impala的产生背景和应用场景
Impala由cloudera公司主导开发的大数据实时查询分析工具,宣称比原来基于MapReduce的HiveSQL查询速度提升3~90倍,且更加灵活易用。提供类SQL的查询语句,能够查询存储在HDFS、Kudu、HBase(实际生产环境中不用)中的PB级大数据。查询速度快是其最大的卖点。简言之impala作为大数据实时查询分析工具,具有查询速度快,灵活性高,易整合,可伸缩性强等特点。
但是在一些实时性要求很高的场景中,一方面满足实时性要求,一方面提升用户体验。Impala因其快速的响应能力当之无愧作为首选查询分析工具。
1.查询速度快:impala不同于hive,hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程。不同于hive,impala中间结果不写入磁盘,及时通过网络以流的形式传递,大大降低的节点的IO开销。
2.灵活性高:可以直接查询存储在HDFS上的原生数据,也可以查询经过优化设计而存储的数据,常用的数据格式为parquet。
3.易整合:很容易和hadoop系统整合,并使用hadoop生态系统的资源和优势,不需要将数据迁移到特定的存储系统就能满足查询分析的要求。
4.可伸缩性:可以很好的与一些BI应用系统协同工作,如Cboard、Tableau等。
impala的优缺点
优点:
1、支持SQL查询,快速查询大数据。
2、可以对已有数据进行查询,减少数据的加载,转换。
3、多种存储格式可以选择(Parquet,Text, Avro, RCFile, SequeenceFile,不支持ORCFile)。
4、可以与Hive配合使用。
5、可以查询底层HDFS和Kudu数据
6、支持UDF函数
7、完美集成ClouderaManager和Ambari
缺点:
1、impala不支持hive的udtf函数,仅仅支持udf函数(java、c++),udaf(c++)
2、不支持查询期的容错。
3、对内存要求高。
4、适用于处理预计算后的数据,不适合处理源数据。
impala的基础架构
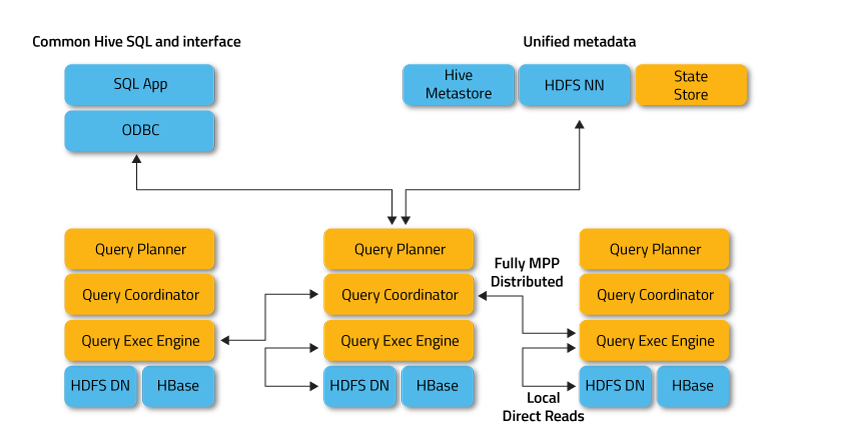
架构:采用无中心设计
开发语言:C++
三大核心组件:
- Impala Daemon(数据读写和子任务的执行功能)
- Impala Statestore(消息订阅服务和状态监测功能)
- Impala Catalog Service(元数据管理和元存储功能)
impala daemon
impalad是Impala的核心进程,运行在所有的数据节点上,可以读写数据,并接收客户端的查询请求,并行执行来自集群中其他节点的查询请求,将中间结果返回给调度节点。调度节点将结果返回给客户端。用户在impala的某个节点提交数据处理请求则该节点称为coordinator node(协调器节点),其他的集群节点传输其中的处理的部分数据集到该coordinator node,coordinator node负责构建最终的结果数据返回给用户。
impala 支持在提交任务的时候(采用JDBC ,ODBC 方式) 采用round-robin算法来实现负载均衡,将任务提交到不同的节点上。
impalad 进程通过持续的和statestore通信来确认自己所在的节点是否健康和是否可以接受新的任务请求
通常每一个HDFS的DataNode上部署一个Impalad进程,由于HDFS存储数据通常是多副本的,所以这样的部署可以保证数据的本地性,查询尽可能的从本地磁盘读取数据而非网络,从这点可以推断出Impalad对于本地数据的读取应该是通过直接读本地文件的方式,而非调用HDFS的接口。为了实现查询分割的子任务,可以做到尽可能的本地数据读取,Impalad需要从Metastore中获取表的数据存储路径,并且从NameNode中获取每一个文件的数据块分布。(每个impalad本地都缓存一份元数据)
从Impalad的各个模块可以看出,主要查询处理都是在Impalad进程中完成的,StateStore和Catalog帮助Impalad完成元数据的管理和负载监控等工作,其实更进一步可以将Query Planner和Query Coordinator模块从Impalad移出单独的作为一个入口服务存在,而Impalad仅负责数据读写和子任务的执行。
在Impalad进行执行优化的时候根本原则是尽可能的数据本地读取,减少网络通信,毕竟在不考虑内存缓存数据的情况下,从远程读取数据需要磁盘->内存->网卡->本地网卡->本地内存的过程,而从本地读取数据仅需要本地磁盘->本地内存的过程,可以看出,在相同的硬件结构下,读取其他节点数据的速度始终小于本地磁盘的数据读取速度。
impala statestore
Statestore是状态管理进程,定时检查Impala Daemon的健康状况,协调各个运行impalad的实例之间的信息关系,进程名叫做 statestored。如果Impala节点由于物理原因、网络原因、软件原因或者其他原因而下线,Statestore会通知其他节点,避免查询任务分发到不可用的节点上。
Catalog中的元数据就是通过StateStore服务进行广播分发的(也就是缓存在impalad的元数据),它实现了一个Pub-Sub服务,Impalad可以注册它们并希望获得的事件类型,Statestore会周期性的发送两种类型的消息给Impalad进程,一种为该Impalad注册监听的事件的更新,基于版本的增量更新(只通知上次成功更新之后的变化)可以减小每次通信的消息大小;另一种消息为心跳信息,StateStore负责统计每一个Impalad进程的状态,Impalad可以据此了解其余Impalad进程的状态,用于判断分配查询任务到哪些节点。
由于周期性的推送并且每一个节点的推送频率不一致可能会导致每一个Impalad进程获得的状态不一致和每一次查询只依赖于协调者coordinator进程获取的状态进行任务的分配而不需要多个进程进行再次的协调,因此并不需要保证所有的Impalad状态是一致的。另外,StateStore进程是单点的,并且不会持久化任何数据到磁盘,如果服务挂掉,Impalad则依赖于上一次获得元数据状态进行任务分配。
StateStore并不是必须的,它只是在Impala集群中有节点出错时才起作用,而如果StateStore未启动或者不能提供服务,并不影响Impala集群中其他节点正常工作,而Impala集群顶多是变得不可靠。当StateStore恢复在线,它将重建与其他节点的通讯,并恢复它的监控功能。
impala catalog service
元数据管理服务,进程名叫做catalogd,将hive的元数据中的数据表变化的信息分发给各个进程。接收来自statestore的所有请求 ,每个Impala节点在本地缓存所有的元数据。 当处理极大量的数据或许多分区时,获得表特定的元数据可能需要大量的时间。 因此,本地存储的元数据缓存有助于立即提供这样的信息。当表定义或表数据更新时,其他Impala后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
由于Impala没有update/delete操作,所以它不需要对HDFS做任何修改。但是insert操作,则不是如此,如果通过hive则改变的是Hive metastore的状态,比如说增加分区操作,此时需要通过在Impala中执行REFRESH以通知元数据的更新,而Impalad会将该更新操作通知Catalog。
而不改变hive的元数据,直接通过impala的insert操作则会通过广播的方式通知其它的Impalad进程。默认情况下Catalog是异步加载元数据的,因此查询可能需要等待元数据加载完成之后才能进行(第一次加载)。该服务的存在将元数据从Impalad进程中独立出来,可以简化Impalad的实现,降低Impalad之间的耦合。
impala的读写流程
读流程:
1、客户端提交任务:客户端通过Beeswax或者HiveServer2接口或者是Impala-
Shell发送一个SQL查询请求到impalad节点,查询包括一条SQL和相关的Configuration信息(只对本次查询生效),查询接口提供同步和异步的方式执行,两种接口都会返回一个QueryId用于之后的客户端操作。
2、查询解析和分析:SQL提交到Impalad节点之后交由FE模块处理,由Analyser依次执行SQL的词法分析、语法分析、语义分析、查询重写等操作,生成该SQL的Statement信息。
3、单机执行计划生成:根据上一步生成的Statement信息,由Planner生成单机的执行计划,该执行计划是有PlanNode组成的一棵树,这个过程中也会执行一些SQL优化,例如Join顺序改变、谓词下推等。
4、分布式执行计划生成:由Planner将单机执行计划转换成分布式并行物理执行计划,物理执行计划由一个个的Fragment组成,Fragment之间有数据依赖关系,处理过程中需要在原有的执行计划之上加入一些ExchangeNode和DataStreamSink信息等。
5、任务调度和分发:由BE处理生成的分布式物理执行计划,将Fragment根据数据分区信息发配到不同的Impalad节点上执行。Impalad节点接收到执行Fragment请求交由Backend模块处理Fragment的执行。
6、子任务执行:每一个Fragment的执行输出通过DataStreamSink发送到下一个Fragment,由下一个Fragment的ExchangeNode接收,Fragment运行过程中不断向coordinator节点汇报当前运行状态。
7、结果汇总:查询的SQL通常情况下需要有一个单独的Fragment用于结果的汇总,它只在coordinator节点运行,将多个backend的最终执行结果汇总,转换成ResultSet信息。
8、客户端查询结果:客户端调用获取ResultSet的接口,读取查询结果。
9、关闭查询:客户端调用CloseOperation关闭本次查询,标志着本次查询的结束
写流程和读流程基本一致。
impala 和 hive的对比
相同点:
- 数据存储:都支持把数据存储于HDFS, HBase。
- 元数据:两者使用相同的元数据(impala直接使用hive元数据)。
- SQL解释处理:都是通过词法分析生成执行计划。
- 存储格式:都支持ORC、Parquet、Text等格式。
- 数据分析:都是通过对大数据量(HDFS、HBase)进行分析处理。
- 集成性:都可以和ClouderaManager和Ambari集成。
不同点:
执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,是直接返回错误,利用外存,性能会很低。这使用得Impala目前处理Query会受到一定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
- Hive: 任务调度依赖于Hadoop的调度策略。
- Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。
容错:
- Hive: 依赖于Hadoop的容错能力。
- Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败,再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不会影响服务。
- 对于State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
impala的部署模式
混合部署模式
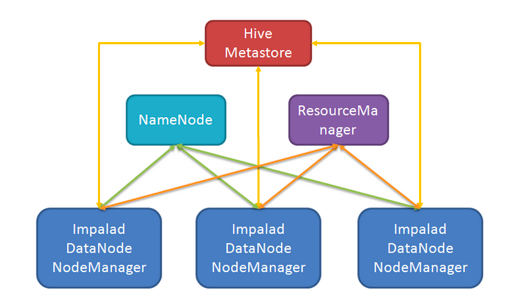
独立部署模式
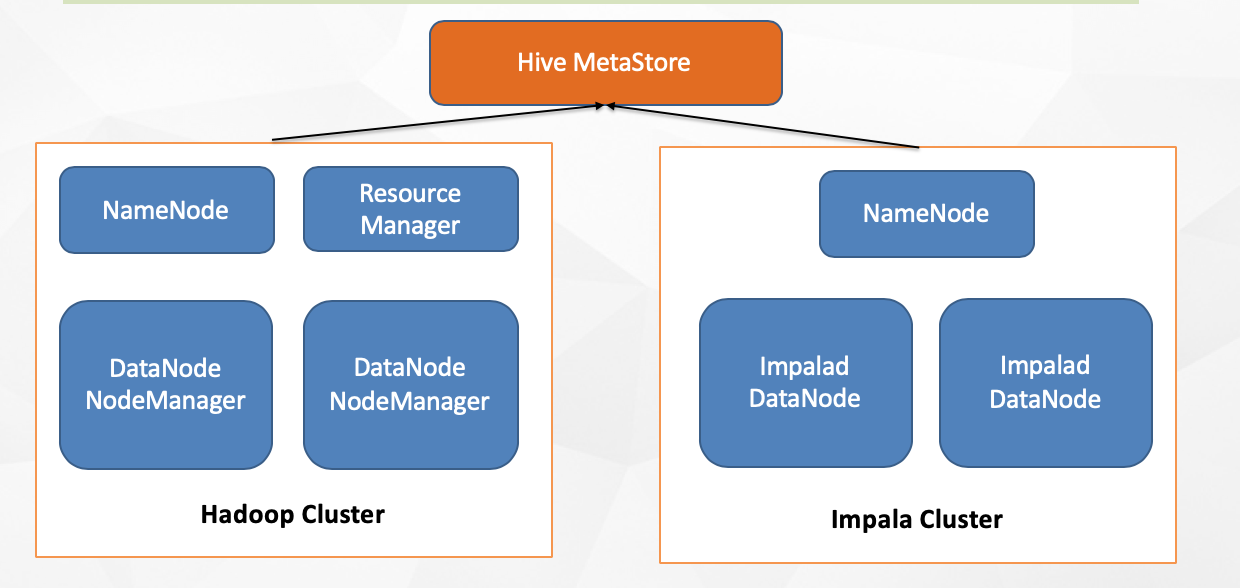
通常情况下,我们会考虑两种方式的集群部署:混合部署和独立部署,上图分别展示了混合部署与独立部署时的各节点结构。
- 混合部署意味着将Impala集群部署在Hadoop集群之上,共享整个Hadoop集群的资源;
- 独立部署则是单独使用部分机器只部署HDFS和Impala;
- 前者的优势是Impala可以和Hadoop集群共享数据,不需要进行数据的拷贝,但是存在Impala和Hadoop集群抢占资源的情况,进而可能影响Impala的查询性能(MR任务也可能被Impala影响),而后者可以提供稳定的高性能,但是需要持续的从Hadoop集群拷贝数据到Impala集群上,增加了ETL的复杂度;
- 两种方式各有优劣,但是针对前一种部署方案,需要考虑如何分配资源的问题,首先在混合部署的情况下不可能再让Impalad进程常驻(这样相当于把每一个NodeManager的资源分出去了一部分,并且不能充分利用集群资源),但是YARN的资源分配机制延迟太大,对于Impala的查询速度有很大的影响,于是Impala很早就设计了一种在YARN上完成Impala资源调度的方案——Llama(Low Latency Application MAster),它其实是一个AM的角色,对于Impala而言。
- 它的要求是在查询执行之前必须确保需要的资源可用,否则可能出现一个Impalad的阻塞而影响整个查询的响应速度(木桶原理),Llama会在Impala查询之前申请足够的资源,并且在查询完成之后尽可能的缓存资源,只有当YARN需要将该部分资源用于其它工作时,Llama才会将资源释放。虽然Llama尽可能的保持资源,但是当混合部署的情况下,还是可能存在Impala查询获取不到资源的情况,所以为了保证高性能,还是建议独立部署。
- 独立部署方案适用于大型公司,集群资源十分充足的情况下,而一些中小型公司混合部署足够用,基于Cm进行静态资源池配置和动态服务池管理。
impala同步hive元数据原理
基础
Impala采用多个impalad(impala的核心进程)同时提供服务的方式,并且它会由catalogd(元数据管理和元数据存储)缓存全部元数据,再通过statestored(状态管理进程)完成每一次的元数据的更新到impalad节点上,Impala集群会缓存全部的元数据。
Impala在传统的Mysql或PostgreSQL数据库称为MetaStore,Hive也在其相同的数据库上保存此类型的数据。因此,Impala可以访问由Hive定义或加载的表,也就是说Impala的操作对于Hive来说是透明的。
这种缓存机制既有优点,也有缺点:
优点在于:对于具有大量数据或多个分区的表,检索表内所有元数据可能会花费很长时间,在某些情况下需要几分钟,每个Impala节点缓存所有这些数据,以便在未来对同一表进行查询时重复使用,这样就可以节省很多不必要的时间。
缺点在于:会导致通过其他手段更新元数据或者数据对于Impala是无感知的,例如通过Hive建表,直接拷贝新的数据到HDFS上等。
但是Impala提供了两种机制来实现元数据的更新,分别是INVALIDATE METADATA和REFRESH操作
INVALIDATE 原理
INVALIDATE METADATA翻译成中文就是“作废元数据”的意思。
对于INVALIDATE METADATA操作,由客户端将查询提交到某个impalad节点上,执行如下的操作:
1.获取需要执行INVALIDATE METADATA的表,如果没指定表则表示全部表。
2.请求catalogd执行resetMetadata操作,并将isFresh参数设置为false。
3.catalogd接收到该请求之后执行invalidateTable操作,将该表的缓存清除,然后重新生成该表的缓存对象,新生成的对象只包含表名+库名的信息,然后为新生成的表对象生成一个新的catalog版本号(假设新的version=1),将这部分信息返回给调用方(impalad),然后异步执行元数据和数据的加载。
4.impalad收到catalogd的返回值,返回值是更新之后的表缓存对象+版本号,但是这是一个不完整的表元数据,impalad将这个元数据应用到本地元数据缓存。
5.INVALIDATE METADATA执行完成。
INVALIDATE METADATA操作带来的副作用是生成一个新的未完成的元数据对象,对于操作请求的impalad(称它为impalad-A),能够立马获取到该对象,对于其它的impalad必须通过statestored同步,执行完该操作,因此处理该操作的impalad对于该表的缓存是一个新的但是不完整的对象,其余的impalad保存的是旧的元数据。
对于后续的该表查询操作,分为如下四种情况:
1.如果catalogd已经完成该表所有元数据加载,会对该表生成一个新的版本号(假设version=2),然后更新到statestored,由statestored广播到各个impalad节点上,此时所有的查询都查询到最新的元数据和数据。
2.如果catalogd尚未完成表的元数据加载或者statestored未广播完成,并且接下来请求到impalad-A(之前执行INVALIDATE METADATA的节点),此时impalad在执行语义分析的时候能够检测到表的元数据不完整(因为当前只有表名和库名,没有任何其余的元数据),impalad会直接请求catalogd获取该表最新的元数据,如果catalogd尚未完成元数据加载,则该请求会等到直到catalogd加载完成并返回
impalad最新的元数据。
3.如果catalogd尚未完成表的元数据加载或statestored未广播完成,接下来请求到了其他的impalad节点,如果接受请求的impalad尚未通过statestored同步新的不完整的表元数据(version=1),则该impalad中缓存的关于该表的元数据是执行INVALIDATE METADATA之前的,因此根据旧的元数据处理该查询(可能因为文件被删除导致错误)。
4.如果catalogd尚未完成表的元数据加载,接下来请求到了其他的impalad节点,如果接受请求的impalad已经通过statestored同步新的不完整的表元数据(version=1),那么接下来会像第二种情况一样处理。
从INVALIDATE METADATA的实现来看,该操作不仅仅会全量加载表的元数据和分区、文件元数据,还会影响后面关于该表的查询。因此、生产环境中的日常操作中尽量避免使用,或者是在资源充足的情况下。
INVALIDATE 使用方式
INVALIDATE METADATA是用于刷新全库或者某个表的元数据,包括表的元数据和表内的文件数据,它会首先清除表的缓存,然后从metastore中重新加载全部数据并缓存,该操作代价比较重,需要消耗大量的资源和时间,主要用于在hive中修改了表的元数据,需要同步到impalad,例如create table/drop table/alter table add columns等。
语法:
INVALIDATE METADATA; //重新加载所有库中的所有表
INVALIDATE METADATA [table] //重新加载指定的某个表
REFRESH 原理
对于REFRESH操作,由客户端将查询提交到某个impalad节点上,执行如下的操作:
1.获取需要执行REFRESH的表和分区信息。
2.请求catalogd执行resetMetadata操作,并将isFresh参数设置为true。
3.catalogd接收到该请求之后判断是否指定分区,如果指定了分区则执行reload partition操作,如果未指定则执行reload table操作,对于reloadPartition则从metastore中读取partition最新的元数据,然后刷新该partition拥有的所有文件的元数据(大小,权限,数据分布等);对于reloadTable则从metadata中读取全部的partition信息,然后和缓存中的partition进行比对判断是否有分区需要增加和删除,对于其余的分区则执行元数据的更新。
4.impalad收到catalogd的返回值,返回值是更新之后该表的缓存数据,impalad会将该数据更新到自己的缓存中。因此接受请求的impalad能够将当前元数据缓存。
5.REFRESH执行完成。
对于后续的查询,分为如下两种情况:
1.如果查询提交到到执行REFRESH的impalad节点,那么查询能够使用最新的元数据。
2.如果查询提交到其他impalad节点,需要依赖于该表更新后的缓存是否已经同步到impalad中,如果已经完成了同步则可以使用最新的元数据,如果未完成则使用旧的元数据。
可以看出REFRESH操作较之于INVALIDATE METADATA是轻量级的操作,如果更改只涉及到一个分区设置可以只刷新一个分区的元数据,并且它是同步的,对于之后查询的影响较小。
REFRESH是用于刷新某个表或者某个分区的数据信息,它会重用之前的表元数据,仅仅执行文件刷新操作,它能够检测到表中分区的增加和减少,主要用于表中元数据未修改,数据的修改,例如INSERT INTO、LOAD DATA、ALTER TABLE ADD PARTITION、ALTER TABLE DROP PARTITION等,如果直接修改表的HDFS文件(增加、删除或者重命名)也需要指定REFRESH刷新数据信息。
语法:
REFRESH [table] //刷新某个表
impala同步hive元数据实操
在hive建测试表
hive> create database ops_test;
OK
Time taken: 0.035 seconds
hive> use ops_test;
OK
Time taken: 0.015 seconds
hive> CREATE EXTERNAL TABLE user (
> id INT,
> username STRING,
> birthday TIMESTAMP,
> sex STRING,
> address STRING
> )
> PARTITIONED BY (
> p_date INT
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> STORED AS TEXTFILE;
OK
Time taken: 0.127 seconds
hive> show tables;
OK
user
Time taken: 0.017 seconds, Fetched: 1 row(s)
在hive 的元数据看中查询表的源数据信息
mysql> select * from TBLS where TBL_NAME="user"; +---------+-------------+--------+------------------+---------+-----------+---------+----------+----------------+--------------------+--------------------+----------------+ | TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | LINK_TARGET_ID | +---------+-------------+--------+------------------+---------+-----------+---------+----------+----------------+--------------------+--------------------+----------------+ | 2318961 | 1566256791 | 474133 | 0 | bigdata | 0 | 4234328 | user | EXTERNAL_TABLE | NULL | NULL | NULL | +---------+-------------+--------+------------------+---------+-----------+---------+----------+----------------+--------------------+--------------------+----------------+ 1 行于数据集 (0.08 秒) mysql> select * from SDS where SD_ID=4234328; +---------+---------+------------------------------------------+---------------+---------------------------+----------------------------------------------------+-------------+------------------------------------------------------------+----------+ | SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID | +---------+---------+------------------------------------------+---------------+---------------------------+----------------------------------------------------+-------------+------------------------------------------------------------+----------+ | 4234328 | 2815006 | org.apache.hadoop.mapred.TextInputFormat | 0 | 0 | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 4234328 | +---------+---------+------------------------------------------+---------------+---------------------------+----------------------------------------------------+-------------+------------------------------------------------------------+----------+ 1 行于数据集 (0.06 秒)
invalidate 命令测试
在impala中同步hive元数据,同步完成之后impala中就会出现刚才在hive中创建的user表
[OPS-HADOOP-01.fblinux.com:21000] > invalidate metadata ops_test.user; Query: invalidate metadata ops_test.user Query submitted at: 2019-08-20 07:27:13 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=c142acee97b05a07:255a84e300000000 Fetched 0 row(s) in 3.55s
在hive中给表创建列测试修改能否同步到impala中
hive> alter table user add columns(comment string); OK Time taken: 0.066 seconds hive> desc user; OK id int username string birthday timestamp sex string address string comment string p_date int # Partition Information # col_name data_type comment p_date int Time taken: 0.048 seconds, Fetched: 12 row(s)
验证数据可以同步到impala
删除表验证
在hive中删除表,并验证表已经正确删除
hive> drop table user; OK hive> show tables; OK Time taken: 0.01 seconds
但是在impala中依然可以看到user表存在
Query: show tables +------+ | name | +------+ | user | +------+ Fetched 1 row(s) in 0.03s
执行刷新元数据操作,user表消失
[OPS-HADOOP-01.fblinux.com:21000] > invalidate metadata ops_test.user; Query: invalidate metadata ops_test.user Query submitted at: 2019-08-20 07:57:25 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=254e3f2afa2b7818:3f74ee7e00000000 Fetched 0 row(s) in 0.02s [OPS-HADOOP-01.fblinux.com:21000] > show tables; Query: show tables Fetched 0 row(s) in 0.01s
refresh 命令测试
(1)测试之前应再把user表创建出来
(2)在hive中插入一条数据,并验证可以正常查询
hive> insert into table user partition(p_date=20190820) values(10,"lili","2019-08-20","","");
Query ID = bigdata_20190820080101_dff1edb9-e595-4381-aaf9-ce2ec606f2b5
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1565267038828_119002, Tracking URL = http://OPS-HADOOP-01.fblinux.com:8088/proxy/application_1565267038828_119002/
Kill Command = /opt/cloudera/parcels/CDH/lib/hadoop/bin/hadoop job -kill job_1565267038828_119002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-08-20 08:01:34,172 Stage-1 map = 0%, reduce = 0%
2019-08-20 08:01:41,432 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.17 sec
MapReduce Total cumulative CPU time: 1 seconds 170 msec
Ended Job = job_1565267038828_119002
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190820/.hive-staging_hive_2019-08-20_08-01-25_337_3642348501353536142-1/-ext-10000
Loading data to table ops_test.user partition (p_date=20190820)
Partition ops_test.user{p_date=20190820} stats: [numFiles=1, numRows=1, totalSize=30, rawDataSize=29]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.17 sec HDFS Read: 3955 HDFS Write: 115 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 170 msec
OK
Time taken: 17.464 seconds
hive> select * from user where p_date=20190820;
OK
10 lili 2019-08-20 00:00:00 20190820
Time taken: 0.182 seconds, Fetched: 1 row(s)
在impala中通过refresh刷新分区信息并查询数据验证
[OPS-HADOOP-01.fblinux.com:21000] > refresh user; Query: refresh user Query submitted at: 2019-08-20 08:05:10 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=c24576d5aeb1fc3a:8e5696ef00000000 Fetched 0 row(s) in 0.21s [OPS-HADOOP-01.fblinux.com:21000] > select * from user where p_date=20190820; Query: select * from user where p_date=20190820 Query submitted at: 2019-08-20 08:05:23 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=c9414bf340d13b7c:9207f45200000000 +----+----------+---------------------+-----+---------+----------+ | id | username | birthday | sex | address | p_date | +----+----------+---------------------+-----+---------+----------+ | 10 | lili | 2019-08-20 00:00:00 | | | 20190820 | +----+----------+---------------------+-----+---------+----------+ Fetched 1 row(s) in 0.86s
再给user表创建一个昨天的分区,并上传一些数据
现在hdfs创建分区目录,并上传测试文件
[bigdata@OPS-HADOOP-01 ~]$ hdfs dfs -mkdir /user/hive/warehouse/ops_test.db/user/p_date=20190819 [bigdata@OPS-HADOOP-01 ~]$ cat file1.txt 1,张三,2018-11-30,man,上海市 2,张小明,2018-09-22,man,上海市 3,张三丰,2018-11-03,man,上海市 4,陈小明,2018-12-01,man,上海市 5,王大军,2018-12-12,man,上海市 [bigdata@OPS-HADOOP-01 ~]$ hdfs dfs -put file1.txt /user/hive/warehouse/ops_test.db/user/p_date=20190819 [bigdata@OPS-HADOOP-01 ~]$ hdfs dfs -ls /user/hive/warehouse/ops_test.db/user/p_date=20190819 Found 1 items -rw-rw-r-- 2 bigdata bigdata 182 2019-08-20 08:12 /user/hive/warehouse/ops_test.db/user/p_date=20190819/file1.txt [bigdata@OPS-HADOOP-01 ~]$ hdfs dfs -text /user/hive/warehouse/ops_test.db/user/p_date=20190819/file1.txt 1,张三,2018-11-30,man,上海市 2,张小明,2018-09-22,man,上海市 3,张三丰,2018-11-03,man,上海市 4,陈小明,2018-12-01,man,上海市 5,王大军,2018-12-12,man,上海市
在hive中创建分区并验证数据可查
hive> alter table user add partition(p_date=20190819); OK Time taken: 0.061 seconds hive> show partitions user; OK p_date=20190819 p_date=20190820 hive> select * from user where p_date=20190819; OK 1 张三 NULL man 上海市 20190819 2 张小明 NULL man 上海市 20190819 3 张三丰 NULL man 上海市 20190819 4 陈小明 NULL man 上海市 20190819 5 王大军 NULL man 上海市 20190819 Time taken: 0.06 seconds, Fetched: 5 row(s)
但是在hive中创建的分区并没有同步到impala中
[OPS-HADOOP-01.fblinux.com:21000] > show partitions user; Query: show partitions user +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | p_date | #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | 20190820 | 1 | 1 | 30B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190820 | | Total | -1 | 1 | 30B | 0B | | | | | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ Fetched 2 row(s) in 0.02s
使用refresh同步后就可以看到分区和数据了
[OPS-HADOOP-01.fblinux.com:21000] > refresh user; Query: refresh user Query submitted at: 2019-08-20 08:21:15 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=7c4b690e894cd92e:1e96412200000000 Fetched 0 row(s) in 0.07s [OPS-HADOOP-01.fblinux.com:21000] > show partitions user; Query: show partitions user +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | p_date | #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | 20190819 | -1 | 1 | 182B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190819 | | 20190820 | 1 | 1 | 30B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190820 | | Total | -1 | 2 | 212B | 0B | | | | | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ Fetched 3 row(s) in 0.02s [OPS-HADOOP-01.fblinux.com:21000] > select * from user where p_date=20190819; Query: select * from user where p_date=20190819 Query submitted at: 2019-08-20 08:21:44 (Coordinator: http://OPS-HADOOP-03.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-03.fblinux.com:25000/query_plan?query_id=e54a33d7f73c34fc:9612ec5c00000000 +----+----------+---------------------+-----+---------+----------+ | id | username | birthday | sex | address | p_date | +----+----------+---------------------+-----+---------+----------+ | 1 | 张三 | 2018-11-30 00:00:00 | man | 上海市 | 20190819 | | 2 | 张小明 | 2018-09-22 00:00:00 | man | 上海市 | 20190819 | | 3 | 张三丰 | 2018-11-03 00:00:00 | man | 上海市 | 20190819 | | 4 | 陈小明 | 2018-12-01 00:00:00 | man | 上海市 | 20190819 | | 5 | 王大军 | 2018-12-12 00:00:00 | man | 上海市 | 20190819 | +----+----------+---------------------+-----+---------+----------+ Fetched 5 row(s) in 0.71s
验证删除分区操作
在hive中删除分区
hive> alter table user drop partition(p_date=20190819); Dropped the partition p_date=20190819 OK Time taken: 0.351 seconds hive> show partitions user; OK p_date=20190820 Time taken: 0.037 seconds, Fetched: 1 row(s)
在impala中因为元数据缓存的原因依然可以看到之前的分区表信息
[OPS-HADOOP-01.fblinux.com:21000] > show partitions user; Query: show partitions user +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | p_date | #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | 20190819 | -1 | 1 | 182B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190819 | | 20190820 | 1 | 1 | 30B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190820 | | Total | -1 | 2 | 212B | 0B | | | | | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------
通过refresh刷新元数据后问题消失
[OPS-HADOOP-01.fblinux.com:21000] > refresh user; Query: refresh user Query submitted at: 2019-08-20 08:35:48 (Coordinator: http://OPS-HADOOP-06.fblinux.com:25000) Query progress can be monitored at: http://OPS-HADOOP-06.fblinux.com:25000/query_plan?query_id=144f3be7cda539b7:2153b7b000000000 Fetched 0 row(s) in 0.09s [OPS-HADOOP-01.fblinux.com:21000] > show partitions user; Query: show partitions user +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | p_date | #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ | 20190820 | 1 | 1 | 30B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://Ops-test/user/hive/warehouse/ops_test.db/user/p_date=20190820 | | Total | -1 | 1 | 30B | 0B | | | | | +----------+-------+--------+------+--------------+-------------------+--------+-------------------+--------------------------------------------------------------------+ Fetched 2 row(s) in 0.10s
转载请注明:西门飞冰的博客 » impala 实时分析引擎介绍