Flink中的时间语义
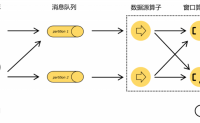
如上图所示,在事件发生之后,生成的数据被收集起来,首先进入消息队列,然后被Flink系统中的Source算子读取消费,进而向下游的转换算子传递,最终由窗口进行计算处理。
很明显这里面有两个时间点
Event Time:是事件创建的时间,叫...
2年前 (2022-12-20) 1402℃
0喜欢
前言
数据倾斜是大数据计算中一个最棘手的问题,出现数据倾斜后,Spark 作业的性能会比期望值差很多,两大直接后果:Spark 任务 OOM 异常退出和数据倾斜拖慢整个任务的执行。数据倾斜的调优,就是利用各种技术方案解决不同类型的数据倾斜问题,保证 Spark 作业的性能。
导致...
2年前 (2022-10-31) 1072℃
4喜欢
前言
输出这篇文章,至少参考了五个不同的spark优化文档,删除了不少调整不调整感觉对性能变化没啥用的内容,查漏补缺总结了如下十二条spark性能调优内容,感觉总结的也是相当全了。
调优一:资源配置
Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分...
2年前 (2022-10-29) 1114℃
0喜欢
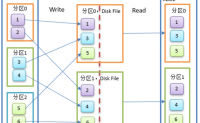
Spark Shuffle的演进过程
Spark最初版本HashShuffle。
Spark 0.8.1版本以后优化后的HashShuffle。
Spark1.1版本加入SortShuffle,默认是HashShuffle。
Spark1.2版本默认是SortShuffle,但是...
2年前 (2022-10-29) 6759℃
0喜欢
介绍
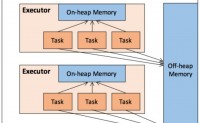
Spark是基于内存的分布式计算引擎,其内置强大的内存管理机制,保证数据优先内存处理,并支持数据磁盘存储。
在执行Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 S...
2年前 (2022-10-29) 5919℃
0喜欢
介绍
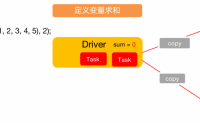
一般情况下,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量被复制到每台机器上,并且这些变量在远程机器上 的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是...
2年前 (2022-10-29) 1343℃
0喜欢
依赖关系
血缘关系介绍
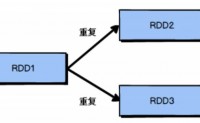
多个连续的RDD的依赖关系,称之为血缘关系,通过RDD的血缘关系,就可以构建出DAG 有向无环图。
RDD为了提高容错性,需要将RDD间的关系保存下来,一旦出现错误,可以根据血缘关系将数据源重新读取进行计算。
查看血缘关系
任意转换算子使用 toDebug...
2年前 (2022-10-27) 2876℃
2喜欢
介绍
持久化的作用,供RDD的重复使用,针对计算耗时比较长,可以提高计算的效率,针对数据比较重要的数据保存到持久化中,数据的安全性也可以得到保障。
持久化操作是在行动算子执行时完成的。
注意:RDD中不存储数据,如果一个RDD需要重复使用,那么需要从头再次执行来获取数据,RD...
2年前 (2022-10-27) 5896℃
0喜欢
前言
默认情况下,Spark可以将一个作业切分多个任务后,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。注意:这里的并行执行的任务数量,并不是指的切分任务的数量。
Spark分区的目的是为了并行计算,因为一个分区就是...
2年前 (2022-10-27) 2727℃
0喜欢
前言
Spark的部署方式虽然有多种模式,如:本地local、Standalone、Apache Mesos、Hadoop YARN等,但是大家90%以上的场景用的都是spark on yarn的模式。
Spark on yarn运行分两种模式:1.Yarn-Cluster模式;...
2年前 (2022-10-27) 1888℃
1喜欢