1、ClickHouse产生背景
随着科技的发展,时代的进步,数据分析师已经不再满足于传统的T+1式报表或需要提前设置好维度与指标的OLAP查询。数据分析师更希望使用可以支持任意指标、任意维度并秒级给出反馈的大数据Ad-hoc查询系统。这对大数据技术来说是一项非常大的挑战,传统的大数据查询引擎根本无法做到这一点。由俄罗斯的Yandex公司开源的ClickHouse便诞生了。在第一届OLAP大赛中,在用户行为分析转化漏斗场景里,ClickHouse比Spark快了近10倍。在随后的几年大赛中,面对各种大数据引擎的挑战,ClickHouse一直稳稳地坐在冠军宝座上。同时在各种OLAP查询引擎评测中,ClickHouse单表查询的速度力压现在的各大数据库引擎,尤其是Ad-hoc查询速度一直遥遥领先,因此被国内大量用户和爱好者广泛应用在即席查询场景中。
通俗的解释:数据分析师,他不会在乎,底层有多复杂的数据,多大量的数据,他更在乎的是,自己指定分析维度,并且进行交互式的分析查询(查询延迟是秒级)
ClickHouse的性能测试:https://clickhouse.tech/benchmark/dbms/
1、现有的大数据架构分析报表的缺点
如果我们要做一个基于Hadoop传统的数据分析会是下面的一个架构:程序实时的生成日志发送到kafka,在经过ETL处理之后入库到Hive仓库,数据仓库经过分析之后,将结果导出最后生成报表。
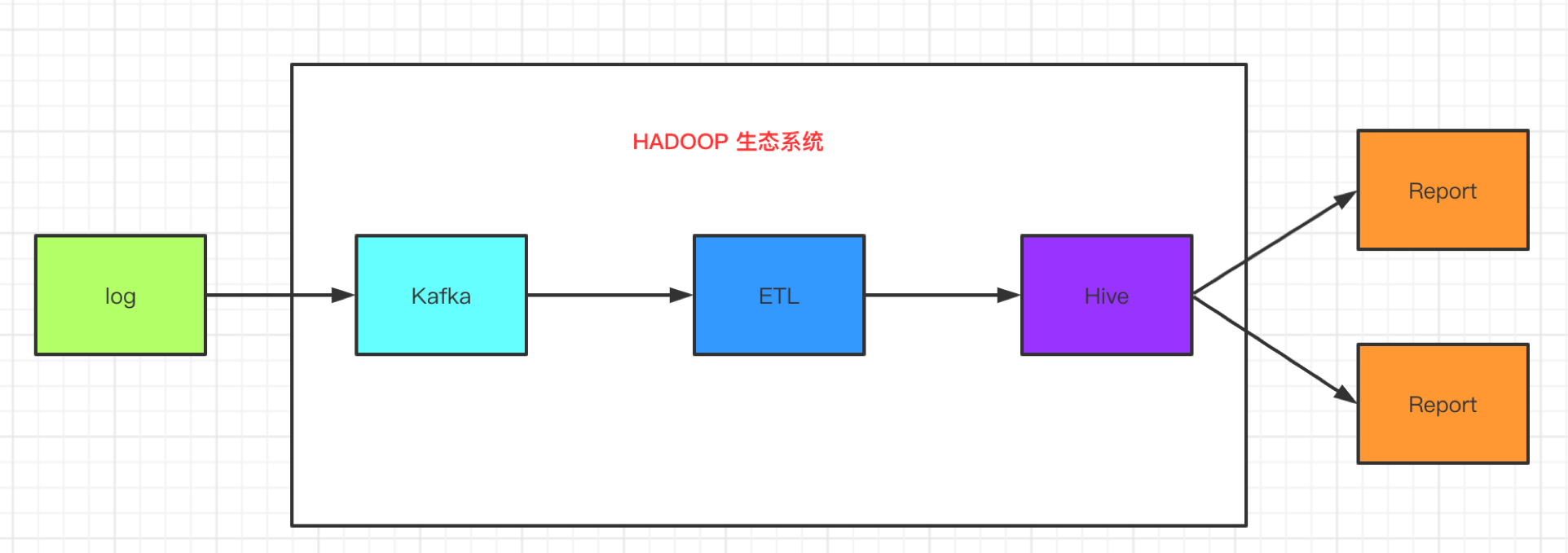
上面基于Hadoop 的报表数据分析架构缺点如下:
1、数据时效性:数据经过了Kafka、ELK、调度和各种的处理,所以最终的时效性不是那么的理想,就算这个架构最终优化的很好,那么最终的查询结果也都是秒级
2、即席分析性能:Hive数据存储在HDFS中,HDFS是不支持随机读写的,Hive底层使用的分析引擎,要么是MapReduce要么是Spark,相对来说,他们的执行效率都没有理想中那么好,不适合即席查询
3、涉及组件多:涉及Kafka、Flume、HDFS等等,数据冗余过多,维护起来麻烦
4、数据链路长:数据从源头到最终生成报表,中间经过了非常多的技术组件的处理,要是其中一个技术组件出现问题,那么都会影响我们的可用性。
最终的结果就是,我们基于传统的大数据分析架构进行报表分析,貌似没能达到我们理想中的效果,这个时候我们就期望大数据的性能能够更进一步,或者说有一个系统能够帮我们解决这些问题。
2、新时代的选择
架构目标:
1、海量数据
2、实时导入
3、实时查询
4、多维聚合分析,可以随意做交互式查询
假设我们依旧希望使用Hadoop来解决问题,那么我们希望Hadoop的性能可以翻上几番,但是Hadoop生态体系还是很复杂的,对开发、运维、架构师都有不少的挑战,所以在新时代,新需求冒出来之后,就有很多的公司开发出来了很多的新技术,有kylin, doris, clickhouse, kudu等,这种技术能通过比较低的复杂度来帮助我们高效的解决即席查询的需求。本文将对ClickHouse进行研究学习。
2、OLAP和OLTP技术要点分析
1、OLAP和OLTP介绍
ClickHouse作为OLAP分析引擎,那么OLAP和OLTP也是我们不得不了解的概念。
OLTP:T(transaction)联机事务处理,侧重于增删改
OLAP:A(analysis)联机分析处理,侧重于分析Select非事务大批量数据的聚合查询
事务处理作用:保证数据的一致性,如果涉及到事务操作,这个操作的执行效率必然不高。
我们设计一款存储系统,没法做到既能满足高效的增删改,又能做高效的查询分析,两者同时满足很困难。基本在业界出现的查询系统,要么是OLAP要么是OLTP,很少且几乎没有同时具备OLAP和OLTP两种特性的高效性。
2、读模式和写模式
写模式:数据存储到系统中的时候,系统会对数据进行校验,如果满足要求数据就能插入进去,如果不满足要求则拒绝写入。
读模式:校验数据模式的时候,在读取数据的时候才进行校验,不是在插入数据的时候进行校验。
OLAP一般都是读模式,OLTP写模式,ClickHouse出来,界限就模糊了。
ClickHouse写模式+OLAP。
3、海量数据高效即席查询需要的条件
海量数据做查询分析高效:列式数据库,写模式(保证同一列的数据类型是一样的,方便压缩),排序
具体优点如下:
1、列式数据库:假设我们一张表有100个字段,我们做查询分析只需要用到其中的几个字段,如果我们是行式数据库,那么我们就需要把这张表的数据都读取出来,我们读取到这行的时候,只需要提取100个字段中的几个字段就能分析。如果是列式数据库,则只需要扫描需要的字段即可完成查询分析。 所以我们在海量数据,想要设计出一块高效的即席查询系统,一定要将底层的数据存储改为列式存储。
2、既然我们将存储改成了列式存储,那么我们就需要对每一列的数据做一个校验,ClickHouse是一个列式数据库,同时他也是一个写模式,就是为了数据写入的时候可以进行校验,写入一列数据,它可以保证一列数据值的类型都是一样的。因为每一个记录这个值的大小都是一样的,所以就类似于我们可以通过连续内存的这个模式来进行存储,对于我们解析和处理来说也会显现的非常高效。
3、同时因为所有字段的值都是一样的,所以我们压缩的时候效果也会特别的高。
4、因为我们这一列的值都是一样的,所以我们做排序的时候也有助于我们进行查询分析。
OLAP体系的重要三个特点:排序+写模式+列式数据库。ClickHouse全部具备
ClickHouse官网解释:https://clickhouse.tech/docs/zh/#olapchang-jing-de-guan-jian-te-zheng
3、ClickHouse介绍
ClickHouse官网:https://clickhouse.tech/
ClickHouse中文社区:http://www.clickhouse.com.cn/
ClickHouse 是俄罗斯搜索巨头 Yandex 公司早 2016年 开源的一个极具 ” 战斗力 ” 的实时数据分析数据 库,是一个用于联机分析 (OLAP:Online Analytical Processing) 的列式数据库管理系统 (DBMS:Database Management System),简称 CK,工作速度比传统方法快100-1000倍,ClickHouse 的性能超过了目前市场上可比的面向列的DBMS。 每秒钟每台服务器每秒处理数亿至十亿多行和数十千 兆字节的数据。它允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服 务器,支持线性扩展,简单方便,高可靠性,容错。
ClickHouse 作为一个高性能 OLAP 数据库,虽然OLAP能力逆天但也不应该把它用于任何OLTP事务性 操作的场景,相比OLTP:不支持事务、不擅长根据主键按行粒度的查询、不擅长按行删除数据,目前 市场上的其他同类高性能 OLAP 数据库同样也不擅长这些方面。因为对于一款OLAP数据库而言,OLTP 能力并不是重点。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存 储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。这些功能共 同为ClickHouse极速的分析性能奠定了基础。
ClickHouse适合流式或批次入库的时序数据。ClickHouse不应该被用作通用数据库,而是作为超高性能 的海量数据快速查询的分布式实时处理平台,在数据汇总查询方面(如GROUP BY),ClickHouse的查询 速度非常快。
典型特点总结:ROLAP、在线实时查询、完整的DBMS、列式存储、不需要任何数据预处理、支持批量 更新、具有非常完善的SQL支持和函数、支持高可用、不依赖Hadoop复杂生态、开箱即用
简单的说,ClickHouse作为分析型数据库,有三大特点:一是跑分快, 二是功能多 ,三是文艺范 1. 跑分快: ClickHouse跑分是Vertica的5倍快:
(1)、跑分快:ClickHouse跑分是Vertica的五倍快
clickHouse性能超过了市面上大部分的列式存储数据库,相比传统的数据ClickHouse要快100-1000X, ClickHouse还是有非常大的优势:
100Million 数据集:ClickHouse比Vertica约快5倍,比Hive快279倍,比MySQL快801倍
1Billion 数据集:ClickHouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了
(2)、功能多:ClickHouse支持数据统计分析各种场景
支持类SQL查询, 支持繁多库函数(例如IP转化,URL分析等,预估计算/HyperLoglog等) 支持数组(Array)和嵌套数据结构(Nested Data Structure) 支持数据库异地复制部署+支持分布式
(3)、文艺范:目前ClickHouse的限制很多,生来就是为小资服务的
– 相对较缺乏的文档,社区刚开始活跃,只有开源的C++源码
– 不理睬Hadoop生态,走自己的路
1、ClickHouse适用场景
适合:用于结构良好清晰且不可变的事件或日志流实时查询分析。
不适合:事务性工作(OLTP),高请求率的键值访问,低延迟的修改或删除已存在数据,Blob或文档存储,超 标准化数据。
2、ClickHouse优点
与 Hadoop、Spark 这些巨无霸组件相比,ClickHouse 具有轻量级的优点,它的特点包括以下内容:
(1)真正的面向列的 DBMS
ClickHouse 是一个 DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行 查询,而无需重新配置和重新启动服务器。
(2)数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
(3)磁盘存储的数据
许多面向列的 DBMS(SAP HANA 和 GooglePowerDrill)只能在内存中工作。但即使在数千台服务器 上,内存也太小,无法在 Yandex.Metrica 中存储所有浏览量和会话。
(4)多核并行处理 多核多节点并行化大型查询。
(5)在多个服务器上分布式处理
在 ClickHouse 中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分 片上并行处理。
(6)SQL支持
ClickHouse SQL 跟真正的 SQL 有不一样的函数名称。不过语法基本跟 SQL 语法兼容,支持 JOIN、 FROM、IN 和 JOIN 子句以及标量子查询支持子查询。
(7)向量化引擎
数据不仅按列存储,而且由矢量 – 列的部分进行处理,这使开发者能够实现高 CPU 性能。
(8)实时数据更新
ClickHouse 支持主键表。为了快速执行对主键范围的查询,数据使用合并树 (MergeTree) 进行递增排 序。由于这个原因,数据可以不断地添加到表中。
(9)支持近似计算(很多组件不具备的)统计全中国到底有多少人?1434567654 14.3E PV 近似计算 UV 具体的值 该库支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相 对准确的结果,同时使用较少的资源。
(10)数据复制和对数据完整性的支持。
ClickHouse 使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副 本上保持相同的数据。数据在失败后自动恢复。 扩展成为分布式的数据库OLAP引擎,严重依赖于zookeeper 的
3、ClickHouse缺点
ClickHouse 作为一个被设计用来在实时分析的 OLAP 组件,只是在高效率的分析方面性能发挥到极 致,那必然就会在其他方面做出取舍:
(1)没有完整的事务支持,不支持Transaction:想快就别想Transaction
(2)缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅能用于批量删除或修改数据。
(3)聚合结果必须小于一台机器的内存大小:不是大问题
(4)支持有限操作系统,正在慢慢完善
(5)开源社区刚刚启动,主要是俄语为主,中文社区:http://www.clickhouse.com.cn
(6)不适合key-value存储,不支持 Blob 等文档型数据库
4、ClickHouse安装部署
操作系统:Centos 7.6
ClickHouse:20.x
1、安装前的准备
(1)修改打开文件数限制,重启服务器生效,ulimit -n或 -a检查生效情况
[root@ck-01 ~]# cat /etc/security/limits.conf * soft nofile 65535 * hard nofile 65535 * soft fsize 6553500 * hard fsize 6553500
(2)关闭Selinux和Iptables
(3)安装依赖
yum install -y libtool yum install -y *unixODBC*
(4)需要验证当前服务器的 CPU 是否支持 SSE 4.2 指令集,因为向量化执行需要用到这项特性:
[root@ck-01 ~]# grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported" SSE 4.2 supported
2、单机安装ClickHouse
执行如下命令进行安装
[root@ck-01 ~]# yum install yum-utils -y [root@ck-01 ~]# rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG [root@ck-01 ~]# yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo [root@ck-01 ~]# yum install clickhouse-server clickhouse-client -y
修改安装目录权限为root,不然root启动会报错
[root@ck-01 ~]# cd /var/lib/ [root@ck-01 ~]# chown -R root:root clickhouse
后台启动ClickHouse
[root@ck-01 lib]# nohup clickhouse-server --config-file=/etc/clickhouse-server/config.xml 1>~/logs/clickhouse_std.log 2>~/logs/clickhouse_err.log
检查启动
[root@ck-01 lib]# ps aux | grep clickhouse root 13307 0.0 0.9 464928 34884 pts/1 S 19:22 0:00 clickhouse-watchd --config-file=/etc/clickhouse-server/config.xml root 13308 1.9 7.1 1248464 273696 pts/1 SLl 19:22 0:00 clickhouse-server --config-file=/etc/clickhouse-server/config.xml root 13355 0.0 0.0 112824 980 pts/1 S+ 19:22 0:00 grep --color=auto clickhouse [root@ck-01 lib]# netstat -lntp | grep clickhouse tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 13308/clickhouse-se tcp 0 0 127.0.0.1:9004 0.0.0.0:* LISTEN 13308/clickhouse-se tcp 0 0 127.0.0.1:9009 0.0.0.0:* LISTEN 13308/clickhouse-se tcp 0 0 127.0.0.1:8123 0.0.0.0:* LISTEN 13308/clickhouse-se tcp6 0 0 ::1:9000 :::* LISTEN 13308/clickhouse-se tcp6 0 0 ::1:9004 :::* LISTEN 13308/clickhouse-se tcp6 0 0 ::1:9009 :::* LISTEN 13308/clickhouse-se tcp6 0 0 ::1:8123 :::* LISTEN 13308/clickhouse-se
其他安装方式参考官方:https://clickhouse.tech/#quick-start
ClickHouse核心目录:
(1)/etc/clickhouse-server:服务端的配置文件目录,包括全局配置config.xml和用户配置users.xml等。
(2)/var/lib/clickhouse:默认数据存储目录,通常会修改默认路径配置,将数据保存到大容量磁盘挂 载路径
(3)/var/log/clickhouse-server:默认日志保存目录,通常会修改路径配置将日志保存到大容量磁盘 挂载的路径
ClickHouse可执行文件:
(1)clickhouse:主程序的可执行文件。
(2)clickhouse-client:一个指向ClickHouse可执行文件的软链接,供客户端连接使用。
(3)clickhouse-server:一个指向ClickHouse可执行文件的软链接,供服务端启动使用。
(4)clickhouse-compressor:内置提供的压缩工具,可用于数据的正压反解。
3、配置ClickHouse集群
环境介绍:
| 主机名 | IP地址 | 操作系统 |
| ck-01 | 10.1.14.91 | centos 7.6 |
| ck-02 | 10.1.14.92 | centos 7.6 |
| ck-03 | 10.1.14.93 | centos 7.6 |
| ck-04 | 10.1.14.94 | centos 7.6 |
前置准备工作:
1、在四台机器中按照单机部署的方式,分别准备ClickHouse环境
2、部署一套zookeeper集群
(1)所有节点修改config.xml文件
[root@ck-01 ~]# vim /etc/clickhouse-server/config.xml <listen_host>::</listen_host>
listen_host 表示能监听的主机,:: 表示任意主机都可以访问
(2)在四台机器的etc目录下新建metrika.xml文件
[root@ck-01 ~]# cat /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<!-- 4分片1副本 -->
<fb_clickhouse_4shards_1replicas>
<shard>
<!-- 数据自动同步 -->
<internal_replication>true</internal_replication>
<replica>
<host>ck-01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck-02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck-03</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck-04</host>
<port>9000</port>
</replica>
</shard>
</fb_clickhouse_4shards_1replicas>
</clickhouse_remote_servers>
<!-- zookeeper 自动同步 -->
<zookeeper-servers>
<node index="1">
<host>ck-01</host>
<port>2181</port>
</node>
<node index="2">
<host>ck-02</host>
<port>2181</port>
</node>
<node index="1">
<host>ck-03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 配置文件中macros若省略,则建复制表时每个分片需指定zookeeper路径及副本名称,同一分片 上路径相同,副本名称不同;若不省略需每个分片不同配置 -->
<macros>
<replica>ck-01</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<!-- 配置压缩 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
配置完成之后重启四个节点,集群配置就完成了
4、设置用户名和密码
系统默认使用 default 用户登录 无密码。 现在我们配置用户 bigdata 密码为 bigdata 配置一个用户:你配置的 bigdata 就是用户名, <password> 这个标签中的值,就是密码
[root@ck-01 ~]# vim /etc/clickhouse-server/users.xml
<bigdata>
<password>bigdata</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</bigdata>
修改完成之后,这个配置文件要同步到其他节点中
5、客户端连接集群
启动客户端连接集群的命令
[root@ck-01 ~]# clickhouse-client --host=ck-01 --port=9000 --user=bigdata --password=bigdata -m
ClickHouse客户端参数介绍
| 参数 | 描述 |
| –host, -h | 目标服务器名,默认为 localhost |
| –port | 目标端口,默认为 9000 |
| –user, -u | 连接用户,默认为 default |
| –password | 连接用户密码,默认为空字符串 |
| –query, -q | 非交互模式下执行的命令 |
| –database, -d | 当前操作的数据库,默认选择配置文件配置的值(默认为 default 库) |
| –multiline, -m | 如果设定,允许多行查询 |
| –multiquery, -n | 如果指定,允许处理由分号分隔的多个查询。只有在非交互式模式工作。 |
| –format, -f | 使用指定的默认格式输出结果 |
| –vertical, -E | 如果指定,默认使用垂直格式输出结果,等同于 –format=Vertical。 在这种格式中,每个值可在单独的行上,显示宽表时很有用。 |
| –time, -t | 如果指定,在 stderr 中输出查询执行时间的非交互式模式下。 |
| –stacktrace | 如果指定,如果发生异常,也会输出堆栈跟踪。 |
| –config-file | 配置文件的名称,额外的设置或改变了上面列出的设置默认值。 |
6、ClickHouse集群注意事项
ClickHouse每个节点在安装的时候,都是独立的。就算是配置成集群了,每个服务器依然还是单独运行的。如果你创建了一张表,这张表的引擎是分布式的引擎,那么这个表所存储在那个集群里面的机器,就是一个集群了。
转载请注明:西门飞冰的博客 » ClickHouse学习和集群部署