前言
输出这篇文章,至少参考了五个不同的spark优化文档,删除了不少调整不调整感觉对性能变化没啥用的内容,查漏补缺总结了如下十二条spark性能调优内容,感觉总结的也是相当全了。
调优一:资源配置
Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分...
2年前 (2022-10-29) 1128℃
0喜欢
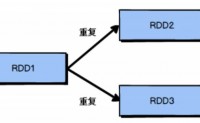
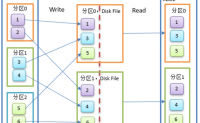
Spark Shuffle的演进过程
Spark最初版本HashShuffle。
Spark 0.8.1版本以后优化后的HashShuffle。
Spark1.1版本加入SortShuffle,默认是HashShuffle。
Spark1.2版本默认是SortShuffle,但是...
2年前 (2022-10-29) 6787℃
0喜欢
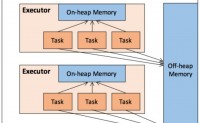
介绍
Spark是基于内存的分布式计算引擎,其内置强大的内存管理机制,保证数据优先内存处理,并支持数据磁盘存储。
在执行Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 S...
2年前 (2022-10-29) 5944℃
0喜欢
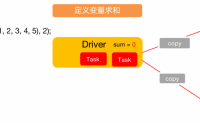
介绍
一般情况下,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量被复制到每台机器上,并且这些变量在远程机器上 的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是...
2年前 (2022-10-29) 1380℃
0喜欢