简介
每一个微服务在部署以后,我们都需要对其进行监控、追踪、审计、控制等。 Spring Boot就提供了Actuator场景,使得我们的应用快速引用即可获得生产级别的应用监控、审计等功能。
Spring Boot Actuator是一个用于监控和管理Spring Boot应用程...
1年前 (2023-06-14) 3496℃
4喜欢
简介
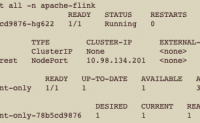
flink native k8s就是使用flink 自有的命令来提交作业到k8s集群的,需要提前下载好flink安装包
实际生产中使用flink on k8s推荐使用flink kubernetes operator的方式,flink native k8s还不是很成熟,坑略...
1年前 (2023-06-06) 2730℃
1喜欢
简介
传统的存算一体架构具有数据本地化的先天性能优势,而采用存算分离之后,由于所有的数据读写都要通过网络进行,因此就失去了数据本地化的性能优势。为了解决这个问题,会在计算和存储之间引入新的分布式缓存组件,例如Juice FS和Alluxio,以进一步提升数据的读写性能。
Juic...
1年前 (2023-06-05) 79℃
3喜欢
简介
Spark Shuffle通常是在RDD宽依赖的情况下发生,是上游Stage和下游Stage之间传递数据的一种机制。shuffle阶段通常会伴随中间数据的落盘(数据量不大的情况下也可以不落盘而是全部保存在内存中),shuffle的性能高低直接影响了整个Spark程序的性能和...
1年前 (2023-06-05) 2167℃
0喜欢
简介
在实际工作中,绝大多数的离线数仓,批处理作业,都是使用SQL脚本开发的,通过SQL语句实现处理的逻辑。得益于spark的优良性能,尤其是在spark 3.0之后,spark sql的性能有了大幅度的提升。目前在绝大多数的公司的数仓团队中,都是通过spark sql来开发批处...
1年前 (2023-06-05) 980℃
0喜欢
简介
在Spark On K8s场景下, 涉及计算资源的设置, 除了driver.cores、 executor.cores、 driver.memory 和executor.memory这4个Spark自有的参数外, 还会受到K8s对资源控制的影响, 例如k8s request...
1年前 (2023-06-05) 70℃
1喜欢
简介
元数据checkpoint主要用于Spark Streaming场景,以便Driver从故障中快速恢复任务的DAG和状态数据; 而RDD checkpoint主要是对有状态转换算子的数据做持久化,以切断依赖链,缩短Spark程序恢复时间 在Spark On K8s环境下,c...
1年前 (2023-06-05) 1680℃
0喜欢
简介
Spark 支持使用Pod Template文件定义Driver和Executor的Pod规格信息,在Pod Template中可以使用Kubernetes原生支持的语法,这样不仅可以极大简化spark-submit的参数数量,而且可以在Pod Template中添加spa...
1年前 (2023-06-05) 625℃
0喜欢
简介
在之前的案例中,spark 作业退出之后,所有的内容都销毁了,如果要对之前运行的程序进行调试和优化,是没有办法查询的,这个时候就有必要部署Spark History Server了。Spark History Server是一个非常重要的工具,可以帮助用户管理和监控 Spa...
1年前 (2023-06-05) 1944℃
0喜欢
简介
容器化是当前甚至未来一段时间内计算机提供资源的主流方式,当下的云原生就是有力的例证。在这种趋势引领下大数据也会走向容器化,容器化也就意味着存算分离。
大数据主要提供海量数据的存储和海量数据的计算这两大类的能力,简单来讲大数据存算分离就是将提供存储的组件和提供计算的组件从物理...
1年前 (2023-06-05) 88℃
2喜欢