k8s弹性伸缩涉及内容
在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。
有三种弹性伸缩
- CA(Cluster Autoscaler):Node级别自动扩/缩容cluster-autoscaler组件
- HPA(Horizontal Pod Autoscaler):Pod个数自动扩/缩容
- VPA(Vertical Pod Autoscaler):Pod配置(request和Limites限额)自动扩/缩容,主要是CPU、内存addon-resizer组件,目前这个组件不是很成熟,应用的也比较少,主要使用场景是有状态应用,不支持水平扩容的pod
如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
本文主要介绍CA和HPA 的弹性伸缩方式
node自动化缩容/扩容
1、cluster autoscaler扩容,适用与云平台,根据cpu和内存使用率自动添加机器
扩容:Cluster AutoScaler定期检测是否有充足的资源来调度新创建的pod,当资源不足时会调用Cloud Provider创建新的Node
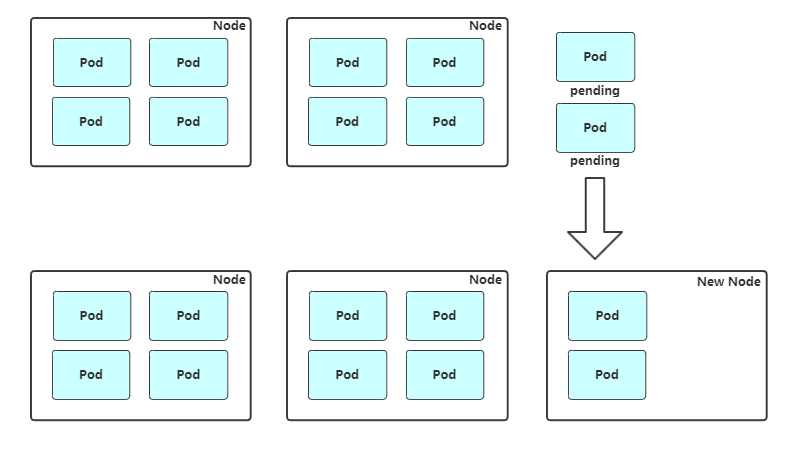
缩容:Cluster AuthScaler也会定期检测Node的资源使用情况,当一个Node长时间资源利用率都很低时(低于50%)自动将其所在虚拟机从云服务商中删除。此时,原来的Pod会自动调度到其他Node上面。
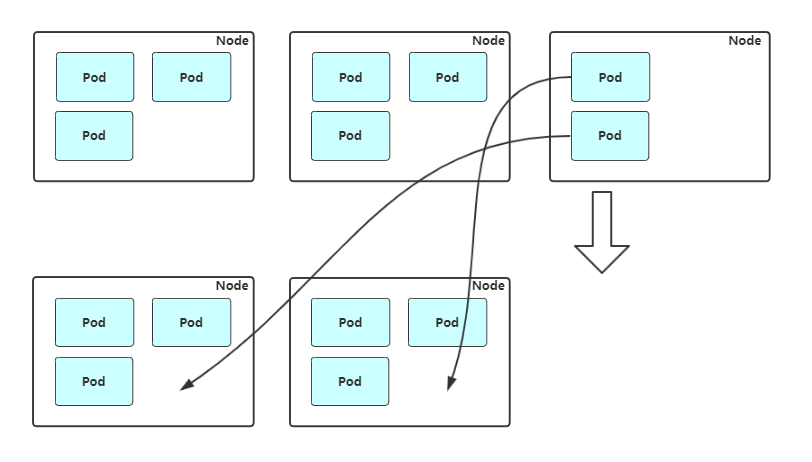
支持的云提供商,具体配置可以结合如下GitHub参考,云厂商都提供技术支持:
- 阿里云:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
- AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
- Azure: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
2、可以通过ansible或是salt等工具自动扩容node节点,具体流程如下:
(1)触发新增Node
(2)调用Ansible脚本部署组件
(3)检查服务是否可用
(4)调用API将新Node加入集群或者启用Node自动加入
(5)观察新Node状态
(6)完成Node扩容,接收新Pod
3、缩容节点:
(1)获取节点列表
(2)设置不可调度
(3)驱逐节点上的pod
(4)移除节点
pod自动化缩容量/扩容(HPA)
HPA介绍
HPA(Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整replication controller, deployment 或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
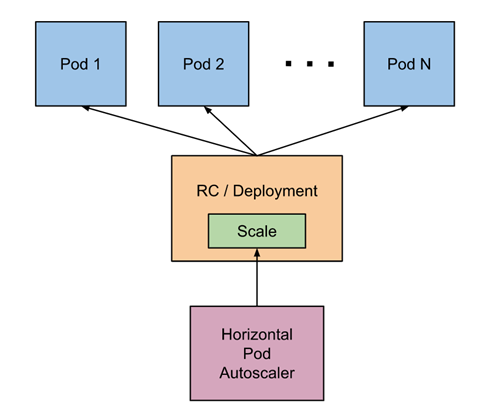
HPA原理
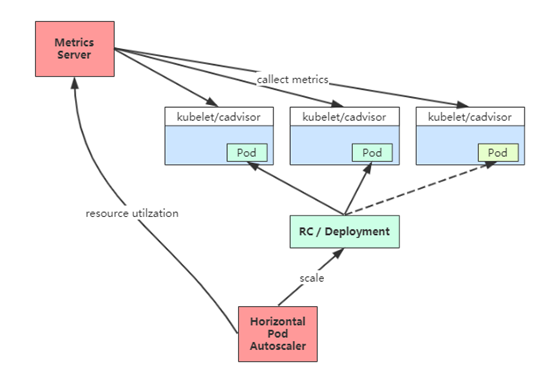
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作
HPA 三个扩容指标设置
1、pod扩容最大、最小范围值(主要用来防止持续的扩容消耗完集群资源)
2、扩容预值的判断,比如CPU使用率超过50%扩容还是超过70扩容
3、操作那一组对象进行扩容
冷却周期:在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸, 所以在每次做出扩容缩容后,冷却时间是多少。在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。HPA通过这种机制来保障集群的稳定性
基于CPU指标缩放
Kubernetes API Aggregation配置
如果你使用kubeadm部署的,默认已开启。如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,增加以下配置:
# vi /opt/kubernetes/cfg/kube-apiserver.conf ... --requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \ --proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \ --proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \ --requestheader-allowed-names=kubernetes \ --requestheader-extra-headers-prefix=X-Remote-Extra- \ --requestheader-group-headers=X-Remote-Group \ --requestheader-username-headers=X-Remote-User \ --enable-aggregator-routing=true \ ...
在设置完成重启 kube-apiserver 服务,就启用 API 聚合功能了。
部署 Metrics Server
Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。Metric server从每个节点上Kubelet公开的摘要API收集指标。
因为你要扩容并不是一个副本去扩容,要把当前pod运行所有副本的指标都考虑进去,每个node都有一个cadviar,但是访问cadviar只是当前节点的资源利用率,他并没有聚合的功能,要相对所有pod的资源利用率进行汇总,那么上面就要有一个metrics server
Metrics server通过Kubernetes聚合器注册在Master APIServer中。所以k8s必须启动聚合器,metrics server才能把自己注册进去。
# git clone https://github.com/kubernetes-incubator/metrics-server
# cd metrics-server/deploy/1.8+/
# vi metrics-server-deployment.yaml # 添加2条启动参数
...
containers:
- name: metrics-server
image: metrics-server-amd64:v0.3.1
command:
- /metrics-server
- --kubelet-insecure-tls # 忽略证书信任,可以使用http和https进行访问
- --kubelet-preferred-address-types=InternalIP # 不使用主机名进行解析
...
# kubectl create -f .
验证部署是否成功
[root@k8s-master-02 metrics-server]# kubectl get pods -n kube-system | grep metrics metrics-server-7dbbcf4c7-cl72m 1/1 Running 0 3m41s
验证是否部署到api中
[root@k8s-master-02 metrics-server]# kubectl get apiservices | grep metrics v1beta1.metrics.k8s.io kube-system/metrics-server False (FailedDiscoveryCheck) 3m20s
检查资源使用率
[root@k8s-master-02 metrics-server]# kubectl top pods NAME CPU(cores) MEMORY(bytes) nfs-client-provisioner-7689645989-db42k 3m 10Mi [root@k8s-master-02 metrics-server]# kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-dev-01 121m 3% 1671Mi 17% k8s-dev-02 170m 4% 2137Mi 22% k8s-dev-03 115m 2% 1650Mi 17% k8s-master-01 123m 3% 1801Mi 49% k8s-master-02 1134m 28% 2328Mi 63% k8s-qa-01 106m 2% 1415Mi 14% k8s-qa-02 101m 2% 1446Mi 14% k8s-qa-03 132m 3% 1520Mi 15%
基于CPU的弹性伸缩autoscaling/v1
首先部署一个应用
[root@k8s-master-02 ~]# cat app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
selector:
matchLabels:
app: nginx-php
template:
metadata:
labels:
app: nginx-php
spec:
containers:
- image: nginx-php
name: java
resources:
requests:
memory: "300Mi"
cpu: "250m"
---
apiVersion: v1
kind: Service
metadata:
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-php
[root@k8s-master-02 ~]# kubectl apply -f app.yaml
创建HPA策略,设置部署的应用,最多扩容到5个,最小缩容到1个,触发扩容的阀值是CPU使用率为60
[root@k8s-master-02 ~]# cat HPA-v1.yml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web
targetCPUUtilizationPercentage: 60
[root@k8s-master-02 ~]# kubectl apply -f HPA-v1.yml
scaleTargetRef:表示当前要伸缩对象是谁
targetCPUUtilizationPercentage:当整体的资源利用率超过50%的时候,会进行扩容。
验证HPA创建是否成功
[root@k8s-master-02 ~]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE web Deployment/web 0%/60% 1 5 3 20s
模拟压测,增加pod CPU使用率,验证是否会触发自动扩容
[root@k8s-master-02 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 81d web ClusterIP 10.0.0.192 <none> 80/TCP 28m [root@k8s-master-02 ~]# ab -n 100000 -c 100 http://10.0.0.192/status.php
检查扩容(注意,获取指标利用率不是实时的,他是具有一定采集周期性的,所以最好保证压测的时间长一些)
[root@k8s-master-02 ~]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE web Deployment/web 248%/60% 1 5 5 9m53s [root@k8s-master-02 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) web-6595b64bf7-4mxgw 6m 16Mi web-6595b64bf7-cn6ld 3m 16Mi web-6595b64bf7-flnxg 968m 64Mi web-6595b64bf7-qv5jz 2m 16Mi web-6595b64bf7-v8dqz 3m 16Mi
关闭压测之后,过一会随着CPU利用下降,副本数又会调整到一个,这个缩容时间是五分钟
转载请注明:西门飞冰的博客 » k8s 弹性伸缩,基于CPU指标



