为什么需要分布式锁
在分布式架构中,多个程序访问统一资源的时候,传统的synchronized是无效的,它只针对一个JVM进程内多个线程起到同步作用,对跨进程无效。
解决方案:
1、利用数据库select … for update 语句对库存进行锁定,依赖数据库自身特...
2年前 (2022-10-08) 1257℃
0喜欢
说明
Hive自带了一些函数,比如:max/min等,但是数量有限,碰到一些个性化业务需求,比如数据加密脱敏、URL解码、身份证校验、解析IP和手机号归属地,就可以通过自定义UDF来方便的扩展。
官方文档:https://cwiki.apache.org/confluence/d...
2年前 (2022-10-07) 1104℃
0喜欢
结论
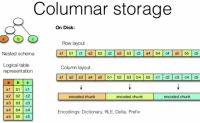
hive 压缩和存储组合推荐使用:orc + snappy 获得最好的性能和合理的压缩率
存储格式选择
Hive支持的存储数据的格式主要有:textfile 、orc、parquet。
textfile存储格式是基于行存储的,实际生产不使用,一般只有数仓的ODS原始数据层使...
2年前 (2022-10-04) 7508℃
1喜欢
前言
本文主要介绍如果通过openresty+lua实现一个前端埋点服务,实现功能如下:
(1)用户上传数据实现简单的鉴权
(2)允许跨域请求
(3)获取用户上传的body内容和部分header头,拼接成最终完成的埋点信息,发送给Kafka
架构图如下:
配置
(1)编译安装o...
3年前 (2022-01-20) 2314℃
21喜欢
背景
业务数据库中有一些mysql表,这些表的记录会被增删改,我们的需求是需要吧这些mysql表实时同步到大数据数仓的impala中,作为数仓的维表来进行使用,因此需要实时的反映这些表的变化情况。
StreamSets Data Collector(SDC)是目前最先进的可视化数...
3年前 (2021-11-13) 4550℃
31喜欢
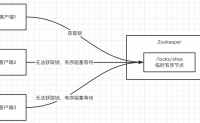
背景
和第三方公司进行数据集成,因为第三方服务和我们不是部署在一个数据中心,所以需要给第三方的程序开放Kafka的公网访问
问题:Kafka 无法同时内外网访问
Kafka 默认只暴露出来一个地址放到zk中,用户请求Kafka的时候,会返回zk中的地址给客户端进行访问,就算做了公...
3年前 (2021-11-13) 2774℃
2喜欢
需求:
HUE 默认限制数据导出条数为10W,但是我们由个需求,数据量是12万,导致无法通过HUE导出
环境:CDH 6.3.2
解决
在服务器手动修改HUE配置文件(注:服务器端没有修改入口),在默认值后添加一个0即可
vim /opt/cloudera/parcels/CDH...
4年前 (2021-06-22) 2903℃
85喜欢
简介
因为CDH5和6架构使用组件间紧耦合架构,不提供组件的独立升级,如果在使用CDH过程中,有需要独立升级组件的需求,就需要尝试和Apache的社区版本进行结合部署,本文以独立升级hive为例进行展示。
环境说明
操作系统:centos 7.8
CDH 版本6.3.2
hive...
4年前 (2021-06-14) 4188℃
8喜欢
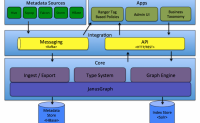
Atlas介绍
Apache atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。
核心组件
core
Ingest/Export:Ingest 组件允许将元数据添加到 ...
4年前 (2021-02-22) 3669℃
39喜欢
1、ClickHouse产生背景
随着科技的发展,时代的进步,数据分析师已经不再满足于传统的T+1式报表或需要提前设置好维度与指标的OLAP查询。数据分析师更希望使用可以支持任意指标、任意维度并秒级给出反馈的大数据Ad-hoc查询系统。这对大数据技术来说是一项非常大的挑战,传统的...
4年前 (2021-02-09) 6776℃
7喜欢