Canal局限性
时效性问题
mysql 主从复制存在延迟,不适合对数据同步实时性要求高的场景
注:复制有延迟这个问题mysql自身都解决不了,更不要指望第三方工具解决,这也是为什么很多生产mysql不开启读写分离的原因
canal 高可用问题
canal 挂载主库:mysq...
2年前 (2022-10-18) 1893℃
3喜欢
场景介绍
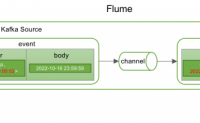
在大数据业务采集场景中,经常会通过Flume把Kafka中的数据落地到HDFS进行持久保存和数据计算。为了数据计算和运维方便,通常会把每天的数据在HDFS通过天分区独立存储。
在数据落入HDFS 天分区目录的过程中,会出现数据跨天存储的问题,本来是2022年6月16日的...
2年前 (2022-10-18) 1839℃
2喜欢
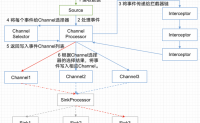
Flume 内部原理
本文主要使用其中的Interceptor和Channel Selector
Interceptor:
对source中的数据在进入channel之前进行拦截做一些处理,比如过滤掉一些数据,或者加上一些key/value等。flume内置了一些拦截器,也可以...
2年前 (2022-10-18) 1769℃
1喜欢
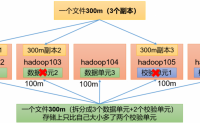
纠删码介绍
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余开销。Hadoop3.x引入了纠删码,通过计算生成数据单元+计算单元的存储的方式,可以节省约50%左右的存储空间,这种存储方式同样也可以容忍集群中最多出现两台服务器同时宕机(注意:不同...
2年前 (2022-10-15) 1054℃
0喜欢
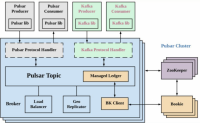
KOP 介绍
KoP(Kafka on Pulsar)通过在 Pulsar 代理上引入 Kafka 协议处理程序,为 Apache Pulsar 带来了原生的Apache Kafka协议支持。通过将 KoP 协议处理程序添加到您现有的 Pulsar 集群,您可以将现有的 Kafk...
2年前 (2022-10-14) 1322℃
1喜欢
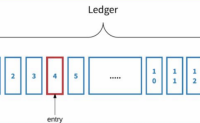
bookkeeper 集群的架构
Apache BookKeeper 是企业级存储系统,旨在保证高持久性、一致性与低延迟。
企业级的实时存储平台需要具备的特点:
以极低的延迟(小于 5 毫秒)读写 entry 流
能够持久、一致、容错地存储数据
在写数据时,能够进行流式传输或...
2年前 (2022-10-14) 1254℃
0喜欢
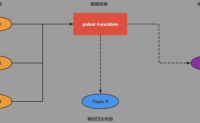
function 背景
当我们进行流式处理的时候,很多情况下,我们的需求可能只是下面这些简单的操作:简单的ETL 操作\聚合计算操作等相关服务。
但为了实现这些功能,我们不得不去部署一整套 流处理服务(spark、flink等)。但是我们仅仅需要这些服务的一小部分功能,部署流处理...
2年前 (2022-10-14) 3357℃
0喜欢
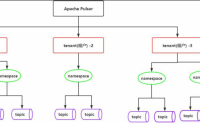
多租户模式
什么是多租户
Apache Pulsar 最初诞生于雅虎,当时就是为了解决雅虎内部各个部门之间数据的协调,所以多租户特性显得至关重用,Pulsar 从诞 生之日起就考虑到多租户这一特性,并在后续的实现过程中,将其不断的完善。 多租户这一特性,使得各个部门之间可以共享同...
2年前 (2022-10-14) 2958℃
1喜欢
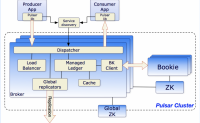
Pulsar 基本介绍
背景
Apache Pulsar 是一个云原生企业级的发布订阅(pub-sub)消息系统2012年雅虎孵化,2016年开源成为apache的顶级项目,Pulsar 已经被腾讯、智联招聘、涂鸦智能、中国移动、中国电信、360、达达集团(京东到家)、苏宁、平安...
2年前 (2022-10-14) 2468℃
2喜欢
Kafka-Kraft模式介绍
Kafka 2.8.0 正式发布了Kraft的先行版,并且支持在Kraft模式下的部署和运行。KRaft模式下的Kafka可以完全脱离zookeeper运行,使用自己的基于Raft算法实现的quorum来保证分布式Metadata的一致
左图为K...
2年前 (2022-10-12) 2605℃
0喜欢