介绍
通过API实现双流join有个弊端,就是不管是基于窗口join还是状态join都只支持内连接
Flink这个时候要支持其他连接就需要用到flink sql 进行join了
内连接
内连接:合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
代码示例...
2年前 (2023-01-15) 5105℃
0喜欢
为什么使用bitmap表
存储成本低
好处一: 如果有一个超大的无序且不重复的整数集合,用Bitmap的存储成本是非常低的。
假设有个1,2,5的数字集合,如果常规的存储方法,要用3个Int32空间。其中一个Int32就是32位的空间。三个就是3*32Bit,相当于12个字节。
...
2年前 (2023-01-14) 2615℃
3喜欢
FlinkAPI的join方式
使用Flink API要做双流join的话,flink提供了两种方式,一种是基于窗口的window join和基于状态的lnterval join
Flink Join算子有非常严厉的限制,就是必须基于时间
通过API实现双流join有个弊端,就是...
2年前 (2023-01-02) 2482℃
2喜欢
介绍
在Flink中无论是基本的简单转换和聚合,还是基于窗口的计算,我们都是针对一条流上的数据进行处理的。而在实际应用中,可能需要将不同来源的数据连接合并在一起处理,也有可能需要将一条流拆分开,所以经常会有对多条流进行处理的场景。
简单划分的话,多流转换可以分为“分流”和“合流”...
2年前 (2023-01-02) 1502℃
1喜欢
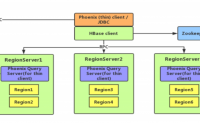
二级索引介绍
Phoenix的一级索引就是它的主键,对应的就是hbase的rowkey,这个是默认的机制,我们不需要额外操作。
故二级索引就是非主键/rowkey列的索引。创建二级索引的目的就是为了加快查询速度。
Hbase只能基于rowkey去查询数据,要是基于其他列查询数据就...
2年前 (2022-12-27) 1990℃
0喜欢
Phoenix定义
Phoenix 是HBASE的一个加分项,往往一些考虑使用HBASE的场景还是因为有着Phoenix的加持。如果只是单纯的考虑把数据存到HBASE,然后做一些简单的查询,Hbase一定是可以满足的。但是要对HBASE的数据做一些分析,这个时候HBASE 就出现...
2年前 (2022-12-27) 3663℃
0喜欢
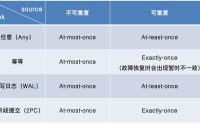
状态一致性的概念
对于Flink流处理器来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确,一条数据不应该丢失,也不应该重复计算。
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
状态一致性的级别
最多一次(AT-MOST-ONCE)
当任务故障...
2年前 (2022-12-23) 392℃
0喜欢
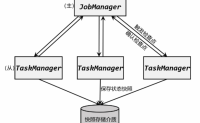
状态持久化
在Flink的状态管理机制中,Flink 容错性的保障就是要对状态数据做一个持久化的保存,这样就可以在发生故障后通过持久化数据进行重启恢复。在Flink 中对状态进行持久化的方式,就是将当前所有分布式状态进行“快照”保存,写入一个“检查点”(checkpoint)或者...
2年前 (2022-12-23) 1615℃
0喜欢
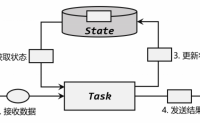
状态的概念
在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
什么场景会用到状态,下面列举了三种场景:
去重:比如上游的系统数...
2年前 (2022-12-23) 1483℃
0喜欢
窗口的概念
我们知道Flink是一个可以处理无限流的流式处理引擎,无限流有个特点就是数据无休无止,源源不断,这种情况下要是想做统计聚合的话,就没有数据的尽头,因为数据在一直不停的更新。
在这种情况下,业务就想看之前一个小时或者一天的数据,就需要人为的给无界流增加一个界限,一个范围...
2年前 (2022-12-20) 2621℃
5喜欢