1.案例十一
描述:公司集群的NameNode今天发生了故障,你想通过分析fsimage文件来排查问题。你需要下载最新的fsimage文件,命名为 “timestamp_xxxxxxxxxx”,其中xxxxxxxxxx为以秒为单位的Unix时间戳, 代表你操作时的当前时间。并上传到HDFS的/user/cert/problem11目录下。
操作流程:
1、进入gateway的命令行,hdfs dfsadmin -fetchImage ./
2、mv fsimage_00000xxxxx timestamp_`date +%s`
3、确认下HDFS的/user/cert/problem11目录是否存在,如不存在需要建立 hdfs dfs -mkdir -p /user/cert/problem11
4、上传fsimage文件:hdfs dfs -copyFromLocal timestamp_xxxxxxxxxx /user/cert/ problem11
2.案例十二
描述:公司的集群新扩充了一批工作节点,但是新的工作节点上没有数 据,造成整个集群数据分布不均衡。你知道HDFS的balancer功能可以解决这个问题。请将balancer操作占用的带宽限制为1G以内,并以阀值5 启动balancer操作。
操作流程:
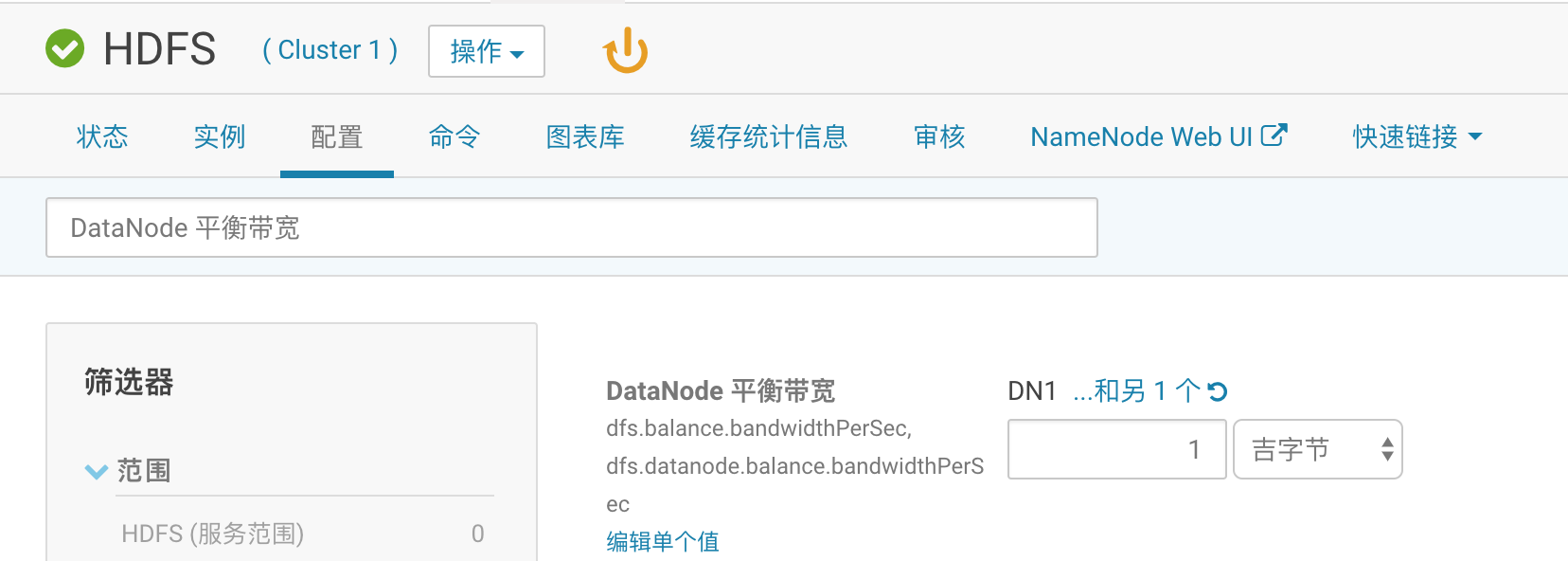
1、点击HDFS,配置,找到” DataNode 平衡带宽”设 置为1GB,找到”重新平衡阈值”设置为5

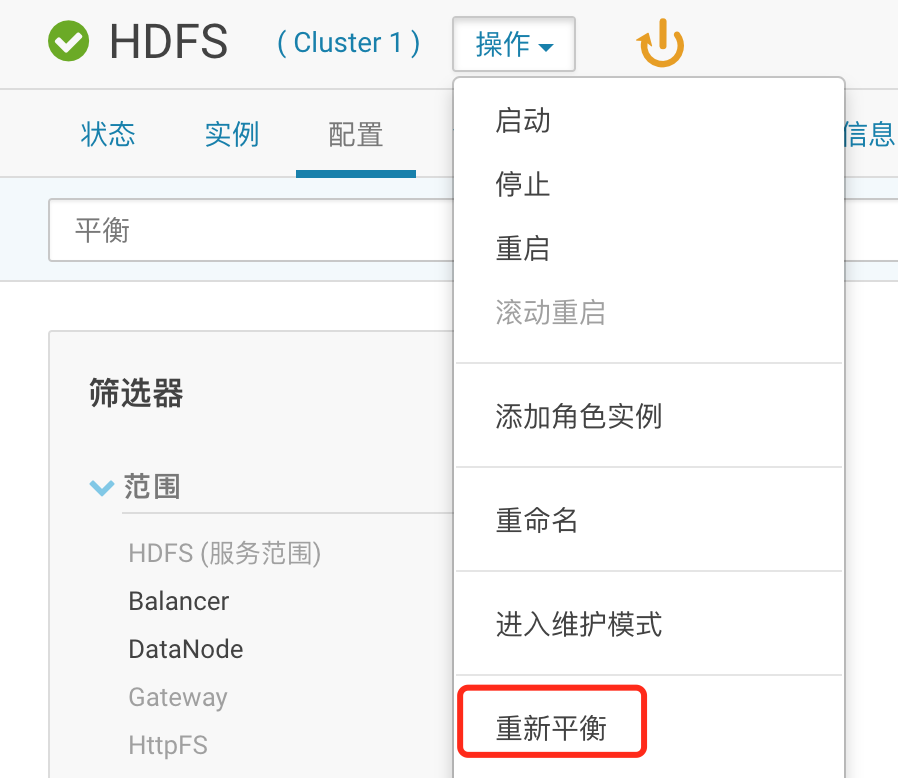
2、点击“操作”- “重新平衡”(或者进入gateway的命令行,执行hdfs balancer -threshold 5)
3.案例十三
描述:公司的某用户在HDFS上存放了重要的文件,但是不小心将其删除 了。幸运的是,该目录被设置为可快照的,并曾经创建过几次快照。请 使用最近的一个快照恢复数据。要求为恢复/user/cert/problem13目录 下的所有文件,并恢复文件原有的权限、所有者、ACL。
操作步骤:
(1)快照功能需要升级到企业版
1、在主界面,右上角点击试用cloudera enterprise 60天,按照引导操作即可。
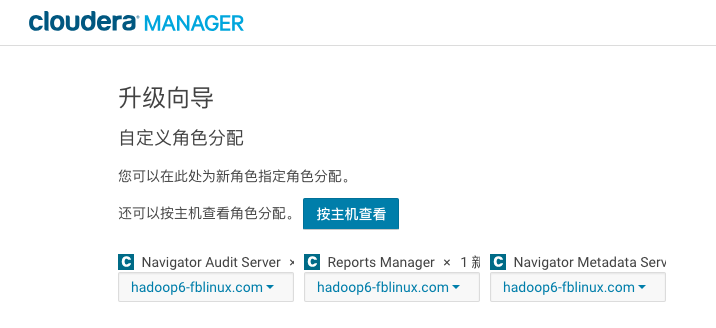
2、升级企业版过程中,有3个服务需要安装,这里安装到空闲的节点即可。
(2)上传测试数据
[hdfs@hadoop1-fblinux ~]$ hdfs dfs -mkdir -p /fblinux/ [hdfs@hadoop1-fblinux ~]$ hdfs dfs -copyFromLocal /etc/fstab /fblinux/ [hdfs@hadoop1-fblinux ~]$ hdfs dfs -ls /fblinux/ Found 1 items -rw-r--r-- 3 hdfs supergroup 551 2019-02-25 19:35 /fblinux/fstab
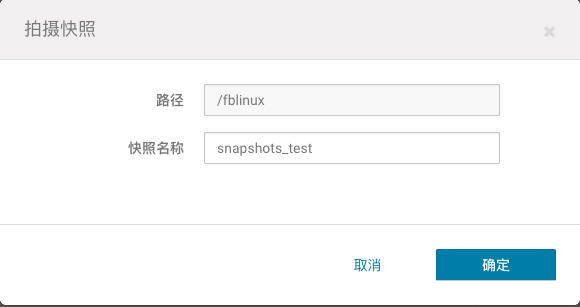
(3)在CM中启用该目录的快照特性,并打快照

(4)删除之前上传的文件
[hdfs@hadoop1-fblinux ~]$ hdfs dfs -rm -f /fblinux/fstab
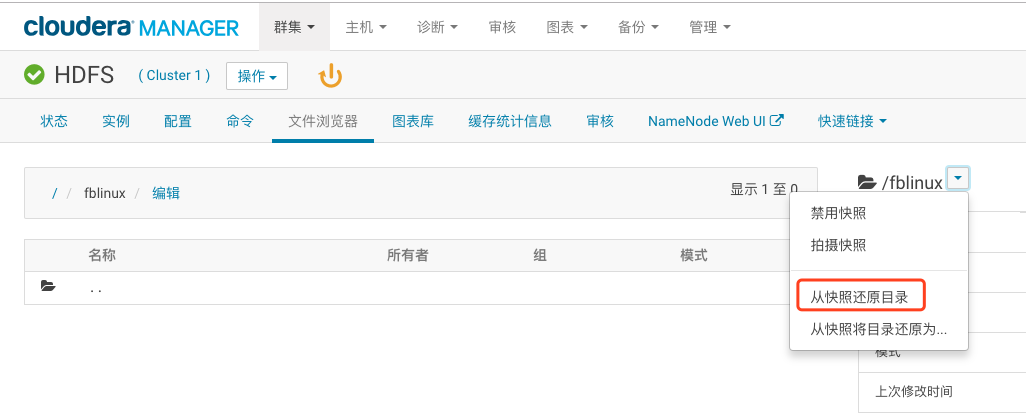
(5)恢复快照

4.案例十四
描述:公司一个运维人员尝试优化集群,但反而使得一些以前可以运行 的MapReduce作业不能运行了。请你识别问题并予以纠正,并成功运行 性能测试,要求为在Linux文件系统上找到hadoop-mapreduce- examples.jar包,并使用它完成三步测试:
1、使用teragen 10000000 problem14/ts_input 生成10000000行测 试记录并输出到指定目录
2、使用terasort problem14/ts_input problem14/ts_output 进行 排序并输出到指定目录
3、使用teravalidate problem14/ts_output problem14/ ts_validate检查输出结果
操作步骤:
1、生成输入数据
[hdfs@hadoop1-fblinux ~]$ cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/ [hdfs@hadoop1-fblinux hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 fblinux_input
2、排序和输出
[hdfs@hadoop1-fblinux hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar terasort fblinux_input fblinux_output
3、验证输出
[hdfs@hadoop1-fblinux hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar teravalidate fblinux_output fblinux/ts_validata
5.案例十五
描述:今天hadoop3节点的DataNode和NodeManager进程频繁死掉,你决 定临时将该节点这两个进程的日志级别调整为DEBUG,以便于进行故障 排查。
操作步骤:
1、点击“主机”—“所有主机”,点开hadoop3节点的roles,点击HDFS datanode,进入配置页面

2、搜索“DataNode 记录阈值”将其改为DEBUG并保存。

3、回到“所有主机”页面,点开hadoop3节点的roles,点击YARN NodeManager,进入配置页面
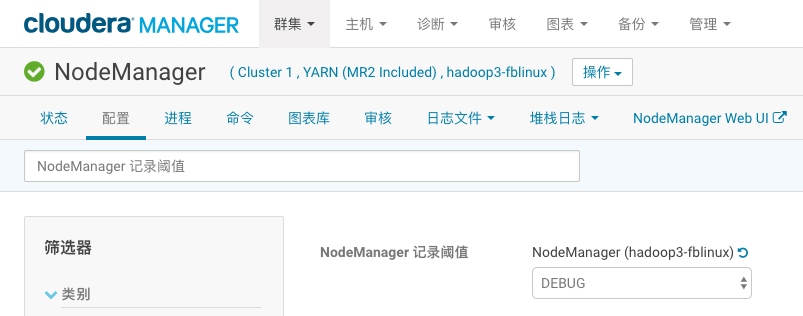
6.案例十六
描述:公司的某个开发人员尝试在集群上运行wordcount程序,但作业 执行时发生错误,请你帮助解决。请将gateway机器cert家目录下的 input.txt文件上传到HDFS上cert家目录下的problem16/input中,并执行wordcount problem16/input/input.txt problem16/output来测试是否可以运行。
操作流程:
1、上传文件
su - cert hdfs dfs -mkdir -p /user/cert/problem16/input hdfs dfs -copyFromLocal input.txt /user/cert/problem16/input 2
2、执行wordcount
cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/ hadoop jar hadoop-mapreduce-examples.jar wordcount problem16/ input problem16/output
发现报目录存在的Exception,于是:
hdfs dfs -rmr /user/cert/problem16/output hadoop jar hadoop-mapreduce-examples.jar wordcount problem16/ input problem16/output
7.案例十七
描述:对集群进行例行检查的时候,你发现有个别重要文件的副本数只 有2个,而集群默认的副本数参数为3个,并没有修改过。请解决/user/ cert/problem14/ts_input目录下的文件副本数不足的问题
操作步骤:
1、在命令行修改目录下所有文件的副本数
hdfs dfs -setrep 3 /user/cert/problem14/ts_input
8.案例十八
描述:你发现,集群中一些大文件的块大小为64MB,导致MapReduce作 业使用这些文件时,默认会产生较多的map数,造成资源浪费。你决定 将这些文件以128MB的块大小备份到另一个目录中。请将/user/cert/ problem18/input下的文件以128MB的块大小备份到/user/cert/ problem18/output下。
操作:
1、确认集群默认的块大小,点击HDFS,配置,找到”HDFS Block Size”,已经是128MB了,因此备份时不需要加指定块大小的参数。

2、创建备份目录并复制
hdfs dfs -mkdir /user/cert/problem18/output hdfs dfs -cp /user/cert/problem18/input/part-r-00000 /user/cert/ problem18/output
9.案例十九
描述:升级集群版从CDH5.13.0到CDH5.14.0: 保持集群版本处于比较新的状态,可以尽量避免已知的bug,并享受新版 本的特性。通常实践中推荐使用比最新版本的版本号中间位低1-2的集群。 另外需要注意CM只能管理不高于其版本的CDH,如CM5.13最高只能将集群 版本升级到CDH5.13。如果CM版本不够,则需要先升级CM,后升级CDH。
CM升级参见:
https://www.cloudera.com/documentation/enterprise/5-10-x/topics/ cm_ag_ug_cm5.html
CDH升级参见:
https://www.cloudera.com/documentation/enterprise/5-10-x/topics/cm_mc_upgrading_cdh.html
步骤:
1、清理一下磁盘空间,保证每个节点有20G以上的空间,集群可以不用启动。
2、主机 – Parcels – 配置,在远程parcel存储库URL下新增一项https://archive.cloudera.com/cdh5/parcels/5.14.0/
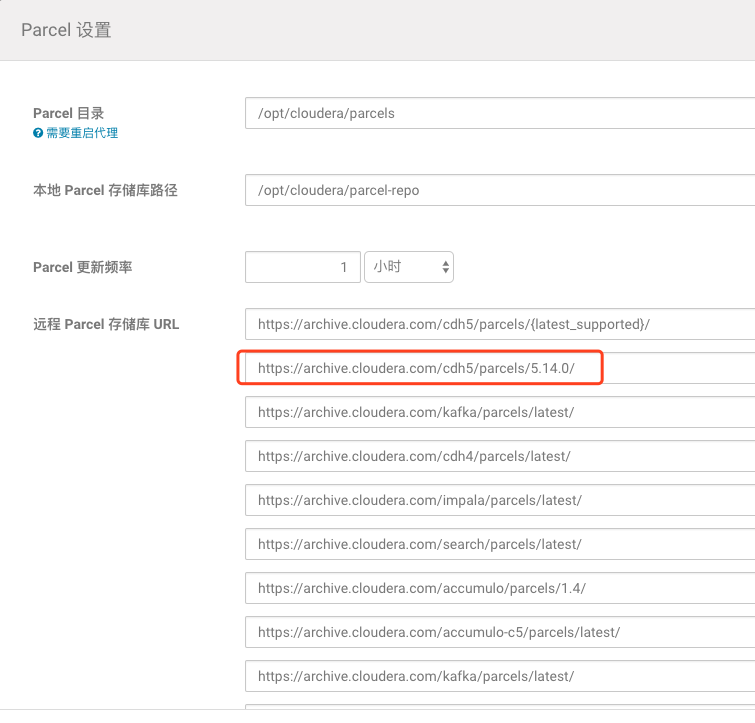
3、集群名右侧的小箭头,升级集群
4、选择CDH 5.14.0-1.cdh5.14.0.p0.24,然后一路Continue
10.案例二十
开启NameNode HA:
NameNode HA的配置参见: https://www.cloudera.com/documentation/enterprise/5-10-x/topics/ cdh_hag_hdfs_ha_config.html
操作步骤:
1、集群可以不用启动,但ZooKeeper需要先起来
2、点击HDFS服务,点击操作 – 启用High Availability

3、Nameservice Name默认即可
4、NameNode Hosts一个仍是hadoop1,另一个选hadoop2。JournalNode Hosts可选hadoop3-5

5、输入hadoop3-5上用于JN的磁盘目录,设为/dfs/jn
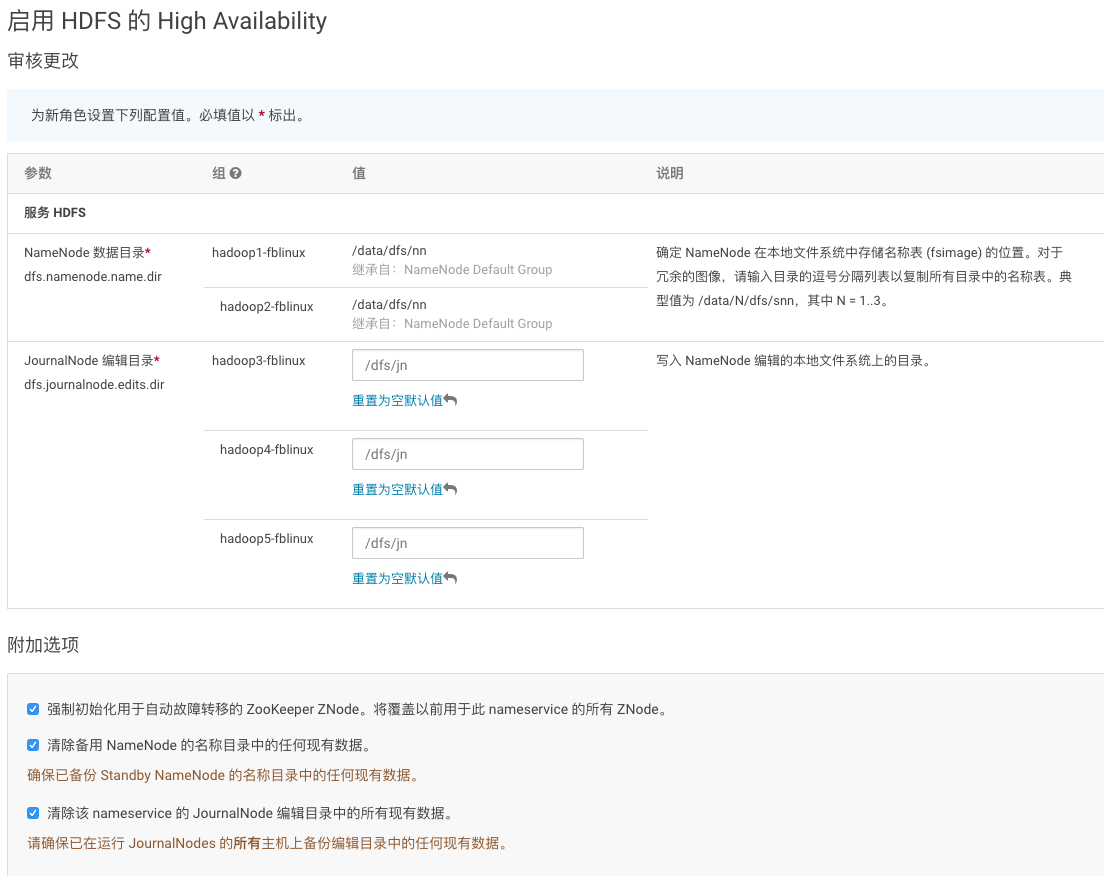
6、下一个页面等待运行完成即可。其中Format NameNode一步会失败,这 是符合预期的
7、HA配置完成之后,实例分布如下图所示

转载请注明:西门飞冰的博客 » CDH 20个实战案例