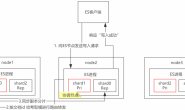
冷热数据分离的目的
1、ES集群异构,机器硬件资源配置不一,有高性能CPU和SSD存储集群,也有大容量的机械磁盘集群,比如我们的场景就是存放冷数据的集群,服务器都是多年前买的一批满配的4T Dell R70,但是新扩容的热节点机器均为DELL 高性能SSD磁盘和CPU的R740机器。
2、对于时间型数据来说,一般是当前的数据,写入和查询较为集中,所以高性能的资源应该优先提供给这些数据使用。
3、集群的搜索和写入性能,取决于最慢节点的性能。
冷热数据分离的前提
1、ES 的索引已经按照天或者月的时间维度生成索引。
2、历史数据相对于近期数据来说没有高频度的查询需求。
冷热数据分离的实现策略
本文实现策略:最新的天和月索引均为热数据,其他索引根据查询周期不同,调整为冷数据。当然业务不同策略不同,具体实现策略还是需要根据实际的业务场景来决定。
前置条件
需要修改ES 集群配置文件,对节点进行打标签操作,配置如下:
热数据实例:
node.tag: "hot"
冷数据实例:
node.tag: "cold"
修改集群配置需要进行重启实例生效
这种打标签的操作可以通过滚动,重启集群实例,因为涉及到重启后的数据恢复问题,可能滚动重启的时间会比较长(根据数据量大小和分片数量决定),可以通过如下的方式,增加数据恢复的最大并行度和数据恢复的最大带宽进行调整,逐步调大到不影响集群业务性能为止。
设置数据恢复的最大并行度
curl -XPUT http://192.168.201.5:9200/_cluster/settings -d'
{
"persistent" :
{
"cluster.routing.rebalance.enable": "all", ## 为特定类型的分片启用或禁用重新平衡:
"cluster.routing.allocation.node_concurrent_incoming_recoveries":6, ##允许在一个节点上发生多少并发传入分片恢复。 默认为2
"cluster.routing.allocation.node_concurrent_outgoing_recoveries":6, ##允许在一个节点上发生多少并发传出分片恢复,默认为2
"cluster.routing.allocation.node_concurrent_recoveries":6, ##为上面两个的统一简写
"cluster.routing.allocation.node_initial_primaries_recoveries":10, ##在通过网络恢复副本时,节点重新启动后未分配的主节点的恢复使用来自本地 磁盘的数据。这些应该很快,因此更多初始主要恢复可以在同一节点上并行发生。 默认为4。
"cluster.routing.allocation.same_shard.host":true ##允许执行检查以防止基于主机名和主机地址在单个主机上分配同一分片的多个实例。
}
}'
设置数据恢复的最大带宽
curl -XPUT http://192.168.201.5:9200/_cluster/settings -d'
{
"persistent" :
{
"indices.recovery.max_bytes_per_sec": "2g"
}
}'
新增索引实现冷热数据分离
集群滚动重启完成之后,已经具备了冷热数据分离的条件,那么如何让新增索引自动成为热数据呢?
答案就是修改ES 索引的模板,为ES 索引打tag,配置实例如下:
"template": "索引名称*",
"settings": {
"index": {
"routing": {
"allocation": {
"require": {
"tag": "hot" #节点标签
}
}
}
}
}
只要在索引模板中打了热标签的索引,就会在创建的时候自动分布在集群中实例打了热标签的节点上。
历史索引实现冷热数据迁移
那么历史的ES数据如何让其从热节点迁移到冷节点呢?
答案就是,通过api修改ES 索引的标签,将其变更为冷标签,这样ES 索引就会自动迁移到集群中打了冷标签的实例上,配置如下:
curl -XPUT http://10.1.11.151:9200/索引名称/_settings -d '{
"index.routing.allocation.include.tag": "cold"
}'
实际生产中会将制定好的冷热数据规则编写成脚本,放到计划任务中,来定时定点的运行,达到热数据自动迁移为冷数据的目的。
ES 单机多实例的实现
熟悉ES的同学知道,JVM heap分配不能超过32GB,对于使用物理机部署ES的环境来说,一台机器的内存往往就动辄192G或者256G,如果只跑一个ES实例,只能利用到32G的heap,而且还无法充分发挥CPU和IO资源,这样显然是不经济的。因为我们常常会部署单机多实例的ES节点,在多实例配置中除了要隔离日志和数据目录之外,还需要增加以下两个配置,不然一台物理机宕机,可能会因为多个副本存在一个ES物理机上面导致业务受到影响。
node.max_local_storage_nodes: 2 # 设置一台机器能运行的节点数目 cluster.routing.allocation.same_shard.host: true # 执行检查以防止基于主机名和主机地址在单个主机上分配同一分片的多个实例。 默认为false,表示默认情况下不执行检查。 此设置仅适用于在同一台计算机上启动多个节点的情况。这个我的理解是如果设置为false,则同一个节点上多个实例可以存储同一个shard的多个副本没有容灾作用了
转载请注明:西门飞冰的博客 » ES集群数据冷热分离实现