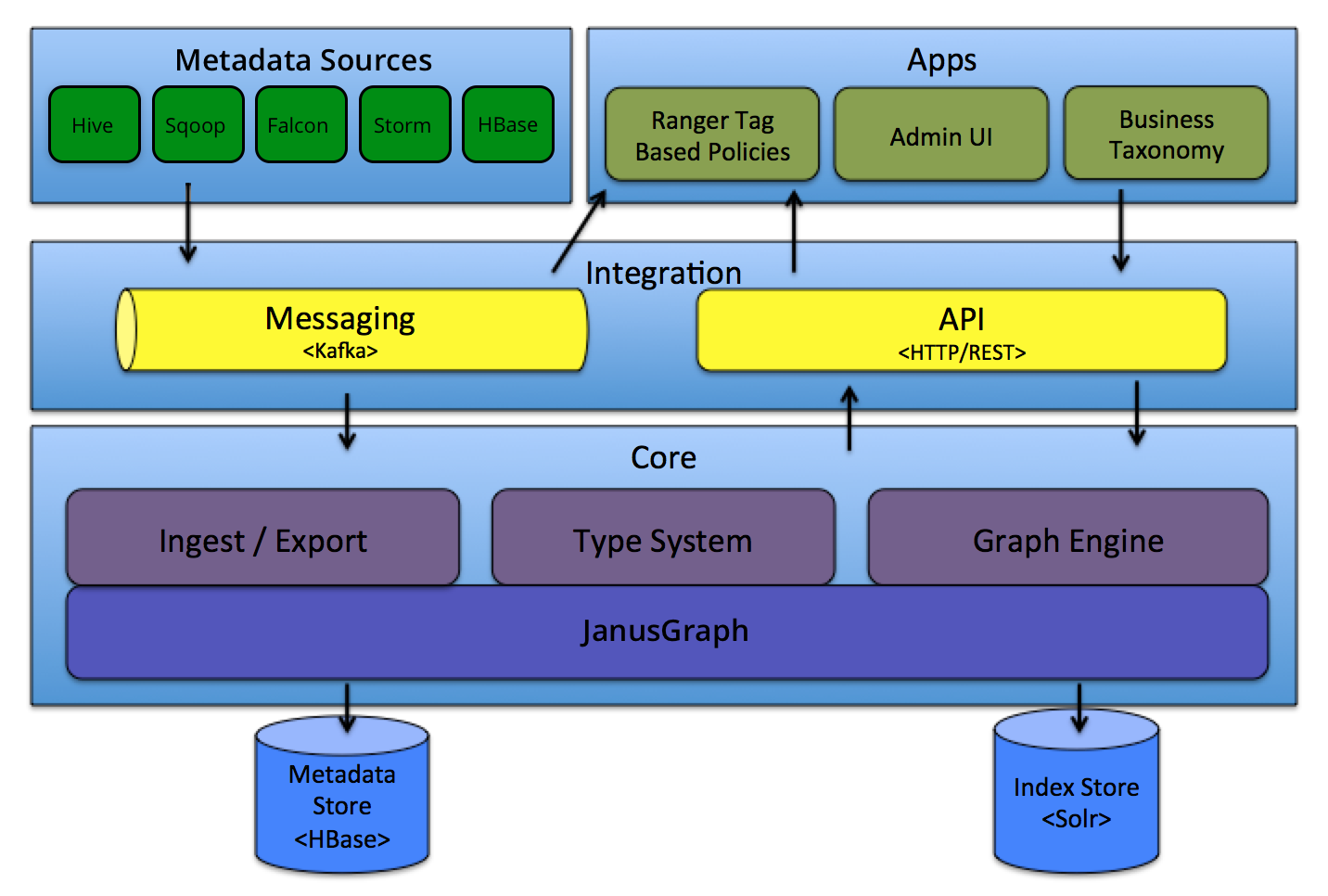
core
Ingest/Export:Ingest 组件允许将元数据添加到 Atlas。类似地,Export 组件暴露由 Atlas 检测到的元数据更改,以作为事件引发,消费者可以使用这些更改事件来实时响应元数据更改。
Type System: Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 “类型” 的定义组成。”类型” 的 实例被称为 “实体” 表示被管理的实际元数据对象。类型系统是一个组件,允许用户定义和管理类型和实体。由 Atlas 管理的所有元数据对象(例如Hive表)都使用类型进行建模,并表示为实体。要在 Atlas 中存储新类型的元数据,需要了解类型系统组件的概念。
Graph Engine:在内部,Atlas 通过使用图形模型管理元数据对象。以实现元数据对象之间的巨大灵活性和丰富的关系。图形引擎是负责在类型系统的类型和实体之间进行转换的组件,以及基础图形模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便有效地搜索它们。
Titan:目前,Atlas 使用 Titan 图数据库来存储元数据对象。 Titan 使用两个存储:默认情况下元数据存储配置为 HBase ,索引存储配置为 Solr。也可以通过构建相应的配置文件使用BerkeleyDB存储元数据存储 和使用ElasticSearch存储 Index。元数据存储用于存储元数据对象本身,索引存储用于存储元数据属性的索引,其允许高效搜索。
Integration
用户可以使用两种方法管理 Atlas 中的元数据:
API:Atlas 的所有功能都可以通过 REST API 提供给最终用户,允许创建,更新和删除类型和实体。它也是查询和发现通过 Atlas 管理的类型和实体的主要方法。
Messaging:除了 API 之外,用户还可以选择使用基于 Kafka 的消息接口与 Atlas 集成。这对于将元数据对象传输到 Atlas 以及从 Atlas 使用可以构建应用程序的元数据更改事件都非常有用。如果希望使用与 Atlas 更松散耦合的集成,这可以允许更好的可扩展性,可靠性等,消息传递接口是特别有用的。Atlas 使用 Apache Kafka 作为通知服务器用于钩子和元数据通知事件的下游消费者之间的通信。事件由钩子(hook)和 Atlas 写到不同的 Kafka 主题:
ATLAS_HOOK: 来自 各个组件的Hook 的元数据通知事件通过写入到名为 ATLAS_HOOK 的 Kafka topic 发送到 Atlas
ATLAS_ENTITIES:从 Atlas 到其他集成组件(如Ranger)的事件写入到名为 ATLAS_ENTITIES 的 Kafka topic
Metadata source
Atlas 支持与许多元数据源的集成,将来还会添加更多集成。目前,Atlas 支持从以下数据源获取和管理元数据:
Hive:通过hive bridge, atlas可以接入Hive的元数据,包括hive_db/hive_table/hive_column/hive_process
Sqoop:通过sqoop bridge,atlas可以接入关系型数据库的元数据,包括sqoop_operation_type/ sqoop_dbstore_usage/sqoop_process/sqoop_dbdatastore
Falcon:通过falcon bridge,atlas可以接入Falcon的元数据,包括falcon_cluster/falcon_feed/falcon_feed_creation/falcon_feed_replication/ falcon_process
Storm:通过storm bridge,atlas可以接入流式处理的元数据,包括storm_topology/storm_spout/storm_bolt
Atlas集成大数据组件的元数据源需要实现以下两点:
首先,需要基于atlas的类型系统定义能够表达大数据组件元数据对象的元数据模型(例如Hive的元数据模型实现在org.apache.atlas.hive.model.HiveDataModelGenerator);
然后,需要提供hook组件去从大数据组件的元数据源中提取元数据对象,实时侦听元数据的变更并反馈给atlas;
Applications
Ranger Tag Based Policies: Apache Ranger 是针对 Hadoop 生态系统的高级安全管理解决方案,与各种 Hadoop 组件具有广泛的集成。通过与 Atlas 集成,Ranger 允许安全管理员定义元数据驱动的安全策略,以实现有效的治理。 Ranger 是由 Atlas 通知的元数据更改事件的消费者。
Atlas Admin UI: 该组件是一个基于 Web 的应用程序,允许数据管理员和科学家发现和注释元数据。Admin UI提供了搜索界面和 类SQL的查询语言,可以用来查询由 Atlas 管理的元数据类型和对象。Admin UI 使用 Atlas 的 REST API 来构建其功能。
Business Taxonomy:从元数据源获取到 Atlas 的元数据对象主要是一种技术形式的元数据。为了增强可发现性和治理能力,Atlas 提供了一个业务分类界面,允许用户首先定义一组代表其业务域的业务术语,并将其与 Atlas 管理的元数据实体相关联。业务分类法是一种 Web 应用程序,目前是 Atlas Admin UI 的一部分,并且使用 REST API 与 Atlas 集成。
在HDP2.5中,Business Taxonomy是提供了Technical Preview版本,需要在Atlas > Configs > Advanced > Custom application-properties中添加atlas.feature.taxonomy.enable=true并重启atlas服务来开启
编译安装
依赖环境
本文atlas环境部署,基于如下CDH环境
1、部署的服务

2、服务分布的节点

atlas 源码下载
在编译主机上下载atlas源码
# git clone -b release-2.1.0-rc3 https://github.com/apache/atlas.git
atlas 源码编译
注意:atlas 使用maven进行编译,maven版本最低3.5
1、修改pom文件
因与CDH 6.2.0集成,在repositories中新增以下部分:
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
修改CDH对应的版本
<lucene-solr.version>7.4.0-cdh6.2.0</lucene-solr.version> <hadoop.version>3.0.0-cdh6.2.0</hadoop.version> <hbase.version>2.1.0-cdh6.2.0</hbase.version> <solr.version>7.4.0-cdh6.2.0</solr.version> <hive.version>2.1.1-cdh6.2.0</hive.version> <kafka.version>2.1.0-cdh6.2.0</kafka.version> <kafka.scala.binary.version>2.11</kafka.scala.binary.version> <zookeeper.version>3.4.5-cdh6.2.0</zookeeper.version> <sqoop.version>1.4.7-cdh6.2.0</sqoop.version>
2、为了兼容hive2.1.1版本,修改atlas源代码
# vim addons/hive-bridge/src/main/java/org/apache/atlas/hive/bridge/HiveMetaStoreBridge.java 577行 String catalogName = hiveDB.getCatalogName() != null ? hiveDB.getCatalogName().toLowerCase() : null; 改为: String catalogName = null; # vim addons/hive-bridge/src/main/java/org/apache/atlas/hive/hook/AtlasHiveHookContext.java 81行 this.metastoreHandler = (listenerEvent != null) ? metastoreEvent.getIHMSHandler() : null; 改为: this.metastoreHandler = null;
3、编译
mvn clean -DskipTests package -Pdist -X
编译完成提示如下:
编译完成的文件在此目录distro/target
Atlas 安装
将安装包解压到安装目录
tar -zxvf distro/target/apache-atlas-2.1.0-bin.tar.gz -C /opt/
修改atlas-env.sh配置文件
# vim conf/atlas-env.sh export MANAGE_LOCAL_HBASE=false export MANAGE_LOCAL_SOLR=false export MANAGE_EMBEDDED_CASSANDRA=false export MANAGE_LOCAL_ELASTICSEARCH=false export HBASE_CONF_DIR=/etc/hbase/conf
修改atlas-application.properties配置文件
# cat conf/atlas-application.properties
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######### Graph Database Configs #########
# Graph Database
#Configures the graph database to use. Defaults to JanusGraph
#atlas.graphdb.backend=org.apache.atlas.repository.graphdb.janus.AtlasJanusGraphDatabase
# Graph Storage
# Set atlas.graph.storage.backend to the correct value for your desired storage
# backend. Possible values:
#
# hbase
# cassandra
# embeddedcassandra - Should only be set by building Atlas with -Pdist,embedded-cassandra-solr
# berkeleyje
#
# See the configuration documentation for more information about configuring the various storage backends.
#
atlas.graph.storage.backend=hbase
atlas.graph.storage.hbase.table=apache_atlas_janus
${graph.storage.properties}
#Hbase
#For standalone mode , specify localhost
#for distributed mode, specify zookeeper quorum here
atlas.graph.storage.hostname=ck-01:2181,ck-02:2181,ck-03:2181
atlas.graph.storage.hbase.regions-per-server=1
atlas.graph.storage.lock.wait-time=10000
#In order to use Cassandra as a backend, comment out the hbase specific properties above, and uncomment the
#the following properties
#atlas.graph.storage.clustername=
#atlas.graph.storage.port=
# Gremlin Query Optimizer
#
# Enables rewriting gremlin queries to maximize performance. This flag is provided as
# a possible way to work around any defects that are found in the optimizer until they
# are resolved.
#atlas.query.gremlinOptimizerEnabled=true
# Delete handler
#
# This allows the default behavior of doing "soft" deletes to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.store.graph.v1.SoftDeleteHandlerV1 - all deletes are "soft" deletes
# org.apache.atlas.repository.store.graph.v1.HardDeleteHandlerV1 - all deletes are "hard" deletes
#
#atlas.DeleteHandlerV1.impl=org.apache.atlas.repository.store.graph.v1.SoftDeleteHandlerV1
${entity.repository.properties}
# Entity audit repository
#
# This allows the default behavior of logging entity changes to hbase to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.audit.HBaseBasedAuditRepository - log entity changes to hbase
# org.apache.atlas.repository.audit.CassandraBasedAuditRepository - log entity changes to cassandra
# org.apache.atlas.repository.audit.NoopEntityAuditRepository - disable the audit repository
#
atlas.EntityAuditRepository.impl=org.apache.atlas.repository.audit.HBaseBasedAuditRepository
# if Cassandra is used as a backend for audit from the above property, uncomment and set the following
# properties appropriately. If using the embedded cassandra profile, these properties can remain
# commented out.
# atlas.EntityAuditRepository.keyspace=atlas_audit
# atlas.EntityAuditRepository.replicationFactor=1
# Graph Search Index
${graph.index.properties}
atlas.graph.index.search.backend=solr
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=ck-01:2181/solr,ck-02:2181/solr,ck-03:2181/solr
atlas.graph.index.search.solr.zookeeper-connect-timeout=60000
atlas.graph.index.search.solr.zookeeper-session-timeout=60000
#Solr http mode properties
#atlas.graph.index.search.solr.mode=http
#atlas.graph.index.search.solr.http-urls=http://localhost:8983/solr
# ElasticSearch support (Tech Preview)
# Comment out above solr configuration, and uncomment the following two lines. Additionally, make sure the
# hostname field is set to a comma delimited set of elasticsearch master nodes, or an ELB that fronts the masters.
#
# Elasticsearch does not provide authentication out of the box, but does provide an option with the X-Pack product
# https://www.elastic.co/products/x-pack/security
#
# Alternatively, the JanusGraph documentation provides some tips on how to secure Elasticsearch without additional
# plugins: https://docs.janusgraph.org/latest/elasticsearch.html
#atlas.graph.index.search.hostname=localhost
#atlas.graph.index.search.elasticsearch.client-only=true
# Solr-specific configuration property
atlas.graph.index.search.max-result-set-size=150
######### Import Configs #########
#atlas.import.temp.directory=/temp/import
######### Notification Configs #########
atlas.notification.embedded=false
atlas.kafka.data=${sys:atlas.home}/data/kafka
atlas.kafka.zookeeper.connect=ck-01:2181,ck-02:2181,ck-03:2181
atlas.kafka.bootstrap.servers=ck-01:9092,ck-02:9092,ck-03:9092
atlas.kafka.zookeeper.session.timeout.ms=60000
atlas.kafka.zookeeper.connection.timeout.ms=30000
atlas.kafka.zookeeper.sync.time.ms=20
atlas.kafka.auto.commit.interval.ms=1000
atlas.kafka.hook.group.id=atlas
atlas.kafka.enable.auto.commit=false
atlas.kafka.auto.offset.reset=earliest
atlas.kafka.session.timeout.ms=30000
atlas.kafka.offsets.topic.replication.factor=1
atlas.kafka.poll.timeout.ms=1000
atlas.notification.create.topics=true
atlas.notification.replicas=1
atlas.notification.topics=ATLAS_HOOK,ATLAS_ENTITIES
atlas.notification.log.failed.messages=true
atlas.notification.consumer.retry.interval=500
atlas.notification.hook.retry.interval=1000
# Enable for Kerberized Kafka clusters
#atlas.notification.kafka.service.principal=kafka/_HOST@EXAMPLE.COM
#atlas.notification.kafka.keytab.location=/etc/security/keytabs/kafka.service.keytab
## Server port configuration
#atlas.server.http.port=21000
#atlas.server.https.port=21443
######### Security Properties #########
# SSL config
atlas.enableTLS=false
#truststore.file=/path/to/truststore.jks
#cert.stores.credential.provider.path=jceks://file/path/to/credentialstore.jceks
#following only required for 2-way SSL
#keystore.file=/path/to/keystore.jks
# Authentication config
atlas.authentication.method.kerberos=false
atlas.authentication.method.file=true
#### ldap.type= LDAP or AD
atlas.authentication.method.ldap.type=none
#### user credentials file
atlas.authentication.method.file.filename=${sys:atlas.home}/conf/users-credentials.properties
### groups from UGI
#atlas.authentication.method.ldap.ugi-groups=true
######## LDAP properties #########
#atlas.authentication.method.ldap.url=ldap://<ldap server url>:389
#atlas.authentication.method.ldap.userDNpattern=uid={0},ou=People,dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchBase=dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchFilter=(member=uid={0},ou=Users,dc=example,dc=com)
#atlas.authentication.method.ldap.groupRoleAttribute=cn
#atlas.authentication.method.ldap.base.dn=dc=example,dc=com
#atlas.authentication.method.ldap.bind.dn=cn=Manager,dc=example,dc=com
#atlas.authentication.method.ldap.bind.password=<password>
#atlas.authentication.method.ldap.referral=ignore
#atlas.authentication.method.ldap.user.searchfilter=(uid={0})
#atlas.authentication.method.ldap.default.role=<default role>
######### Active directory properties #######
#atlas.authentication.method.ldap.ad.domain=example.com
#atlas.authentication.method.ldap.ad.url=ldap://<AD server url>:389
#atlas.authentication.method.ldap.ad.base.dn=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.bind.dn=CN=team,CN=Users,DC=example,DC=com
#atlas.authentication.method.ldap.ad.bind.password=<password>
#atlas.authentication.method.ldap.ad.referral=ignore
#atlas.authentication.method.ldap.ad.user.searchfilter=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.default.role=<default role>
######### JAAS Configuration ########
#atlas.jaas.KafkaClient.loginModuleName = com.sun.security.auth.module.Krb5LoginModule
#atlas.jaas.KafkaClient.loginModuleControlFlag = required
#atlas.jaas.KafkaClient.option.useKeyTab = true
#atlas.jaas.KafkaClient.option.storeKey = true
#atlas.jaas.KafkaClient.option.serviceName = kafka
#atlas.jaas.KafkaClient.option.keyTab = /etc/security/keytabs/atlas.service.keytab
#atlas.jaas.KafkaClient.option.principal = atlas/_HOST@EXAMPLE.COM
######### Server Properties #########
atlas.rest.address=http://10.1.14.91:21000
# If enabled and set to true, this will run setup steps when the server starts
#atlas.server.run.setup.on.start=false
######### Entity Audit Configs #########
atlas.audit.hbase.tablename=apache_atlas_entity_audit
atlas.audit.zookeeper.session.timeout.ms=1000
atlas.audit.hbase.zookeeper.quorum=ck-01:2181,ck-02:2181,ck-03:2181
#Hive
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
######### High Availability Configuration ########
atlas.server.ha.enabled=false
#### Enabled the configs below as per need if HA is enabled #####
#atlas.server.ids=id1
#atlas.server.address.id1=localhost:21000
#atlas.server.ha.zookeeper.connect=localhost:2181
#atlas.server.ha.zookeeper.retry.sleeptime.ms=1000
#atlas.server.ha.zookeeper.num.retries=3
#atlas.server.ha.zookeeper.session.timeout.ms=20000
## if ACLs need to be set on the created nodes, uncomment these lines and set the values ##
#atlas.server.ha.zookeeper.acl=<scheme>:<id>
#atlas.server.ha.zookeeper.auth=<scheme>:<authinfo>
######### Atlas Authorization #########
atlas.authorizer.impl=simple
atlas.authorizer.simple.authz.policy.file=atlas-simple-authz-policy.json
######### Type Cache Implementation ########
# A type cache class which implements
# org.apache.atlas.typesystem.types.cache.TypeCache.
# The default implementation is org.apache.atlas.typesystem.types.cache.DefaultTypeCache which is a local in-memory type cache.
#atlas.TypeCache.impl=
######### Performance Configs #########
#atlas.graph.storage.lock.retries=10
#atlas.graph.storage.cache.db-cache-time=120000
######### CSRF Configs #########
atlas.rest-csrf.enabled=true
atlas.rest-csrf.browser-useragents-regex=^Mozilla.*,^Opera.*,^Chrome.*
atlas.rest-csrf.methods-to-ignore=GET,OPTIONS,HEAD,TRACE
atlas.rest-csrf.custom-header=X-XSRF-HEADER
############ KNOX Configs ################
#atlas.sso.knox.browser.useragent=Mozilla,Chrome,Opera
#atlas.sso.knox.enabled=true
#atlas.sso.knox.providerurl=https://<knox gateway ip>:8443/gateway/knoxsso/api/v1/websso
#atlas.sso.knox.publicKey=
############ Atlas Metric/Stats configs ################
# Format: atlas.metric.query.<key>.<name>
atlas.metric.query.cache.ttlInSecs=900
#atlas.metric.query.general.typeCount=
#atlas.metric.query.general.typeUnusedCount=
#atlas.metric.query.general.entityCount=
#atlas.metric.query.general.tagCount=
#atlas.metric.query.general.entityDeleted=
#
#atlas.metric.query.entity.typeEntities=
#atlas.metric.query.entity.entityTagged=
#
#atlas.metric.query.tags.entityTags=
######### Compiled Query Cache Configuration #########
# The size of the compiled query cache. Older queries will be evicted from the cache
# when we reach the capacity.
#atlas.CompiledQueryCache.capacity=1000
# Allows notifications when items are evicted from the compiled query
# cache because it has become full. A warning will be issued when
# the specified number of evictions have occurred. If the eviction
# warning threshold <= 0, no eviction warnings will be issued.
#atlas.CompiledQueryCache.evictionWarningThrottle=0
######### Full Text Search Configuration #########
#Set to false to disable full text search.
#atlas.search.fulltext.enable=true
######### Gremlin Search Configuration #########
#Set to false to disable gremlin search.
atlas.search.gremlin.enable=false
########## Add http headers ###########
#atlas.headers.Access-Control-Allow-Origin=*
#atlas.headers.Access-Control-Allow-Methods=GET,OPTIONS,HEAD,PUT,POST
#atlas.headers.<headerName>=<headerValue>
######### UI Configuration ########
atlas.ui.default.version=v1
# whether to run the hook synchronously. false recommended to avoid delays in Sqoop operation completion. Default: false
atlas.hook.sqoop.synchronous=false
# number of retries for notification failure. Default: 3
atlas.hook.sqoop.numRetries=3
# queue size for the threadpool. Default: 10000
atlas.hook.sqoop.queueSize=10000
atlas.kafka.metric.reporters=org.apache.kafka.common.metrics.JmxReporter
atlas.kafka.client.id=sqoop-atlas
修改log4j文件,去掉如下代码注释
# vim atlas-log4j.xml
<!-- Uncomment the following for perf logs -->
<appender name="perf_appender" class="org.apache.log4j.DailyRollingFileAppender">
<param name="file" value="${atlas.log.dir}/atlas_perf.log" />
<param name="datePattern" value="'.'yyyy-MM-dd" />
<param name="append" value="true" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d|%t|%m%n" />
</layout>
</appender>
<logger name="org.apache.atlas.perf" additivity="false">
<level value="debug" />
<appender-ref ref="perf_appender" />
</logger>
集成CDH的HBASE
添加HBASE集群配置文件到atlas配置目录下
ln -s /etc/hbase/conf/ /opt/apache-atlas-2.1.0/conf/hbase
集成CDH的Solr
将atlas自带的solr配置文件拷贝到solr的安装目录
scp -r /opt/apache-atlas-2.1.0/conf/solr/ ck-01:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/ scp -r /opt/apache-atlas-2.1.0/conf/solr/ ck-02:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/ scp -r /opt/apache-atlas-2.1.0/conf/solr/ ck-03:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/ scp -r /opt/apache-atlas-2.1.0/conf/solr/ ck-04:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/
修改solr配置目录名称
cd /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/ mv solr/ atlas-solr
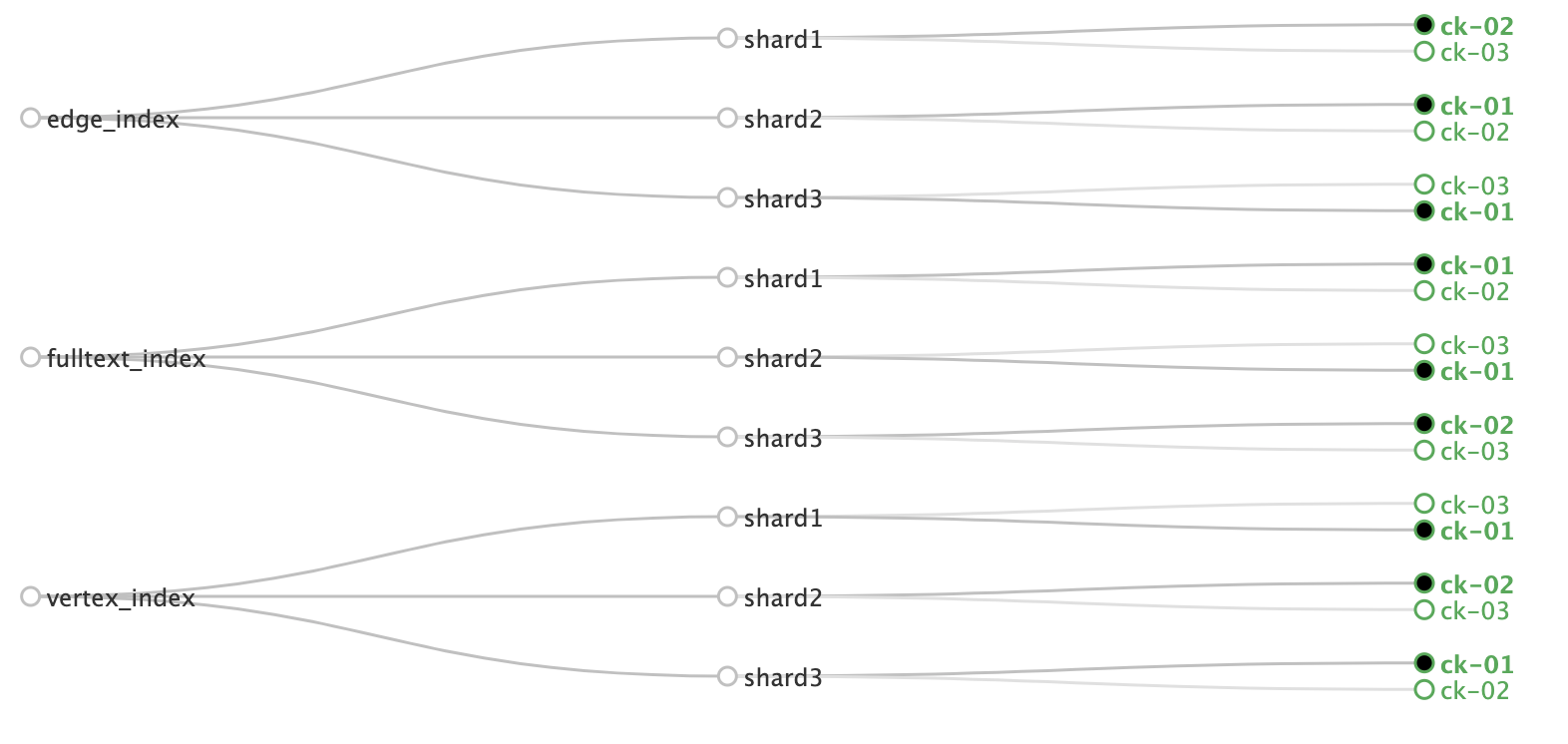
创建collection,需要切换到solr用户执行
./solr create -c vertex_index -d /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/atlas-solr -shards 3 -replicationFactor 2 ./solr create -c edge_index -d /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/atlas-solr -shards 3 -replicationFactor 2 ./solr create -c fulltext_index -d /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/solr/atlas-solr -shards 3 -replicationFactor 2
登录solr web控制台:http://ip:8983 /solr/#/~cloud验证创建collection成功是否成功
集成CDH的kafka
创建kafka topic
kafka-topics --zookeeper ck-01:2181,ck-02:2181,ck-03:2181 --create --replication-factor 3 --partitions 3 --topic _HOATLASOK kafka-topics --zookeeper ck-01:2181,ck-02:2181,ck-03:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_ENTITIES kafka-topics --zookeeper ck-01:2181,ck-02:2181,ck-03:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_HOOK
atlas启动
cd /opt/apache-atlas-2.1.0/ ./bin/atlas_start.py
登录atlas web控制台:http://ip:21000验证是否启动成功,默认用户名和密码为admin
Atlas与Hive集成
修改Hive配置
1、修改【hive-site.xml的Hive服务高级代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook
2、修改【hive-site.xml的Hive客户端高级代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook
3、修改 【hive-env.sh 的 Gateway 客户端环境高级配置代码段(安全阀)】
HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
JAVA_HOME= /usr/lib/jvm/java-1.8.0-openjdk/
4、修改【Hive 辅助 JAR 目录】
值:/opt/apache-atlas-2.1.0/hook/hive
5、修改 【hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook
名称:hive.reloadable.aux.jars.path
值:/opt/apache-atlas-2.1.0/hook/hive
6、修改 【HiveServer2 环境高级配置代码段(安全阀)】
HIVE_AUX_JARS_PATH=/opt/apache-atlas-2.1.0/hook/hive
将hive元数据导入atlas
将atlas配置添加到hive配置目录
cp /opt/apache-atlas-2.1.0/conf/atlas-application.properties /opt/cloudera/parcels/CDH/lib/hive/conf/
执行导入命令
cd /opt/apache-atlas-2.1.0 ./bin/import-hive.sh Enter username for atlas :- admin Enter password for atlas :- Hive Meta Data import was successful!!
执行hive命令:
CREATE TABLE t_ppp ( id int , pice decimal(2, 1) ) ; insert into t_ppp values (1,2.2); CREATE TABLE t_ppp_bak ( id int , pice decimal(2, 1) ) ; insert overwrite table t_ppp_bak select id,pice from t_ppp; CREATE VIEW IF NOT EXISTS t_ppp_view AS SELECT id,pice FROM t_ppp_bak;
web页面验证血缘关系:

转载请注明:西门飞冰的博客 » atlas2.1集成CDH6.2进行元数据管理