二级索引介绍
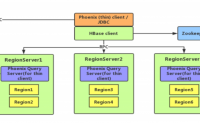
Phoenix的一级索引就是它的主键,对应的就是hbase的rowkey,这个是默认的机制,我们不需要额外操作。
故二级索引就是非主键/rowkey列的索引。创建二级索引的目的就是为了加快查询速度。
Hbase只能基于rowkey去查询数据,要是基于其他列查询数据就...
2年前 (2022-12-27) 1955℃
0喜欢
Phoenix定义
Phoenix 是HBASE的一个加分项,往往一些考虑使用HBASE的场景还是因为有着Phoenix的加持。如果只是单纯的考虑把数据存到HBASE,然后做一些简单的查询,Hbase一定是可以满足的。但是要对HBASE的数据做一些分析,这个时候HBASE 就出现...
2年前 (2022-12-27) 3638℃
0喜欢
状态一致性的概念
对于Flink流处理器来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确,一条数据不应该丢失,也不应该重复计算。
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
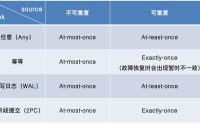
状态一致性的级别
最多一次(AT-MOST-ONCE)
当任务故障...
2年前 (2022-12-23) 377℃
0喜欢
状态持久化
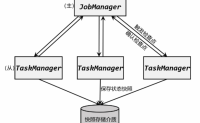
在Flink的状态管理机制中,Flink 容错性的保障就是要对状态数据做一个持久化的保存,这样就可以在发生故障后通过持久化数据进行重启恢复。在Flink 中对状态进行持久化的方式,就是将当前所有分布式状态进行“快照”保存,写入一个“检查点”(checkpoint)或者...
2年前 (2022-12-23) 1596℃
0喜欢
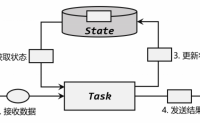
状态的概念
在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
什么场景会用到状态,下面列举了三种场景:
去重:比如上游的系统数...
2年前 (2022-12-23) 1463℃
0喜欢
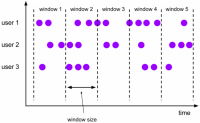
窗口的概念
我们知道Flink是一个可以处理无限流的流式处理引擎,无限流有个特点就是数据无休无止,源源不断,这种情况下要是想做统计聚合的话,就没有数据的尽头,因为数据在一直不停的更新。
在这种情况下,业务就想看之前一个小时或者一天的数据,就需要人为的给无界流增加一个界限,一个范围...
2年前 (2022-12-20) 2583℃
5喜欢
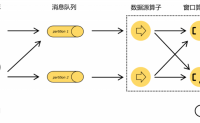
Flink中的时间语义
如上图所示,在事件发生之后,生成的数据被收集起来,首先进入消息队列,然后被Flink系统中的Source算子读取消费,进而向下游的转换算子传递,最终由窗口进行计算处理。
很明显这里面有两个时间点
Event Time:是事件创建的时间,叫...
2年前 (2022-12-20) 1377℃
0喜欢
什么是中断机制
首先:
一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止。
所以,Thread.stop, Thread.suspend, Thread.resume 都已经被废弃了。
其次:
在Java中没有办法立即停止一条线程,然而停止线程却显得尤为重要,...
2年前 (2022-12-09) 3506℃
5喜欢
Future 介绍
Future 是Java5新加的一个接口,它提供了一种异步并行计算的功能。
如果主线程需要执行一个很耗时的计算任务,我们就可以通过future把这个任务放到异步线程中执行。主线程继续处理其他任务或者先行结束,在通过Future获取计算结果。
一句话:Futur...
2年前 (2022-12-07) 1429℃
0喜欢